






























































Many programming languages facilitate machine learning, a few prominent ones being Java, Python, R and C++. Python leads the field in its ease of use and the simplicity of programming code. Here are some very compelling reasons for why one should use Python for machine learning.
Parents teach us behavioural skills right from childhood, teachers help us increase our knowledge of a range of subjects, and as adults we learn a few life skills based on our experiences. So learning is a part of our life, right from birth to death. Wouldn’t it be amazing if our machines also start learning the same way we do? This question made Frank Rosenblatt jump into the arena of machine learning and neural networks in the 1950s, and he went on to develop the first neural network for computers, which is best known as the Perceptron.
We always wonder how machines can be made to learn by themselves—since they are non-living objects and do not have brains like us. So Rosenblatt tried giving brains to computers. He used the Perceptron to simulate different thought processes of the human brain, in computers. Our brains have a network of neurons and a central nervous system which helps us read situations, actions and conditions, and make decisions based on these. Similarly, the networks developed by Rosenblatt act like the network of neurons for machines or computers. The various algorithms used by neural networks act as the central nervous system, which helps machines make decisions on the basis of information or data collected.
In 1957, one of the first algorithms named Nearest Neighbour was written and it allowed computers to use basic pattern recognition techniques. This algorithm could be used to map the route for travelling salesmen, starting at any city and ensuring they visited all the different cities they needed to, during their tour.
Today, machines are capable of learning by themselves, and this is called machine learning.
Machine learning (ML) is defined as a sub-set of artificial intelligence where different computer algorithms are used to autonomously learn from available data sets and information. In ML, machines or computers don’t need to be explicitly programmed — they can change and continuously improve their algorithms by themselves. Nowadays, ML algorithms help computers to communicate with human beings on their own, write and publish sports match reports, autonomously drive cars, find terrorist suspects and do a whole lot more. ML gave birth to Sophia, a humanoid robot, which received citizenship from Saudi Arabia in 2017.
ML has basically evolved from the study of computational learning theory and pattern recognition in artificial intelligence. It explores the study and construction of different algorithms that can learn from and make predictions on the basis of the available data sets. All these algorithms follow the strictly static program instructions by applying data-driven decisions or predictions through the development of a model from given sample inputs. ML is implemented in a wide range of computing tasks where designing and developing explicit algorithms, that too, with good performance, is quite difficult and often not even feasible. For instance, e-mail filtering, the detection of network intruders or any malicious insiders working towards data breaches, learning to rank, optical character recognition, etc, are some well known applications of ML.
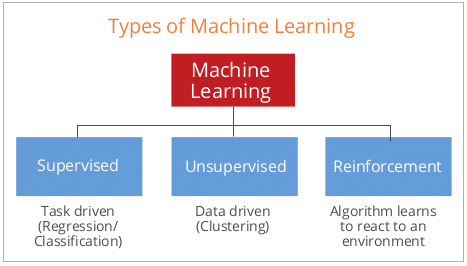
Types of machine learning
Machine learning is broadly classified into three categories on the basis of the way machines learn to increase their knowledge and take decisions.
Supervised machine learning: In this case, we train and teach the machine or computer, using available data sets that are well labelled. It means that some of the data present in the data sets are already tagged with correct answers. Thereafter, the same computer or machine is provided with a new set of data that applies the supervised learning algorithm, analyses the data and then produces a correct outcome from the labelled data.
For example, if we are given a basket filled with different varieties of fruits, when implementing supervised learning, the first step will be to train the machine with respect to the different fruits, one by one. This involves teaching the machine to recognise the different categories so that this knowledge can be applied to the rest of the fruits.
Supervised learning is categorised into two types of algorithms.
Classification: A classification algorithm is used when the output variable expected is in terms of the name of a category, like red, blue, etc.
Regression: A regression algorithm is applied when the output variable expected is in terms of any real value, such as dollars, weight, etc.
Unsupervised machine learning: This is the training of machines using the available set of information that is neither categorised nor labelled. It directly allows the algorithm to act on the information set without any guidance. In unsupervised ML, it will be the task of the machine to group unsorted data according to patterns, similarities and differences, without any prior training. Unlike in the case of supervised learning, no such training is provided to the machine. Instead, the machine needs to find the hidden structure in the given set of unlabelled data on its own.
