






























































Apache Spark is a unified analytics engine for Big Data processing, with built-in modules for streaming, SQL, machine learning and graph processing. This article covers various aspects of Spark and Spark Streaming.
“There’s so much buzz and press about Spark right now,” says Cloudera’s chief technologist, Eli Collins.
The need for a powerful data processing engine arose when the data explosion took place in the IT world. Though we have many tools and technologies available to solve Big Data problems, they come with many pros and cons in terms of their processing capacity based on the data volumes, velocities and the sources where the data is created. Apache Spark provides a better solution than most. It can handle data at the peta scale and is capable of processing real-time streaming data. Besides, it can process data from different sources such as Twitter, Kafka, Cassandra, HDFS, S3, Kinesis, etc. Spark is much faster than the MapReduce engine because of its in-memory data processing capabilities. In this article, we will focus more on Apache Spark and its internals. Later, we will create a Spark streaming application to process real-time Twitter data.
All about Apache Spark
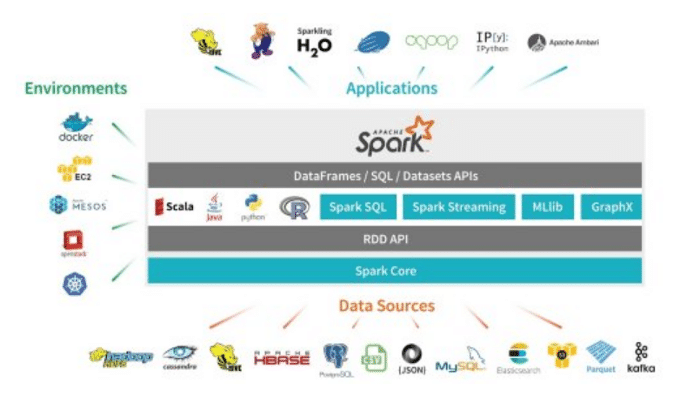
Apache Spark is an open source distributed general-purpose cluster computing framework with an in-memory data processing engine. With it, we can do Extract, Transform and Load (ETL) analysis, machine learning, and graph processing on large volumes of data at rest as well as data in motion, with rich, concise, high-level APIs in programming languages such as Python, Java, Scala, R and SQL. The Spark execution engine is capable of processing batch data and real-time streaming data from different sources via Spark streaming. Spark supports an interactive shell for data exploration and for ad hoc analysis. We can run the Spark applications locally or distributed across a cluster, either by using an interactive shell or by submitting an application.
Spark uses three interactive shells.
spark-shell: The Scala interactive shell
pyspark: The Python interactive shell
sparkR: The R interactive shell
To run applications distributed across a cluster, Spark requires a cluster manager. The Spark environment can be deployed and managed through the following cluster managers.
- Spark Standalone
- Hadoop YARN
- Apache Mesos
- Kubernetes
Spark Standalone is the simplest tool to deploy Spark on a private cluster. Here, the Spark application processes are managed by Spark master and worker nodes. When Spark applications run on a YARN cluster manager, the former’s processes are managed by the YARN ResourceManager and NodeManager. YARN controls resource management, scheduling and the security of submitted applications.
Besides Spark on YARN, the Spark cluster can be managed by Mesos (a general cluster manager that can also run Hadoop MapReduce and service applications), as well as Kubernetes (an open source system for automating deployment, scaling, and management of containerised applications). The Kubernetes scheduler is currently experimental.
How Spark works in cluster mode
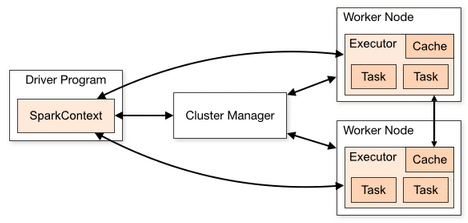
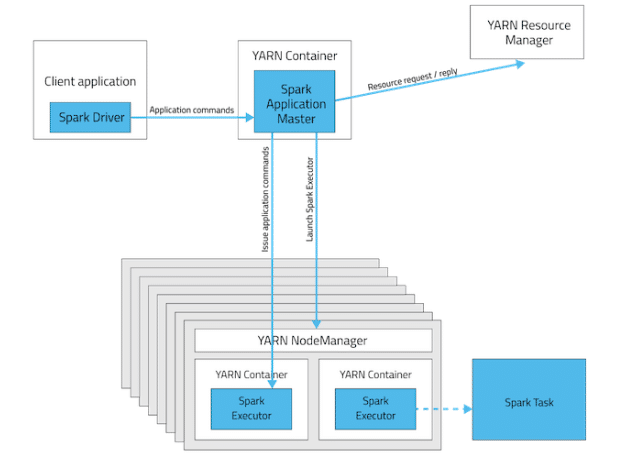
Spark orchestrates its operations through the driver program, which is the process running the main() function of the application and creating the SparkContext. When the driver program is run, the Spark framework initialises the executor processes on the cluster hosts that process the data. The driver program must be network-addressable from the worker nodes. An executor is a process launched for an application on a worker node that runs tasks and keeps data in memory or disk storage. Each application has its own executors, and each driver and executor process in a cluster is a different Java Virtual Machine (JVM).
