






























































The term Big Data and the name Hadoop are bandied about freely in computer circles. In this article, the author attempts to explain them in very simple terms.
Imagine this scenario: You have 1GB of data that you need to process. The data is stored in a relational database in your desktop computer which has no problem managing the load. Your company soon starts growing very rapidly, and the data generated grows to 10GB, and then 100GB. You start to reach the limits of what your current desktop computer can handle. So what do you do? You scale up by investing in a larger computer, and you are then alright for a few more months.
When your data grows from 1TB to 10TB, and then to 100TB, you are again quickly approaching the limits of that computer. Besides, you are now asked to feed your application with unstructured data coming from sources like Facebook, Twitter, RFID readers, sensors, and so on. Your managers want to derive information from both the relational data and the unstructured data, and they want this information as soon as possible. What should you do?
Hadoop may be the answer. Hadoop is an open source project of the Apache Foundation. It is a framework written in Java, originally developed by Doug Cutting, who named it after his son’s toy elephant!
Hadoop uses Google’s MapReduce technology as its foundation. It is optimised to handle massive quantities of data which could be structured, unstructured or semi-structured, using commodity hardware, i.e., relatively inexpensive computers. This massive parallel processing is done with great efficiency. However, handling massive amounts of data is a batch operation, so the response time is not immediate. Importantly, Hadoop replicates its data across different computers, so that if one goes down, the data is processed on one of the replicated computers.
Big Data
Hadoop is used for Big Data. Now what exactly is Big Data? With all the devices available today to collect data, such as RFID readers, microphones, cameras, sensors, and so on, we are seeing an explosion of data being collected worldwide. Big Data is a term used to describe large collections of data (also known as data sets) that may be unstructured, and grow so large and so quickly that it is difficult to manage with regular database or statistical tools.
In terms of numbers, what are we looking at? How BIG is Big Data? Well there are more than 3.2 billion Internet users, and active cell phones have crossed the 7.6 billion mark. There are now more in-use cell phones than there are people on the planet (7.4 billion). Twitter processes 7TB of data every day, and 600TB of data is processed by Facebook daily. Interestingly, about 80 per cent of this data is unstructured. With this massive amount of data, businesses need fast, reliable, deeper data insight. Therefore, Big Data solutions based on Hadoop and other analytic software are becoming more and more relevant.
Open source projects related to Hadoop
Here is a list of some other open source projects related to Hadoop:
- Eclipse is a popular IDE donated by IBM to the open source community.
- Lucene is a text search engine library written in Java.
- Hbase is a Hadoop database – Hive provides data warehousing tools to extract, transform and load (ETL) data, and query this data stored in Hadoop files.
- Pig is a high-level language that generates MapReduce code to analyse large data sets.
- Spark is a cluster computing framework.
- ZooKeeper is a centralised configuration service and naming registry for large distributed systems.
- Ambari manages and monitors Hadoop clusters through an intuitive Web UI.
- Avro is a data serialisation system.
- UIMA is the architecture used for the analysis of unstructured data.
- Yarn is a large scale operating system for Big Data applications.
- MapReduce is a software framework for easily writing applications that process vast amounts of data.
Hadoop architecture
Before we examine Hadoop’s components and architecture, let’s review some of the terms that are used in this discussion. A node is simply a computer. It is typically non-enterprise, commodity hardware that contains data. We can keep adding nodes, such as Node 2, Node 3, and so on. This is called a rack, which is a collection of 30 or 40 nodes that are physically stored close together and are all connected to the same network switch. A Hadoop cluster (or just a ‘cluster’ from now on) is a collection of racks.
Now, let’s examine Hadoop’s architecture—it has two major components.
1. The distributed file system component: The main example of this is the Hadoop distributed file system (HDFS), though other file systems like IBM Spectrum Scale, are also supported.
