






























































This article clarifies the role of data science in relation to machine learning, and discusses various aspects of both.
Google is now a synonym for online search. Most of us will agree with this, because whenever we try to get information on something we don’t know, we say, “Google it!” Have you ever given a thought to how Google comes up with the answers to different questions in an instant? Google and other such search engines make use of different data science algorithms and machine learning techniques to come up with the best results for all our search queries, and that too, in less than a second. Google processes more than 20 petabytes of structured and unstructured data daily and, even then, is able to instantly flash our search results. Had there been no data science and machine learning, Google would not have been able to perform all this and it would not have been the all-pervasive search engine we all depend on today. Data science is one of the roots that support the tree of the digital world.
Data science is also known as data-driven science as it deals with various scientific processes, methods and systems to extract knowledge or insights from large sets of data — either unstructured or structured. We all have access to huge amounts of data, which is about many aspects of our lives – it could be related to communication, shopping, reading the news, searching for information, expressing our opinions, etc. All this is being used to extract useful insights by employing different data science techniques. Data science is basically a concept that unifies statistics with data analysis in order to analyse and relate real world activities with data. It employs different techniques and theories that are drawn from many fields — from within the broad areas of statistics, mathematics, information science and computer science, besides the various sub-domains of machine learning, cluster analysis, classification, databases, data mining and visualisation.
According to the Turing Award winner Jim Gray, data science is the fourth paradigm of science. Gray asserts that everything about science is rapidly changing because of the impact of information technology and the data deluge. Data science plays a crucial role in transforming the information collected during datafication and adds a value to it. Datafication is nothing but the process of taking different aspects of life and turning these to data. For instance, Twitter datafies different stray thoughts, LinkedIn datafies the professional networks, and so on. We take the help of different data science techniques to extract useful parts out of the collected information during datafication.
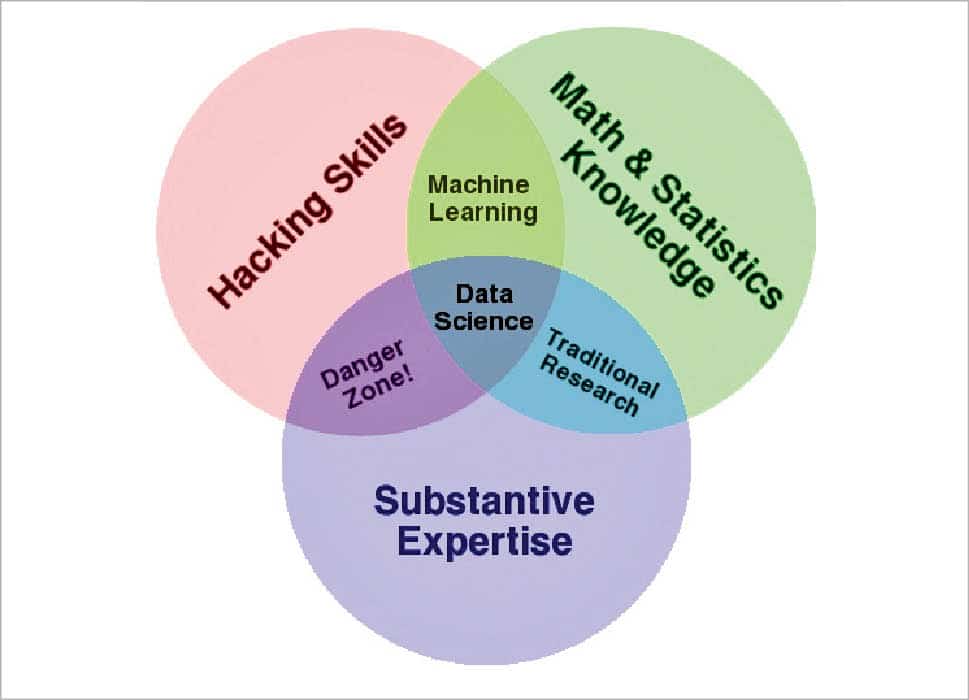
Drew Conway is famous for his Venn diagram definition of data science. He applied it to study and analyse one of the biggest problems of the globe –terrorism. If we take a look at his Venn diagram definition, data science is the union of hacking skills, statistical and mathematical knowledge, and substantive expertise about the specific subject. According to him, data science is the civil engineering of data. It requires a practical knowledge of different tools and materials, coupled with a theoretical understanding of what’s possible.
