






























































Natural Language processing (NLP) is an area of computer science and artificial intelligence that is related to the interactions between computers and human (natural) languages. It deals with how computers are programmed to fruitfully process large amounts of natural language data in order to perform useful tasks. The National Language Tool Kit (NLTK) is a library that facilitates experimentation with data related to NLP.
It was in the beginning of the 21st century that Steven Bird, Edward Loper and Ewan Klein from the University of Pennsylvania released a Python natural language processing library suite – the Natural Language Toolkit (NLTK). This library provides a platform to play around with data related to natural language processing (NLP), and simplifies NLP tasks such as text classification, parts of speech tagging, syntactic parsing, tokenisation and stemming.
Installation
NLTK is available for use in Windows, Linux and Mac OS. Aptitude can be used for installation in Linux, as follows:
sudo apt install python-nltk
Pip, a package manager to install and manage packages written in Python, can also be used in all operating systems to install NLTK. The command:
sudo pip install nltk
…will do the job.
Once you have installed NLTK successfully, you need to import the modules to use the functions provided by it. The following command can be used for the task:
import nltk
All the packages and corpuses supplied by NLTK can be downloaded once for later use by running the following command in the Python interpreter:
nltk.download()
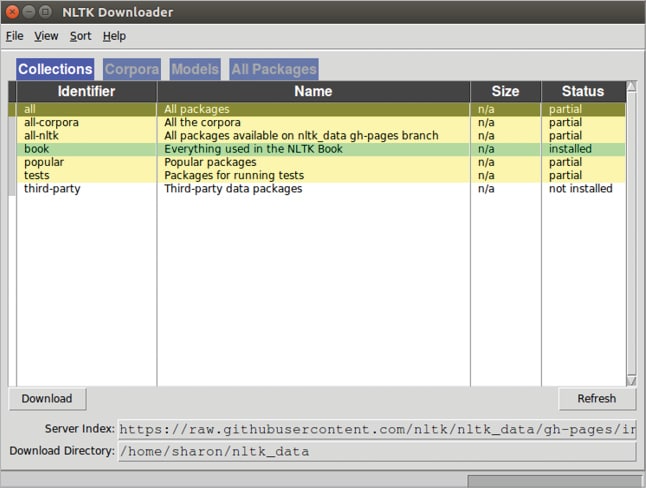
Calling the download() function will cause the popping-up of the NLTK downloader. All but those versions lower than 0.9.5 of NLTK will support this operation. Figure 1 shows the NLTK downloader. It helps to install packages or corpuses by selecting the package from the list and clicking on the ‘Download’ button.
If Tkinter is not available in the system, a text interface may be provided by the NLTK downloader. As you can see in Figure 1, NLTK Book is installed in my system. The following command will import all the downloaded books:
>>> from nltk.book import * *** Introductory Examples for the NLTK Book *** Loading text1, ..., text9 and sent1, ..., sent9 Type the name of the text or sentence to view it. Type: ‘texts()’ or ‘sents()’ to list the materials. text1: Moby Dick by Herman Melville 1851 text2: Sense and Sensibility by Jane Austen 1811 text3: The Book of Genesis text4: Inaugural Address Corpus text5: Chat Corpus text6: Monty Python and the Holy Grail text7: Wall Street Journal text8: Personals Corpus text9: The Man Who Was Thursday by G . K . Chesterton 1908
We can see that nine text books and nine sentences are imported with a single statement.
Creating NLTK Book
Users can create their own NLTK Book. The content of a text file, a.txt, is given below:
“Natural language processing (NLP) is an area of computer science and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to fruitfully process large amounts of natural language data. Challenges in natural language processing frequently involve speech recognition, natural language understanding and natural language generation.”
This can be generated as an NLTK text book using the statements given below:
>>> f1=open('a.txt','rU')
>>> txt=f1.read()
>>> token = nltk.word_tokenize(txt)
>>> nlp = nltk.Text(token)
>>> nlp
<Text: Natural-language processing ( NLP ) is an area...>
A text with the name ‘nlp’ is generated. Here, the file a.txt is opened in the rU mode, i.e., reading in universal newline mode. By opening a file in this mode, we make sure that newline characters in other platforms can also be supported by the platform on which Python is running. The use of the word_tokenize() function will be described later in this article.
The type of an NLTK Book can be obtained with the following statement:
>>>type(nlp) <class ‘nltk.text.Text’>
One article is not enough to explain everything about NLTK. Some of the NLP tasks that can be performed with it are explained below.