For example, let’s consider an image that has both dogs and cats, but no information or label is provided with respect to these animals. In this case, unsupervised learning needs to be applied to help machines categorise them.
Unsupervised learning is categorised into the following two types of algorithms.
Clustering: A clustering algorithm is one that is applied wherever we want to discover the inherent groupings in the available data sets, like grouping customers on the basis of their purchasing behaviour.
Association: An association rule algorithm is applied wherever we need to discover a set of rules that describes a large portion of the data, like identifying that the people who buy X are likely to buy Y.
Reinforcement machine learning: This third category focuses on behaviourial psychology. It looks at how software agents should take specific action in any environment to maximise some notion, in order to achieve the cumulative reward. The rewards can be winning a game or earning more money.
Python — an open source programming language for machine learning
Python is simply the Swiss army knife of ML. It is one of the open source programming languages widely used to perform complex operations and has a full suite of tools for increasing the productivity of ML.
Python is popular among its users because it is easy to learn and pretty simple when it comes to programming. It is considered to be one of the most consistent math-like programming languages. Python has its own set of built-in functions and utilities, which help it perform a plethora of complex operations with just a few lines of code. It is also way ahead in terms of its easy syntactical character when compared to other programming languages.
Python has a large set of libraries that can be easily used for machine learning, such as SciPy, NumPy, ScikitLearn, PyBrain, etc. It can be used to develop code in the Map-Reduce model even while working in the Hadoop ecosystem. Spark, one of the modern technologies used for scalable Big Data analysis, has also got its machine learning libraries written in Python. Simplicity and wide applicability make Python a popular ML language.
At times, the code developed in Python almost seems to be written in the English language. The way Python mirrors human language or its mathematical counterparts makes ML a bit easier. As per the TIOBE programming index, Python is ranked No. 5, which is way above other programming languages that are used for ML and data analysis, like R. Python has outperformed R in the fields of data science and ML for the last five years.
Python’s capabilities are given a big boost by the different available packages in ML and data analytics. Pandas, one of the best known data analysis packages, gives Python high-performance structures and several data analysis tools as well. Python excels in offering a playground for playing with data, not just numerically, but also for the following other functions:
- Downloading varied contents from websites and APIs
- Interfacing with different databases and spreadsheets
- Manipulating audio, text and images
- Availability of sophisticated tools for the exploration and presentation of results, like Pandas, Jupyter, etc.
Why is Python suitable for machine learning?
Here are some important reasons why Python is considered ideal for ML.
1. Python is an easy to learn and developer-friendly programming language that is pretty simple to start with. Its syntax is simple and the code can be written in fewer lines as compared to other programming languages.
2. It has numerous built-in packages for ML and other computations — for example, Numpy, Keras, Pandas, etc. All these packages are well-documented, and hence are quite helpful in starting with any project or solution. It accelerates the process of fixing bugs.
3. All the available libraries of Python are quite powerful. They comprise many features that are helpful in performing complex computations. These help in fast, efficient and stable development. Python also uses a wide range of computation speed improvements continuously to improve the performance of libraries.
4. Python has got considerable support from the community, so developers can easily find a large number of tutorials and valuable tips during the development process. This makes it easier to use any new technology from scratch.
5. Python is like the new FORTRAN of the scientific world. It’s very popular in the non-computer scientist’s world, equipping users with an enormously large toolbox for different kinds of applied programming problems.
6. Python makes it very easy to quickly implement or experiment with any new ideas and prototypes. Hence, different scientific and research communities love to use it. That is why it is being widely used in ML and data science.
Starting a Python machine learning project
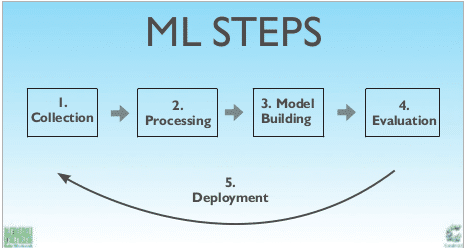
The following steps act as a good guide for how to begin work on a machine learning project.