Here’s what occurs when we submit a Spark application to a cluster:
- The driver is launched and invokes the main method in the Spark application.
- The driver requests resources from the cluster manager to launch executors.
- The cluster manager launches executors on behalf of the driver program.
- The driver runs the application. Based on the transformations and actions in the application, the driver sends tasks to the executors.
- Tasks are run on executors to compute and save results.
- If dynamic allocation is enabled, after the executors are idle for a specified period, they are released.
When the driver’s main method exits or calls SparkContext.stop, it terminates any outstanding executors and releases resources from the cluster manager.
Now let us focus on running Spark applications on YARN.
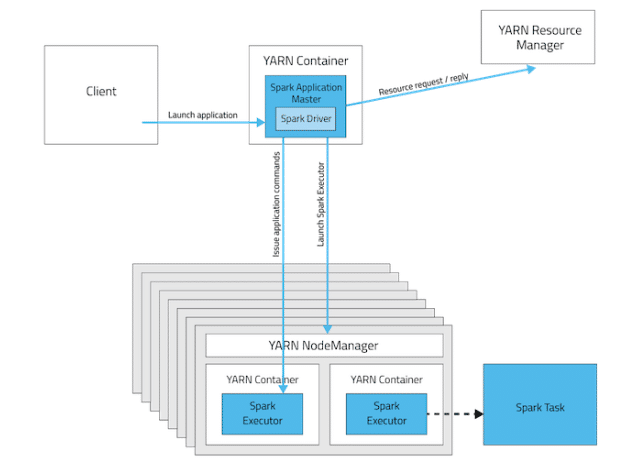

The advantages of Spark on YARN
Listed below are reasons why Spark works best with YARN rather than other cluster managers.
- We can dynamically share and centrally configure the same pool of cluster resources among all frameworks that run on YARN.
- We can use all the features of YARN schedulers (the capacity scheduler, fair scheduler or FIFO scheduler) for categorising, isolating and prioritising workloads.
- We can choose the number of executors to use; in contrast, Spark Standalone requires each application to run an executor on every host in the cluster.
Also, Spark can run against Kerberos-enabled Hadoop clusters and use secure authentication between its processes.
Deploying modes in YARN
In YARN, each application instance has an ApplicationMaster process, which is the first container started for that application. The application is responsible for requesting resources from the ResourceManager. Once the resources are allocated, the application instructs NodeManagers to start containers on its behalf. ApplicationMasters eliminate the need for an active client—the process starting the application can terminate and coordination continues from a process managed by YARN running on the cluster.
YARN cluster deployment mode: In cluster mode, the Spark driver runs in the ApplicationMaster on a cluster host. A single process in a YARN container is responsible for both driving the application and requesting resources from YARN. The client that launches the application does not need to run for the lifetime of the application.
Cluster mode is not well suited to using Spark interactively. Spark applications that require user input, such as spark-shell and pyspark, require the Spark driver to run inside the client process that initiates the Spark application.
YARN client deployment mode: In client mode, the Spark driver runs on the host where the job is submitted. The ApplicationMaster is responsible only for requesting executor containers from YARN. After the containers start, the client communicates with the containers to schedule work.
Why Java and Scala are preferable for Spark application development
Accessing Spark with Java and Scala offers many advantages. They are:
- Platform independence by running inside the JVM, self-contained packaging of code and its dependencies into JAR files, and higher performance because Spark itself runs in the JVM. You lose these advantages when using the Spark Python API.
- Managing dependencies and making them available for Python jobs on a cluster can be difficult.
- To determine which dependencies are required on the cluster, we must understand that Spark code applications run in the Spark executor processes distributed throughout the cluster.
- If the Python transformations we define use any third party libraries, such as NumPy or nltk, Spark executors require access to those libraries when they run on remote executors. It is better to implement a shared Python lib path in worker modes using nfs to access the third party libraries.
