






























































Microservices is an architectural style for building applications that are structured into several loosely coupled services. An API gateway acts as a single entry point into the system. This article, aimed at developers who work in API, mobile and Web development, explains how the two can be used in tandem.
An API gateway is a management tool to create, publish, maintain, monitor and secure APIs. You can create APIs that carry out a specific function of your logic or that can access other Web services.
To understand this better, consider the following example. We are building a client for a shopping application and need to implement a ‘Product details’ page, which displays information about any given product.
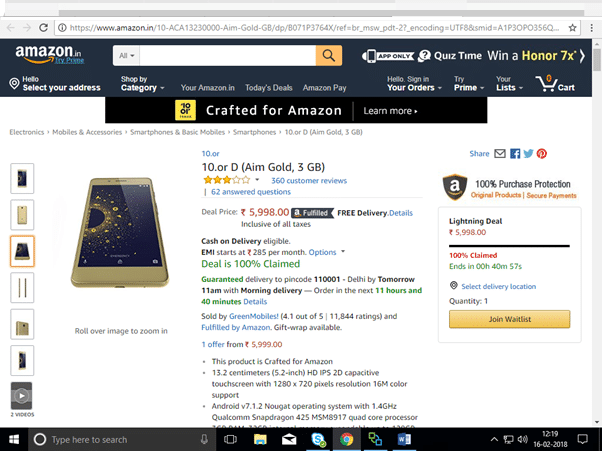
Figures 1(a), 1(b) and 1(c) show what you will see when scrolling through the ‘Product details’ page in any shopping site (this one is from Amazon). The page also shows other information, which includes:
- Selected product information
- Order history
- Cart
- Reviews of the product
- Inventory and shipping
- Various recommendations, including other products frequently purchased with this product, and so on.
Monolithic architecture
The program (in any language or framework) for this can be developed using a monolithic architecture. This is nothing but a traditional unified model for the design of a software program. In this context, monolithic means all the components are interconnected and interdependent, rather than loosely coupled. In this tightly coupled architecture, all the components should be present in a single package/code base for the page to be rendered. In our example, a client would retrieve this data by making a single REST call (GET, api.company.com/products/productId) in the application. A load balancer or a cluster may route the request to one of N application instances. The application then queries various database tables and returns the response to the client.
The advantage of this design is that the various functionalities like logging, audit trails, middleware, etc, are all hooked to one app wherein any changes, corrections and optimisations can be done easily. One more advantage is that shared memory is faster than inter-process communication (IPC).
In spite of the advantages, there are many concerns in this pattern. As components are tightly coupled it is difficult to isolate services for any purpose such as independent scaling or code maintainability. The components become much harder to understand in the long run as the code base grows in size and is not obvious when looking at a particular service or controller. Down the line, the application is sure to go out of control; so this is not a good idea.
Microservice architecture
This design uses small, modular units of code that can be deployed independent of the rest of the product’s components. An application is a collection of loosely coupled services and each service is fine grained, thus improving modularity and making the application easier to understand, as well as faster to develop, test and deploy.
- Microservices components are modular, so each service can be built, updated and deployed independent of any other code.
- Each microservice is responsible for a specific purpose or task.
- Each service abstracts away implementation details, exposing only a well-documented interface; so APIs can be consumed in a consistent way, regardless of how exactly the service is built.
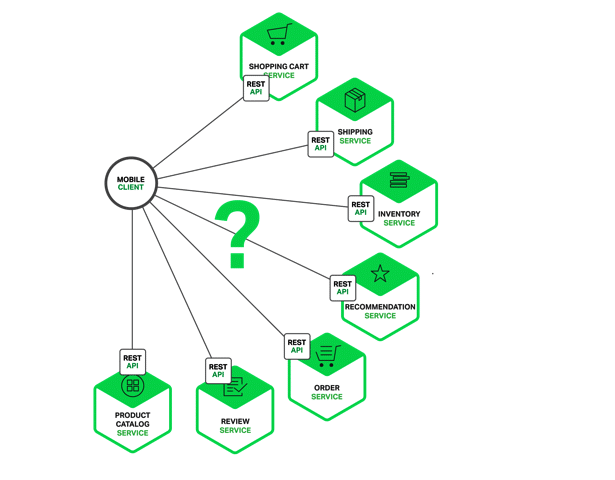
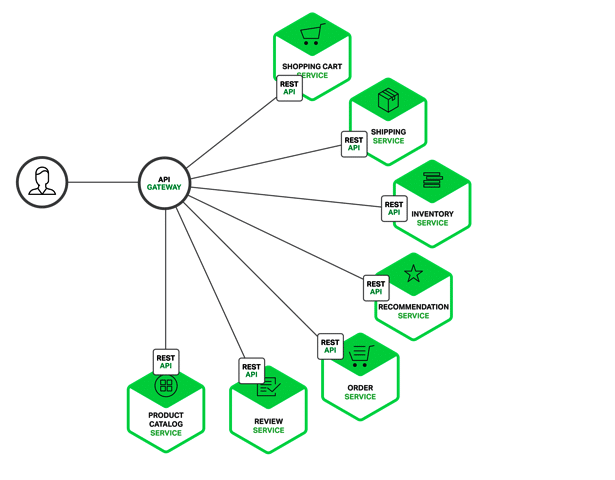
In our shopping application, the data displayed on the ‘Product details’ page is from multiple microservices. Some of the potential microservices are:
- Shopping cart service
- Catalogue service
- Review service
- Shipping service
- Recommendation service
In theory, a client could make a request to each of the microservices, directly. Each service can have an end point like http://service.api.company.com. This URL would map to the microservice’s load balancer, which distributes requests across the available instances. To retrieve the product details, the mobile client would make requests to each of the requests listed above.
Unfortunately, there are some challenges and difficulties with this option. One problem is the mismatch between the client and the fine grained APIs exposed. In this example, the client has to make seven separate requests for a page. In a complex application, hundreds of services may be involved in a page, and this would probably prove inefficient over a public network and quite impossible over a mobile network.
Another hurdle with the client directly calling the microservices is that it might use a protocol that may not be Web-friendly. One service may use RPC and another the AMQP messaging protocol. Neither of them is browser- or firewall-friendly, and both are best suited internally. An application should use only HTTP and Web Socket outside of the firewall.
Yet one more drawback with this approach of the client calling the microservices is that it is difficult to refactor the services. Over time, there might be a requirement to merge two services or split a service into two or more parts. If the client communicates directly, performing this kind of refactoring will be extremely difficult.
When an API gateway comes into the picture
A much better approach would be to use what is known as an API gateway. This is a single entry point to the system. It encapsulates the internal architecture and provides the service tailored to each client. It might also have other responsibilities that include authentication, monitoring, logging, caching, static response handling, etc.
An API gateway is responsible for request routing, composition and protocol translation. All the requests from the client go through an API gateway. It then routes requests to the appropriate microservice. The API gateway will often handle a request by invoking multiple microservices and then aggregate the results. It can translate between Web-friendly and Web-unfriendly protocols.
Here, in our example, the API gateway can provide an endpoint like /products/productId=xxx that enables a client to retrieve all the product information (as well as other details) in a single request. In our case, the API gateway handles this request by invoking the various services like shipping, the recommendation service, reviews, etc.