1. Define the problem: The problem or the scenario for which we want to develop an ML solution must be defined and understood. At times, there is a deviation from the pre-defined problem set while the ML solution is being developed. Hence, this is a significant step to start with.
2. Prepare the data: The data sets for a ML solution that have to be processed and analysed to give a concluding result must be prepared. These available data sets are the inputs used by algorithms and several analysis operations are performed on them before coming to a final result. These data sets have a great impact on the final result.
3. Evaluate algorithms: Different algorithms must be analysed before choosing and deciding to go ahead with one. The algorithm chosen decides the performance of the ML project. The problem set, the behaviour and the volume of the data set, as well as what is expected of the ML project must be considered before choosing an algorithm. There is every possibility that more than two algorithms may perform operations on the data set and give the desired result but the performance factor associated with each algorithm must be evaluated. This plays quite a significant role, especially when it comes to a large ML project.
4. Improve the results: As any ML project has the basic quality of continuously improving itself in terms of the technique used by it or the algorithm implemented, it always obtains better results, every time. Also, machines learn from the diverse set of data which they analyse before giving the result. Hence, even the quality of data sets helps an ML solution produce improved results.
5. Present the results: Once the machine fetches the desired result, it is very important that it is presented in an effective manner so that it can be used further for different applications. The presentation of the desired result is one of the very basic qualities of any ML project. The results can be presented with the help of graphical plots, numerically in the form of some table or even just as the concluding result. But, ultimately, the project should present the result in the desired manner.
Now let us consider some other important factors to ensure an effective and efficient ML project.
Model building, training and evaluation: Developing a machine learning model is a very responsible task as it is almost similar to building a product. The starting point is always ideation, wherein the problem for which the solution is required is considered in its various aspects with some potential approaches. Once a clear direction is established, the solution is prototyped and further tested to check if it meets the needs. A continuous loop between the process of ideation, prototyping and validation takes place until the ML solution is mature enough to be brought into the market, when it is productised for a broader launch.
Data pipeline: A machine learning algorithm generally takes a cleaned data set and learns some patterns in it so that it can decide and make some predictions on the new data set. However, when ML is used for real-life applications, the raw data obtained from the real world is not ready to be directly fed into the ML algorithm. This raw data needs to be preprocessed to generate input data for the ML algorithm. Hence, this entire process of converting the raw data to usable data by the ML algorithm, training an ML algorithm, and finally using this output to perform different actions in the real world is called a pipeline.
Data wrangling: To avoid the ‘garbage-in-garbage-out’ (GIGO) condition, mapping and the transformation of raw data into ML-ready data must be done properly. Data wrangling is one of the key processes that enables an ML project to make a big impact by avoiding GIGO situations. Filtering, cleansing, joining and stacking are the necessary steps to get data ready for ML. Pyspark is one of the widely used engines for data wrangling. This can also be seamlessly integrated with other Big Data engines. Python has got Dask as its indigenous Big Data engine.
Feature extraction and engineering: In an ML project, feature extraction has got its own role to play. During different phases like image processing and pattern recognition in a machine learning project, feature extraction starts from a very initial set of measured data and builds derived values (also called features) that are intended to be non-redundant and informative, hence facilitating the subsequent learning as well as generalisation of steps (and in some conditions leading to better human interpretations). Feature extraction is basically related to dimensionality reduction. Python has a couple of image or video libraries that can assist in feature extraction.
Different open source scientific Python libraries used for machine learning
There are many open source libraries used to implement ML for different applications. They are widely referred to as scientific Python libraries as they are put to use while performing the elementary machine learning tasks.
- Numpy: This is a Python library that is widely used for N-dimensional array objects.
- Pandas: This library file is used for Python data analysis, including different structures such as data frames.
- Matplotlib: This is a 2D plotting library that produces publication-quality figures.
- Scikit-learn: This library contains a couple of the ML learning algorithms that are used for data mining and data analysis tasks.
-
Seaborn: Sometimes it is difficult to get accurate plots with the help of Matplotlib as it focuses on line plots. In such cases, one can go with a more specific library, called Seaborn. It focuses on the visual aspects of different statistical models including heat maps, and also depicts the overall distribution of the data.

















{kind=link}