






























































Every day, we generate a huge volume of varied data, which in its raw state, does nothing but occupy space. However, if the data is organised and manipulated, meaningful and valuable conclusions can be drawn from it. Therefore, the hunt is always on for tools that assist in the process of handling data. Python Pandas is one such tool.
Data science is the process of deriving insights from a huge and diverse set of data by organising, processing and analysing it. This practice is prevalent in many different domains like e-commerce, healthcare and energy. The programming requirement of data science demands a very versatile yet flexible language, the code for which is simple to write but which can handle highly complex mathematical processing. Python is most suited for such requirements as it is robust enough to handle complex scenarios with minimal code and less confusion. It has a very large collection of libraries that serve as special-purpose analysis tools.
Pandas is an open source Python library used for high-performance data manipulation and data analysis, using its powerful data structures. It is suitable for many different types of data, including table data with heterogeneous columns, such as SQL tables; or Excel data, ordered and unordered time series data, matrix data with row and column labels, or other forms of observation/statistical data sets. Python with Pandas is used in various academic and commercial domains, including economics, statistics, advertising, Web analytics, and more.
This article briefly covers data processing with Python and connectivity to relational databases using Python. It includes queries that allow data manipulations within the Pythonic framework provided by the Python SQL toolkit, SQLAlchemy, which is said to be the best Python database abstraction tool as it provides an accessible way to query, build and write to the SQLite database.
Python: Processing CSV data
Reading data from CSV (comma separated values) is a fundamental necessity in data science. CSV is a simple file format used to store tabular data, such as a spreadsheet or database. The standard CSV format is defined by row and column data. Each row is terminated by a new line to begin the next row. Also, within the row, each column is separated by a comma.
For working with CSV files in Python, import an inbuilt module called csv as follows:
import csv # reading csv file with open(:/Users/Neethu/data.csv’,’r’)as x: # creating a csv reader object data = csv.reader(x) # extracting each data row one by one for row in data: print(row) # print the total number of rows print(“Total no. of rows: %d” %(data.line_num))
The output is given below:
[‘id’, ‘name’, ‘salary’, ‘start_date’, ‘dept’] [‘1’, ‘John’, ‘34000’, ‘05-08-17’, ‘CSE’] [‘2’, ‘Manu’, ‘25600’, ‘23-09-18’, ‘ECE’] [‘3’, ‘Isha’, ‘32500’, ‘05-12-18’, ‘IT’] [‘4’, ‘Ryan’, ‘35678’, ‘01-05-19’, ‘CSE’] [‘5’, ‘Neha’, ‘32100’, ‘27-03-17’, ‘ME’] [‘6’, ‘Pooja’, ‘31000’, ‘03-05-19’, ‘IT’] [‘7’, ‘Sam’, ‘26000’, ‘30-07-17’, ‘ECE’] [‘8’, ‘Sanju’, ‘35908’, ‘27-06-18’, ‘CSE’] Total no. of rows: 9
The Pandas open source library also provides features using which we can read the CSV file in full as well as in parts for only a selected group of columns and rows. Reading the CSV into a Pandas DataFrame is very quick and easy:
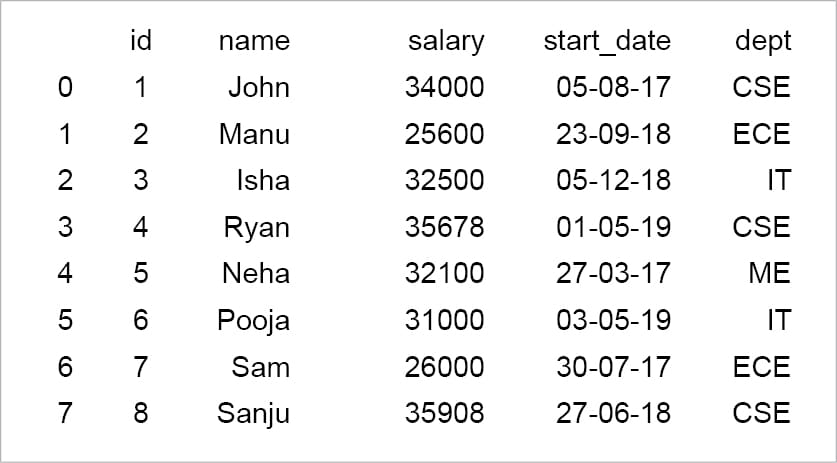
import pandas as pd x = pd.read_csv(‘C:/Users/Neethu/data.csv’) print(x)
The read_csv function of the Pandas library reads the files from the OS by using the proper path to the file. An additional column starting with zero as an index is created by the function.