The workflow for data science
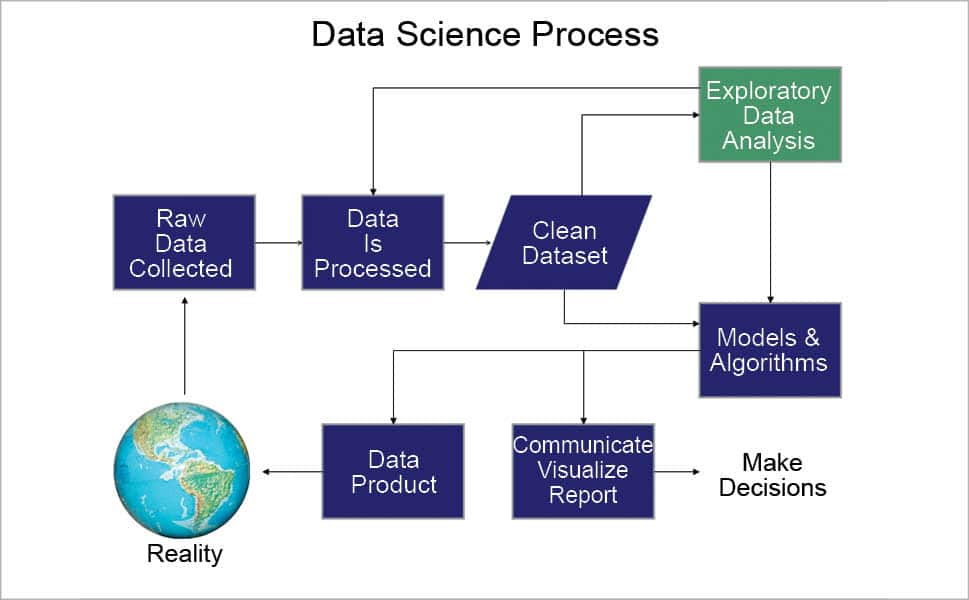
Data science comprises several sequences of processes which are followed to deduce useful insights from the raw set of data. This ultimately helps the system to make decisions. Let us have a look at the different processes followed in data science.
Collection of raw data: This is the first step implemented in data science and deals with the collection of actual raw data, on which different data science operations need to be performed. There are broadly two ways to do this:
1. We can pick one or many tools to collect data automatically from different data sources. This option is widely used in order to collect data from large data sources. We just need to copy-paste a small code snippet into our website and we are ready to go (e.g., Hotjar, Google Analytics, etc).
2. We can also collect the data for ourselves using a JavaScript code snippet that sends the data in a .csv plain text file on the server. This is a bit difficult to implement as it requires some coding skills. But if we think about the long term, this solution is more profitable.

Data processing: This refers to the refinement of raw data that has been collected during the data collection process. We all know that the raw data is unprocessed and unorganised. It needs to be arranged and organised so that it becomes easier to perform operations on it. Once the data is processed, we get an output data which is the processed, categorised and summarised version. Data processing is required in most of the experiments and surveys. The collected raw data sometimes contains too much data to analyse it sensibly. This is especially the case when we do research using computers as this may produce large sets of data. The data then needs to be organised or manipulated using the deconstruction technique.
Data set cleaning: This is the process of removing unwanted data from the processed data set and keeping only what’s required for analysis. This helps to reduce the large set of data to a smaller one by removing the inconsistent or incorrect data, and makes it easier to perform different analysis tasks on it.