2. The MapReduce component: This is a framework for performing calculations on the data in the distributed file system.
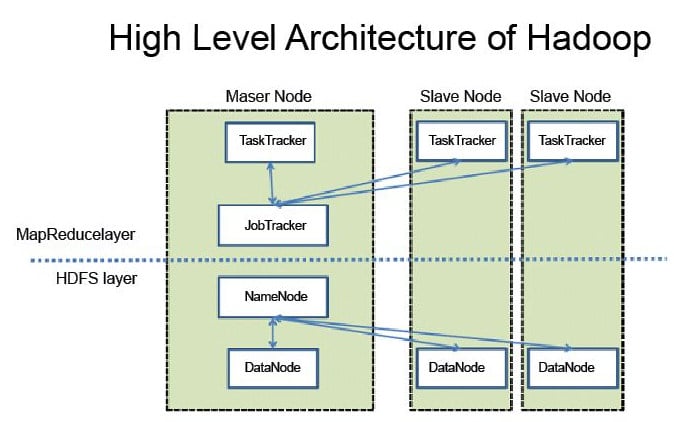
HDFS runs on top of the existing file systems on each node in a Hadoop cluster. It is designed to tolerate a high component failure rate through the replication of the data. A file on HDFS is split into multiple blocks, and each is replicated within the Hadoop cluster. A block on HDFS is a blob of data within the underlying file system (see Figure 1).
Hadoop distributed file system (HDFS) stores the application data and file system metadata separately on dedicated servers. NameNode and DataNode are the two critical components of the HDFS architecture. Application data is stored on servers referred to as DataNodes, and file system metadata is stored on servers referred to as NameNodes. HDFS replicates the file’s contents on multiple DataNodes, based on the replication factor, to ensure the reliability of data. The NameNode and DataNode communicate with each other using TCP based protocols.
The heart of the Hadoop distributed computation platform is the Java-based programming paradigm MapReduce. Map or Reduce is a special type of directed acyclic graph that can be applied to a wide range of business use cases. The Map function transforms a piece of data into key-value pairs; then the keys are sorted, where a Reduce function is applied to merge the values (based on the key) into a single output.
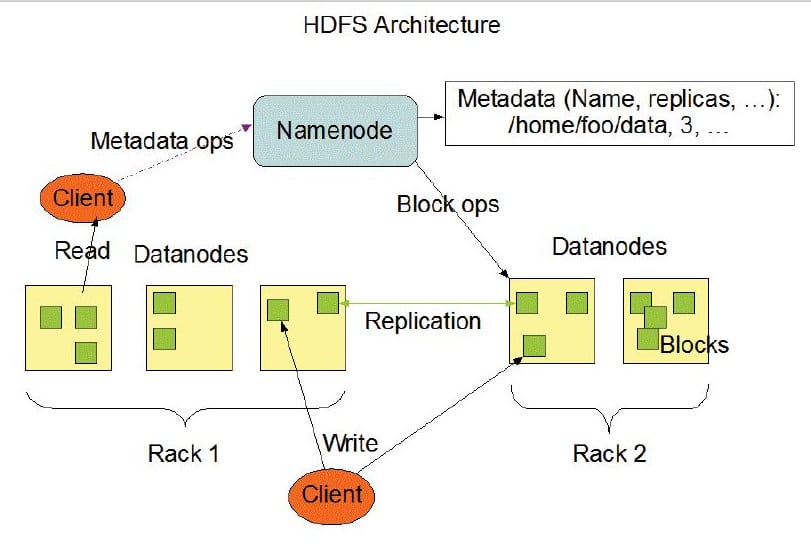
Resource Manager and Node Manager
The Resource Manager and the Node Manager form the data computation framework. The Resource Manager is the ultimate authority that arbitrates resources among all the applications in the system. The Node Manager is the per-machine framework agent that is responsible for containers, monitoring their resource usage (CPU, memory, disk and network), and reports this data to the Resource Manager/Scheduler.
Why Hadoop?
The problem with a relational database management system (RDBMS) is that it cannot process semi-structured data. It can only work with structured data. The RDBMS architecture with the ER model is unable to deliver fast results with vertical scalability by adding CPU or more storage. It becomes unreliable if the main server is down. On the other hand, the Hadoop system manages effectively with large-sized structured and unstructured data in different formats such as XML, JSON and text, at high fault tolerance. With clusters of many servers in horizontal scalability, Hadoop’s performance is superior. It provides faster results from Big Data and unstructured data because its Hadoop architecture is based on open source.
What Hadoop can’t do
Hadoop is not suitable for online transaction processing workloads where data is randomly accessed on structured data like a relational database. Also, Hadoop is not suitable for online analytical processing or decision support system workloads, where data is sequentially accessed on structured data like a relational database, to generate reports that provide business intelligence. Nor would Hadoop be optimal for structured data sets that require very nominal latency, like when a website is served up by a MySQL database in a typical LAMP stack—that’s a speed requirement that Hadoop would not serve well.