Tokenisation
The input text needs to be broken down into basic linguistic units before applying some transformations. Tokenisation is the process of splitting a stream of characters into meaningful entities, called tokens. This splitting can be done sentence-wise or word-wise. A sentence boundary can be detected with the help of the sent_tokenize tool in NLTK. An example is shown below:
>>> a=’hi sharon. how are you? revert me to sharon@gmail.com’ >>> nltk.sent_tokenize(a) [‘hi sharon.’, ‘how are you?’, ‘revert me to sharon@gmail.com’]
It is a sophisticated task to distinguish between the ‘.’ (the full stop) at the end of sentences and the one that appears in the mail ID!
Word boundaries can be detected easily with the help of word_tokenize(). The result after word tokenisation of ‘a’ is given below:
>>> b=nltk.word_tokenize(a) >>> b [‘hi’, ‘sharon’, ‘.’, ‘how’, ‘are’, ‘you’, ‘?’, ‘revert’, ‘me’, ‘to’, ‘sharon’, ‘@’, ‘gmail.com’]
Parts of speech tagging
Identifying the parts of speech associated with each word is a natural language processing task. Once the input is tokenised, POS tagging can be done on it. If the input is not tokenised before POS tagging, each character in the input will be POS tagged, which may not be an acceptable output.
>>> nltk.pos_tag(b) [(‘hi’, ‘NN’), (‘sharon’, ‘NN’), (‘.’, ‘.’), (‘how’, ‘WRB’), (‘are’, ‘VBP’), (‘you’, ‘PRP’), (‘?’, ‘.’), (‘revert’, ‘VB’), (‘me’, ‘PRP’), (‘to’, ‘TO’), (‘sharon’, ‘VB’), (‘@’, ‘NNP’), (‘gmail.com’, ‘NN’)]
Here, NN stands for noun, WRB for wh-adverb and VBP for present tense verb. Explaining the meaning of all POS tags is beyond the scope of this article. The following command will give details about all the Pen TreeBank POS tags:
>>> nltk.help.upenn_tagset()
Stemming and lemmatisation
Words take different inflections in different contexts; e.g., ‘wonder’, ‘wonderful’ and ‘wondering’ are inflections of the word ‘wonder’. Words can also take derivational forms like ‘diplomacy’, ‘diplomatic’, etc. Stemming is the process of reducing inflected or sometimes derived words to their root form, which can be used to generate words by suffix concatenation. The stemming algorithm works by removing common prefixes and suffixes from the given input. NLTK provides interfaces for the Porter stemmer, Snowball stemmer, Lancaster stemmer, etc. The following statements illustrate the use of the Porter stemmer:
>>> from nltk.stem.porter import * >>> stemmer = PorterStemmer() >>> stemmer.stem(‘wondering’) u’wonder’
Lemmatisation is the process of converting input into its dictionary form called lemma. It involves morphological analysis of the input. NLTK’s lemmatiser works on the basis of WordNet, a database of English. The use of the WordNet lemmatiser is shown below:
>>> from nltk.stem import WordNetLemmatizer >>> lemmatizer = WordNetLemmatizer() >>> lemmatizer.lemmatize(‘wolves’) u’wolf’ >>> lemmatizer.lemmatize(‘is’) ‘is’ >>> lemmatizer.lemmatize(‘are’) ‘are’
We can see in the above example that ‘is’ and ‘are’ are not lemmatised to their base form ‘be’. This is because the default POS argument of lemmatize() is ‘n’ ( ‘n’ stands for noun). To change the output, specify the POS argument ‘v’.
>>> lemmatizer.lemmatize(‘are’,pos=’v’) u’be’ >>> lemmatizer.lemmatize(‘is’,pos=’v’) u’be’
We can see that result after stemming and lemmatisation are in Unicode format, which is indicated by ‘u’.
Other data processing tasks
Apart from tasks like tokenisation, lemmatisation, etc, NLTK can also be used in tasks like finding words that are longer than a specified value, the frequency of characters, searching text, sorting the contents of a book, etc. Some of these tasks are explained below.