Exploratory data analysis: This approach is used to analyse the data sets in order to summarise their important characteristics, often with the help of visual methods. A statistical model can also be used for analysis, but primarily, exploratory data analysis is for visualising what the data can tell us beyond the formal modelling or the hypothesis testing task. This approach was promoted by John Tukey to encourage different data scientists to explore the data, and hence possibly formulate the hypotheses that could lead to new methods of data collection and experiments. This is different from the initial data analysis, which focuses mostly on checking the assumptions required for model fitting, the hypothesis testing, the handling of different missing values and making transformations of variables as required.
Models and algorithms: Once the data is cleansed, some sets of data will need exploratory analysis whereas other sets can be directly used for the selection of data models and algorithms. This phase of data science deals with the process of selecting the right and appropriate algorithm on the basis of the data set obtained after data cleaning, and also on the basis of the knowledge obtained about the data set during exploratory data analysis. The algorithm chosen is such that it’s most efficient for the available data set. This process also includes the design, development and selection of the data models, which can be used to perform the required operations on the data, to obtain the required data product.
Report communication: This is the part of data science that deals with generating and developing visual reports in the form of graphs and pie-charts, which can be used by data scientists to analyse the data patterns and make the appropriate decisions. This decision is the final output, which is then utilised in different applications.
Data product: This is the final data product, which is used to continuously improve and change the application system whose data is analysed. This can be considered as the end product, which represents the whole set of operations performed on the collected raw data set.
What is machine learning?
Machine learning is a part of computer science that gives any system the ability to learn on its own without being programmed. It makes a machine learn in the same way as human beings learn by themselves. Just as we learn any system on the basis of our experience and the knowledge gained after analysing the system, even machines can analyse and study the system’s behaviour or its output data and learn how to take decisions on that basis. This is the backbone of artificial intelligence. It makes machines get into a self-learning mode without any explicit programming. When the machine is fed with new data, it learns, grows and changes by itself.
Machine learning has evolved from the concept of pattern recognition and computational learning theory in artificial intelligence. It explores the study and construction of different algorithms that can learn from data and make predictions on them. These algorithms do not follow the static program instructions, but make data-driven predictions or decisions by building a model from some sample inputs.
There are three types of machine learning, differentiated on the basis of the learning signal available to any learning system.
1. Supervised learning: In this type of learning, the machine is presented with few example inputs and also their desired outputs, which are given by a teacher. The goal is to learn a general rule that maps inputs to outputs.
2. Unsupervised learning: This is a type of machine learning in which no labels are given to the learning algorithm, leaving it to find the structure in its input on its own.
3. Reinforcement learning: Under this learning system, a computer program actually interacts with a dynamic environment for which it must perform a specific goal (for example, driving a vehicle or playing a game against an opponent).
How is machine learning related to data science?
Machine learning is very closely related to (and sometimes overlaps with) data science or computational statistics, as both focus on making predictions with the help of machines or computers. It has strong ties with mathematical optimisation, which provides different methods and theories to optimise learning systems. Machine learning is often combined with data science, with the latter actually focusing more on exploratory data analysis, and this is known as unsupervised learning.
If we talk specifically about the field of data science, machine learning is used to devise various complex models and algorithms that lend themselves to prediction. This is also known as predictive analytics. All these analytical models allow data scientists, researchers, engineers and analysts to produce reliable and repeatable decisions in order to uncover various hidden insights by learning from the historical relationships and trends in the large sets of data.
Data analysis has been traditionally characterised by the trial and error approach, and we all know that this becomes impossible to use when there are large and heterogeneous sets of data to be analysed. The availability of large data is directly proportional to the difficulty of developing new predictive models that work accurately. All the traditional statistical solutions work for static analysis, which is limited to the analysis of samples frozen in time. Machine learning has emerged as a solution to all this chaos, proposing different clever alternatives to analyse huge volumes of data. It is able to produce accurate results and analyses by developing various efficient and fast working algorithms for the real-time processing of data.
Some applications of machine learning
Machine learning has been implemented in a number of applications. Some of them are:
1. Google’s self-driving car
2. Online recommendation engines such as friend recommendation on Facebook
3. Various offer recommendations from Amazon
4. Cyber fraud detection
5. Optical character recognition (OCR)
The role of machine learning in data science
1. Machine learning helps to analyse large chunks of data easily and hence eases the work of data scientists in an automated process.