Reading specific rows and columns: The code print (x[0:5][‘salary’]) will slice the result for the first rows. The read_csv function can also be used to read some specific columns along with the multi-axes indexing method called .loc().
print (x.loc[2:5,[‘salary’,’name’]]) salary name 2 32500 Isha 3 35678 Ryan 4 32100 Neha 5 31000 Pooja
Python: Processing JSON data
A JSON file stores data as text in a human-readable format. JSON stands for JavaScript Object Notation. Pandas can read JSON files using the read_json function. Python is supported with the JSON library. We can convert lists and dictionaries to JSON, and strings to lists and dictionaries. JSON data looks much like a dictionary would in Python, with the keys and values stored.
import json
data = ‘’’{ “apple” : “red”, “banana” : “yellow”, “mango” : “green”}’’’
# load the JSON into ‘a’ variable.
a = json.loads(data)
print(a)
#Write the Data into a JSON File
with open (‘abc.json’, ‘w’) as f:
json.dump(a, f)
The output is shown below:
{‘apple’: ‘red’, ‘banana’: ‘yellow’, ‘mango’: ‘green’}
Using pandas, read a json file using the function pd.read_json()
import pandas as pd
newdata = pd.read_json(‘C:/Users/Neethu/inputdata.json’)
print (newdata)
Python: Processing XLSX data
The Pandas library provides features using which we can read the Excel file in full as well as in parts, for only a selected group of data. We can also read an Excel file with multiple sheets in it. We use the read_excel function to read the data from it. Pandas defaults to storing data in DataFrames. We then store this DataFrame into a variable.
import pandas as pd df=pd.read_excel(‘C:/Users/Neethu/product.xlsx’) print(df) Product Price 0 Computer 24700 1 Tablet 12250 2 iPhone 14000 3 Laptop 25000
For reading specific columns and rows, use the following code:
import pandas as pd data = pd.read_excel(‘C:/Users/Neethu/input.xlsx’) # Use the multi-axes indexing function print (data.loc[[1,3],[‘salary’,’name’]])
For reading multiple Excel files, type the following code:
import pandas as pd with pd.ExcelFile(‘C:/Users/Neethu/input.xlsx’) as xls: df1 = pd.read_excel(xls, ‘Sheet1’) df2 = pd.read_excel(xls, ‘Sheet2’) print(“****Result Sheet 1****”) print (df1[0:5][‘salary’]) print(“”) print(“***Result Sheet 2****”) print (df2[0:5][‘zipcode’]) ****Result Sheet 1**** 0 10000 1 20000 2 23456 3 12345 4 23412 Name: salary, dtype: int64 ***Result Sheet 2**** 0 89765 1 12345 2 23456 3 34567 4 45678 Name: zipcode, dtype: int64
Python and relational databases
SQLite, a database included with Python, creates a single file for all the data in a database. It is built into Python but is only built to be accessed by a single connection at a time. SQLite is self-contained, serverless, very fast and lightweight; and the entire database is stored in a single disk file.
SQLite can be integrated with Python using a Python module called sqlite3. You do not need to install this module separately because it comes bundled with Python version 2.5.x onwards.
The Python SQL toolkit, SQLAlchemy, which is said to be the best Python database abstraction tool, provides an accessible and intuitive way to query, build and write to SQLite, MySQL and Postgresql databases. SQLAlchemy is an open source toolkit, object-relational mapper and an additional library for implementing database connectivity, which provides full SQL language functionality to be used in Python.
To use a database, create a connection object, which will represent the database:
import sqlite3 connection = sqlite3.connect(“College.db”) // created a database with the name “College”
After creating an empty database, add one or more tables to it using the create table sql syntax. To send a command to ‘SQL’ or SQLite , we need to create a cursor object by calling the cursor() method of connection, as shown below:
cursor = connection.cursor()
Now, declare a create table with a triple quoted string in Python, as follows:
cmd = “””CREATE TABLE employee (ssn INTEGER PRIMARY KEY, fname VARCHAR(20), lname VARCHAR(30), salary number, birth_date DATE);”””
Now we have a database with a table but no data included. To populate the table, execute the INSERT command to SQLite.
cursor.execute(cmd) cmd = “””INSERT INTO employee VALUES (“12398”, “John”, “Danny”, “80000”, “1961-10-25”);”””
To save the changes, call the commit method and finally close the connection, as shown below:
connection.commit() connection.close()
Now the code looks like what’s shown below:
import sqlite3
connection = sqlite3.connect("College.db")
cursor = connection.cursor()
cmd = """CREATE TABLE employee (ssn INTEGER PRIMARY KEY, fname VARCHAR(20), lname VARCHAR(30), salary number, birth_date DATE);"""
cursor.execute(cmd)
cmd = """INSERT INTO employee VALUES (“12398”, "John", "Danny", "80000", "1961-10-25");"""
cmd = """INSERT INTO employee VALUES (“98765”, "Ryan", "Harry", "65000", "1965-03-04");"""
connection.commit()
connection.close()
The Python code to query our employee table is as follows:
import sqlite3
connection = sqlite3.connect("College.db")
cursor = connection.cursor()
cursor.execute("SELECT * FROM employee")
print("The employee details : “)
#We use .fetchmany() to load optimal no of rows and overcome memory issues in case of large datasets
#In case the number of rows in the table is small, you can use the fetchall() method to fetch all rows from the database table
result = cursor.fetchall()
for res in result:
print(res)
cursor.execute("SELECT * FROM employee")
print("\nfetch one record:")
#fetchone() returns one record as a tuple or it fetches the records one by one, If there are no more records then it returns None
res_one = cursor.fetchone()
print(res_one)
The output returned is:
The employee details: (‘12398’, ‘John’, ‘Danny’, ‘80000’, ‘1961-10-25’) (‘98765’, ‘Ryan’, ‘Harry’, ‘65000’, ‘1965-03-04’) fetch one record: (‘12398’, ‘John’, ‘Danny’, ‘80000’, ‘1961-10-25’)
A brief summary of the code
- First, we connected to the database by creating a new connection object.