Frequency of occurrences: The FreqDist() function accepts iterable tokens. Since character-by-character iteration is possible in strings, the application of this function on strings yields the frequency distribution of all characters in that string. An example is shown below:
>>>a=’hi this is sharon’
>>> nltk.FreqDist(a)
FreqDist({‘ ‘: 3, ‘i’: 3, ‘h’: 3, ‘s’: 3, ‘a’: 1, ‘o’: 1, ‘n’: 1, ‘r’: 1, ‘t’: 1})
You can see that the result is a dictionary. The frequency distribution of a particular character can be easily retrieved from this as shown below:
>>> nltk.FreqDist(a)[‘s’] 3
If you wish to find the frequency of each word in a string, tokenise the string first and then apply FreqDist()
>>> nltk.FreqDist(nltk.word_tokenize(a))
FreqDist({‘this’: 1, ‘sharon’: 1, ‘is’: 1, ‘hi’: 1})
Searching text: The concordance() function provided by NLTK searches for a keyword and returns phrases containing it. Users have the facility to set the length of the phrase and the number of phrases to be displayed at a time. The command given below will search for ‘earth’ in text3 which is in the NLTK text book corpus:
>>> text3.concordance(‘earth’,40,5) Displaying 5 of 112 matches: earth . And the earth earth . And the earth was without form led the dry land Earth ; and the gather d said , Let the earth bring forth gras was so . And the earth brought forth gr
We can see that five phrases of length 40 characters are displayed on the screen.
Bigrams: Bigrams in the given input string can be obtained using nltk.bigrams(). This function actually returns a generator object. The code fragment given below illustrates the same:
>>> s=”open source for you” >>> nltk.bigrams(s) <generator object bigrams at 0x7fc49a8025f0>
Output can be obtained as a list by casting this generator to list as shown below.
>>> list(nltk.bigrams(s)) [(‘o’, ‘p’), (‘p’, ‘e’), (‘e’, ‘n’), (‘n’, ‘ ‘), (‘ ‘, ‘s’), (‘s’, ‘o’), (‘o’, ‘u’), (‘u’, ‘r’), (‘r’, ‘c’), (‘c’, ‘e’), (‘e’, ‘ ‘), (‘ ‘, ‘f’), (‘f’, ‘o’), (‘o’, ‘r’), (‘r’, ‘ ‘), (‘ ‘, ‘y’), (‘y’, ‘o’), (‘o’, ‘u’)]
You may feel that the output is not in the form desired because you were expecting word bigrams. In that case, the desired result can be obtained by tokenising or splitting the input into words before passing it to bigrams().
>>> list(nltk.bigrams(nltk.word_tokenize(s))) [(‘open’, ‘source’), (‘source’, ‘for’), (‘for’, ‘you’)]
Now the result seems perfect.
Collocations: nltk.collocations() lists bigrams occurring frequently in the input. The statement given below illustrates its result when applied to text1 in the NLTK corpus:
>>> text1.collocations(num=5) Sperm Whale; Moby Dick; White Whale; old man; Captain Ahab
The parameter num specifies the number of results that should be displayed. In the above example, as specified, the output contains only five bigrams. If we call the function without any parameter, all the frequent bigrams will be displayed.
Vocabulary of a given input: set() in NLTK will do the job. The output of this function preserves the property of a set, i.e., duplicates are not allowed in a set. An example is given below:
>>> s=”open source for you serves you open source related news” >>> set(nltk.word_tokenize(s)) set([‘for’, ‘related’, ‘source’, ‘serves’, ‘news’, ‘you’, ‘open’])
If you do not tokenise ‘s’ before applying set(), the character set in ‘s’ will be the result.
Feature structures
Constraints on natural language input can be better represented by exploiting features. NLTK provides the feature structure to map between feature identifiers and feature values, i.e., it represents a set of feature-value pairs. Feature identifiers are also called feature names. Feature values can be a simple string, int or nested feature values. It is useful when we wish to apply a similar treatment to feature-value pairs.
The general form of a feature structure is [feature1=value1, feature2=value2, ……]. Before use, it should be imported.
>>> from nltk.featstruct import FeatStruct
The statements given below will generate three feature structures — feat1, feat2 and feat3.
>>> feat1 = FeatStruct(number=’singular’, person=3) >>> feat2=FeatStruct(agr=feat1) >>> feat3=FeatStruct(cat=’VP’,agr=feat1, head=feat2) >>> feat3 [agr=(1)[number=’singular’, person=3], cat=’VP’, head=[agr->(1)]]
Here, feat1 contains two attributes — number and person. We can see that feat3’s attribute, head, has nested value.
A feature structure can be a feature list or a feature dictionary, which is automatically decided by FeatStruct depending on the type of argument passed to it. In a feature list, the feature identifier will be an integer. An example is shown below:
>>> type(FeatStruct([1,2,3])) <class ‘nltk.featstruct.FeatList’> >>> type(FeatStruct(sent=feat3)) <class ‘nltk.featstruct.FeatDict’>.
A lot more can be done with NLTK. This article is just an introduction to it. A complete reference to natural language processing using Python can be found in the book ‘Natural Language Processing with Python’ by Steven Bird, Ewan Klein and Edward Loper.

















{kind=link}