2. Machine learning has changed the way data interpretation and extraction works by involving several automatic sets of generic methods, which have replaced statistical techniques.
3. It provides insights that help to create applications that are more intelligent and data-driven, and hence improves their operation and business processes, leading to easier decision making.
4. Machine learning software systems improve their performance more and more, as people use them. This occurs because the algorithms used in them learn from the large set of data generated on the basis of the users’ behaviour.
5. It helps in inventing new ways to solve some sudden and abrupt challenges in the system, on the basis of the experience gained by the machine while analysing the large data sets and behaviour of the system.
6. The increasing use of machine learning in industries acts as a catalyst to make data science increasingly relevant.
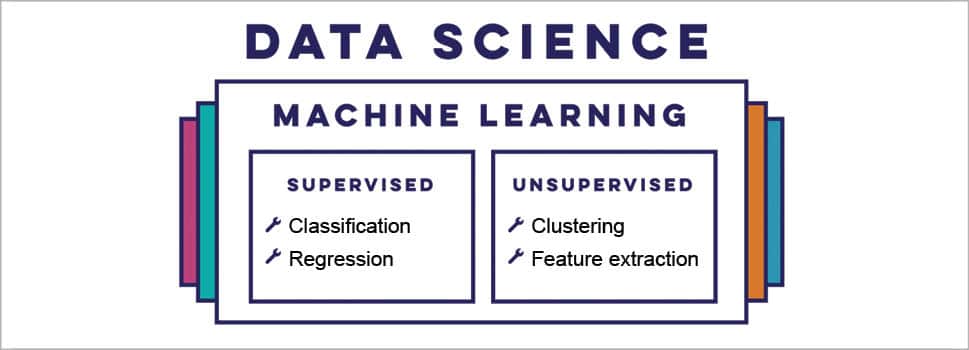
Some of the machine learning techniques used in data science
1. Decision tree learning: This is a machine learning technique that uses a decision tree as the predictive model, which further maps observations about an item to the conclusions about the target value of the item.
2. Association rule learning: This is a method used for discovering several interesting relations between the variables in large databases.
3. Artificial neural networks: Such learning techniques are also called neural networks. These are learning algorithms that are inspired by the structure and functional aspects of biological neural networks. Different computations are actually structured in terms of interconnected groups of artificially designed neurons, which help to process information using the connectionist approach to computation. All the modern neural networks are basically non-linear statistical tools used for data modelling. They are usually used to model several complex relationships between the inputs-outputs and to find patterns in the data.
4. Inductive logic programming (ILP): This approach uses logical programming as a representation for several input examples, the background knowledge and the hypotheses. If we are given an encoding of any known background knowledge with a set of examples, which represent a logical database of facts, then an ILP system will easily derive a hypothesised logic program which entails all the positive and no negative examples. This type of programming considers any type of programming language for representing the hypotheses, such as functional programs.
5. Clustering: Cluster analysis is a technique used for the assignment of a set of different observations into various subsets (also called clusters) so that the observations present within the same cluster are similar to some pre-designated criteria, whereas the observations drawn from all the different clusters are dissimilar. All the different clustering techniques have different assumptions on the structure of data, which is often defined by some similarity metric and is evaluated, for example, by internal compactness and the separation between different clusters. It is basically an unsupervised learning method and one of the common techniques used for statistical data analysis.
6. Bayesian networks: A Bayesian network is a probabilistic graphical model which represents a set of random variables and all their conditional independencies using a directed acyclic graph. For instance, a Bayesian network can represent the probabilistic relationships between different diseases and their symptoms. If we are given the symptoms, then the network can easily compute the probabilities of the presence of various diseases. Very efficient algorithms are used to perform the inference and learning.
7. Reinforcement learning: This is a technique related to how an agent ought to take different actions in an environment in order to maximise some notion of the long-term reward. This type of algorithm attempts to find a policy that maps different states of the world to the different actions the agent ought to take in those states. This type of learning differs from the supervised learning problem, for which correct input/output pairs are not presented, nor are the sub-optimal actions explicitly corrected.

















{kind=link}