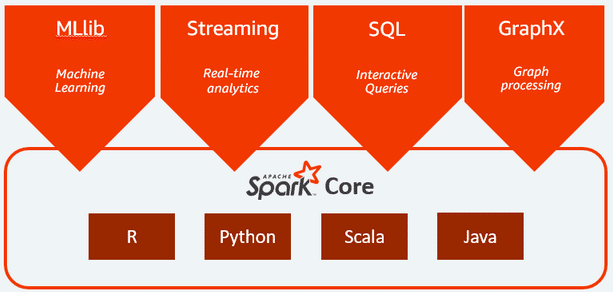
Spark extensions
Apache Spark has 4 extensions. They are given below.
- Spark Streaming – To process a streaming data
- Spark SQL – To process a structured data
- Spark Mlib – To perform machine learning
- Spark GraphX – To analyse graph data
Please refer to Figure 6.
Spark Streaming
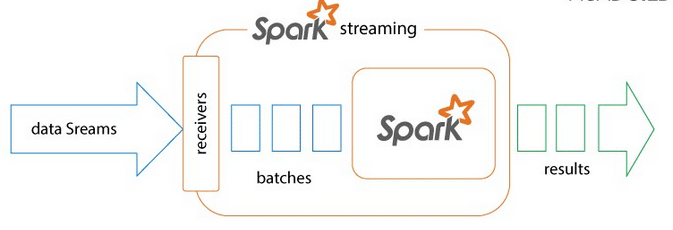
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like MapReduce, Join and Window. Finally, processed data can be pushed out to file systems, databases and live dashboards. We can apply Spark’s machine learning and graph processing algorithms on data streams. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.
Spark SQL
Spark SQL is a module for structured data processing. It supports executing SQL queries on a variety of data sources such as relational databases and hive, through a DataFrame interface. A DataFrame is a data set organised into named columns. It is conceptually equivalent to a table in a relational database. Unlike the basic Spark RDD API, the interfaces of Spark SQL provide more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimisations. There are several ways to interact with Spark SQL including SQL and the data set API. When computing a result, the same execution engine is used, independent of which API/language you are using to express the computation. This unification means that developers can easily switch back and forth between different APIs, based on which one provides the most natural way to express a given transformation.
Machine Learning Library (MLib)
MLib is Spark’s machine learning (ML) library. Its goal is to make practical ML scalable and easy. MLib provides tools and utilities to load ML algorithms such as classification, regression, clustering and collaborative filtering on large volumes of data sets. It supports operations such as feature extraction, transformation, dimensionality reduction and selection. It has pipelining tools for constructing, evaluating and tuning ML pipelines. We can save and load algorithms, models and pipelines. Spark MLib has utilities to work with linear algebra, statistics, data handling, etc.
GraphX
GraphX is a component in Spark for graphs and graph-parallel computation. At a high level, GraphX extends the Spark RDD by introducing a new Graph abstraction—a directed multi-graph with properties attached to each vertex and edge. To support graph computation, GraphX exposes a set of fundamental operators (e.g., subgraph, joinVertices, and aggregateMessages) as well as an optimised variant of the Pregel API. In addition, GraphX includes a growing collection of graph algorithms and builders to simplify graph analytics tasks.
Developing Spark applications
Let us look at how to develop a streaming application using the Apache Spark streaming module. Before that, follow the steps given below:
- Create an application in Twitter.
- Generate an access token and access token secret.
- Note down the customer key and customer secret.
- Ensure the ZooKeeper server and the Kafka broker server are up and running. Create a topic in Kafka to store the streaming data from the following Twitter source:
kafka-topics --create --zookeeper zookeeperserver_host:2181 --replication-factor 1 --partitions 1 --topic rk_hadoop
5. Ensure Python packages such as python-kafka, python-twitter and tweepy are installed in your machine.
6. Update KafkaTwitterStream.py and WordCount.py based on the environment. Execute a Python program which consumes streaming data from Twitter and store it in Kafka topic. KafkaTwitterStream.py is configured to get streaming data for 60 seconds and the WordCount.py application is configured to process data with a 10-second streaming interval.
7. Open a Kafka consumer console in a new tab to ensure streaming data is stored in the Kafka topic:
kafka-console-consumer --zookeeper zookeeperserver_host:2181 --topic kafka_topic
8. Ensure HDFS and YARN service components are working fine in your Cloudera cluster. Submit the application to Spark on the YARN cluster by defining the class path, application jar path and the Spark Master as YARN, and deploy the mode as client/cluster. The number of drivers, executor cores and the amount of driver and executor memory is set by default.
spark2-submit—master yarn—deploy-mode client —conf “spark.dynamicAllocation.enabled=false” —jars /opt/cloudera/parcels/SPARK2/lib/spark2/examples/jars/spark-examples_2.11-2.2.0.cloudera2.jar test1.py zookeeperserver_host:2181 kafka_topic
I have disabled dynamic memory allocation, which means that executors are removed when idle. Dynamic allocation is not effective in Spark Streaming, in which data comes in every batch and executors run whenever data is available. If the executor idle timeout is less than the batch duration, executors are constantly being added and removed. However, if the executor idle timeout is greater than the batch duration, executors are never removed.