Benefits and drawbacks
As you might expect, using an API gateway comes with both benefits and disadvantages. A major benefit is that it encapsulates the whole internal structure. Since rather than calling various services individually, clients call the API gateway, this reduces the number of round trips between the client and the application, and hence simplifies the client code.
On the down side, this is yet another component that must be developed, deployed and managed. Developers must update the gateway in order to expose each microservice endpoint. The process of updating should be lightweight. Otherwise, developers will be forced to wait in queue to update their service, which in turn may affect the business.
Despite these drawbacks, for most (almost all) real-world applications, it makes sense to use an API gateway.
Implementation
Let’s look at the various design issues to consider when implementing an API gateway.
Performance and scalability: Only a handful of companies need to handle billions of requests per day. In any case, the performance and scalability of an API gateway is more important as this is the entry point. It is therefore necessary to build the API gateway on a platform that supports asynchronous and non-blocking I/O.
Service invocation: As this is a distributed system, it must use an inter-process communication mechanism. There are two styles of IPC. One option is to use an asynchronous, message-based mechanism like JMS or AMQP. Another option is to use any synchronous mechanism such as HTTP.
Service discovery: The API gateway has to know the location of all microservices it needs to communicate with. Infrastructure services such as message brokers will have a static location. An API gateway can use two ways to determine the location—server side discovery and client side discovery. It is beyond the scope of this article to get into the details of these two types of discovery; yet, if the system uses client side discovery, the API gateway must be able to query the service registry to determine any service location.
Handling failures: This issue can arise in almost all distributed systems when one service calls another service that is responding slowly or is unavailable. For example, if the recommendation service is unresponsive in our Product details scenario, the API gateway should be able to serve the rest of the product details as they are still useful to the client. An unresponsive service can be returned by any default response.
The API gateway could also return cached data if it is available. An example is the product prices, for which changes are not frequent. Prices can be cached in the API gateway itself, in Redis or Memcached. By returning either default data or cached data, the gateway ensures that system failure does not affect the user experience.
For most microservices based applications, the API gateway, which acts as a single entry point, is an ideal solution. The gateway can also mask failures in the backend services, improve service messaging, as well as abstract some of the complexities and details of the microservice architecture.
Kong is a popular open source API gateway. NGINX Plus, Red Hat and 3scale each offer a free trial.

















{kind=link}