9. We can process the streaming data using Spark until the data stream from Twitter is ingested by Kafka.
Here is the code for KafkaTwitterStream.py:
#!/usr/bin/python from tweepy.streaming import StreamListener from tweepy import OAuthHandler from tweepy import Stream from kafka import SimpleProducer, KafkaClient import time access_token = “access_token” access_token_secret = “access_token_secret” consumer_key = “consumer_key” consumer_secret = “consumer_secret” kafka_endpoint = “kafkabroker_host:9092” kafka_topic = “kafka_topic” twitter_hash_tag = “hadoop” time_limit = 60 class StdOutListener(StreamListener): def __init__(self, time_limit=time_limit): self.start_time = time.time() self.limit = time_limit super(StdOutListener, self).__init__() def on_data(self, data): if (time.time() - self.start_time) < self.limit: producer.send_messages(kafka_topic, data.encode(‘utf-8’)) print (data) return True exit(0) def on_error(self, status): print (status) #connect to kafka broker server kafka = KafkaClient(kafka_endpoint) #create a producer object and publish message from twitter source. producer = SimpleProducer(kafka) l = StdOutListener() auth = OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) stream = Stream(auth, l) stream.filter(track=twitter_hash_tag)
The code for WordCount.py is:
#!/usr/bin/python
from __future__ import print_function
import os
import findspark
findspark.init(‘/opt/cloudera/parcels/SPARK2/lib/spark2’)
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
zkQuorum = ‘zookeeperserver_host:2181’
topic = ‘kafka_topic’
if __name__ == “__main__”:
#create spark context
sc = SparkContext(appName=”PythonStreamingKafkaWordCount”)
#create streaming spark context object with streaming interval of 10sec
ssc = StreamingContext(sc, 10)
#read the streaming data from a kafka topic
kvs = KafkaUtils.createStream(ssc, zkQuorum, “spark-streaming-consumer”, {topic: 1})
lines = kvs.map(lambda x: x[1])
counts = lines.flatMap(lambda line: line.split(“ “)).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
How to debug Spark applications
Most Spark users follow their applications’ progress via the Spark Web UI, driver logs and executor logs. Spark History Server is the Web UI for completed and running (incomplete) Spark applications. It is an extension of Spark’s Web UI. It displays tables with information about jobs, stages, tasks, executors, RDDs and more. These are described below.
Job – A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action.
Stage – Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the Map and Reduce stages in MapReduce).
Task – A unit of work that will be sent to one executor.
Executor – A process launched for an application on a worker node, which runs tasks and keeps data in memory or disk storage. Each application has its own executors.
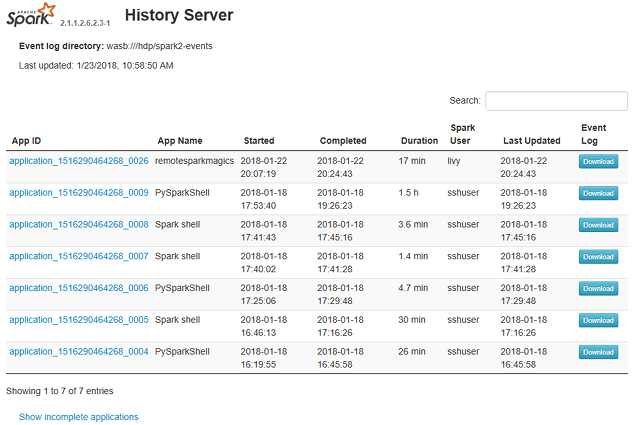
RDD – Resilient Distributed Dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel. There are two ways to create RDDs—an existing collection in your driver program, or referencing a data set in an external storage system, such as a shared file system, HDFS, HBase or any data source offering a Hadoop InputFormat.
If you wish to create a Spark environment on top of a Cloudera distribution of Hadoop (CDH) cluster, with YARN as the cluster manager, and to scale your cluster seamlessly for learning and R&D purposes, do visit my GitHub repo https://github.com/rkkrishnaa/vajra.
Spark is adopted by many companies all over the world. It attracts data scientists and data analysts with its rich set of machine learning libraries and very fast data processing capabilities. Many research activities are going on to integrate Spark with popular cluster managers like Kubernetes. Popular cloud providers such as AWS, Azure and GCP provide Kubernetes cluster service. This will accelerate the provisioning and management of the Spark cluster.

















{kind=link}