- Second, from the connection object, we instantiated a new cursor object.
- Third, we executed a query that selects all rows from the books table.
- Fourth, we called the fetchone() method to fetch the next row in the result set.
- Fifth, we closed both cursor and connection objects by invoking the close() method of the corresponding object.
Reading relational tables
We pick Sqlite3 as our relational database as it is very lightweight and easy to use. To begin with, create a database engine and then connect to it using the to_sql function of the SQLAlchemy library.
The relational table is created by using the to_sql function from a DataFrame already created, by reading a CSV file. Then we use the read_sql_query function to read the results of an SQL query directly into a Pandas DataFrame, as shown below:
from sqlalchemy import create_engine import pandas as pd data = pd.read_csv(‘C:/Users/Neethu/input.csv’) # To connect we use create_engine(): Create the db engine # we will use an in-memory-only SQLite database engine = create_engine(‘sqlite:///:memory:’) #The return value of create_engine() is an instance of Engine, and it represents the core interface to the database # Store the dataframe as a table data.to_sql(‘data_table’, engine) # Query 1 on the relational table res1 = pd.read_sql_query(‘SELECT * FROM data_table’, engine) print(‘Result 1’, res1) print(‘’) # Query 2 on the relational table will display the sum of salaries & count of employees by grouping department-wise res2 = pd.read_sql_query(‘SELECT dept,sum(salary) as salary_sum,count(*) empcount FROM data_table group by dept’, engine) print(‘Result 2’, res2) Output Result 1 will display the entire table Result 2 dept salary_sum empcount 0 CSE 105586 3 1 ECE 51600 2 2 IT 63500 2 3 ME 32100 1
Insertion and deletion on the database
Inserting and updating rows into an existing SQLite database table, apart from sending queries, is probably the most common database operation. Sqlite3 has a straightforward way to inject dynamic values without relying on string formatting.
Any ‘?’ value in the query will be replaced by a value in values. The first ‘?’ will be replaced by the first item in values, the second by the second item, and so on. This works for any type of query. This creates an SQLite parametrised query, which avoids SQL injection issues.
Finally, we can delete the rows in a database using the execute method, as shown below:
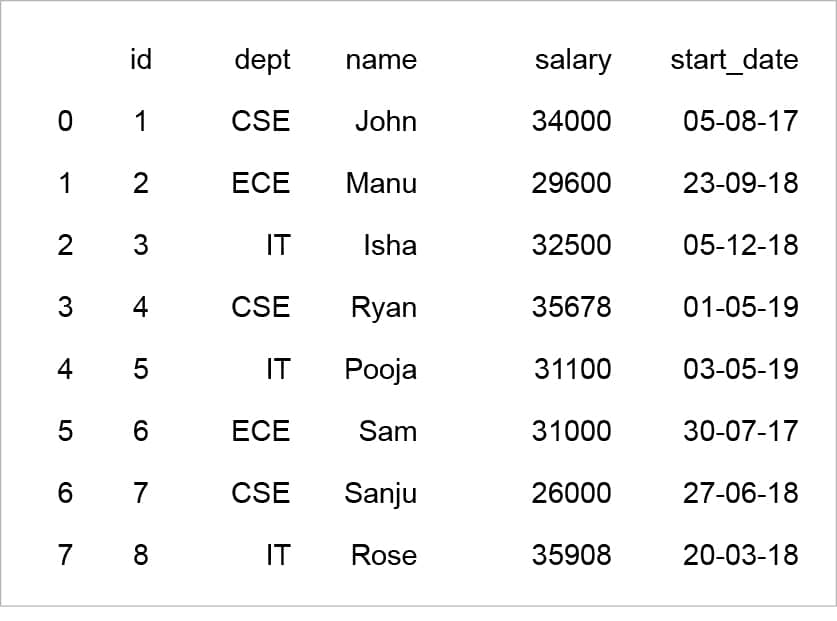
from sqlalchemy import create_engine from pandas.io import sql import pandas as pd data = pd.read_csv(‘C:/Users/Neethu/inputdata.csv’) engine = create_engine(‘sqlite:///:memory:’) # Store the Data in a relational table data.to_sql(‘data_table’, engine) # Insert another row sql.execute(‘INSERT INTO data_table VALUES(?,?,?,?,?,?)’, engine, params=[(‘id’,9,’Rose’,34320,’20-03-18’,’IT’)]) #Update the salary for IT dept sql.execute(‘UPDATE data_table set salary=(?) where dept=(?) ‘, engine, params=[(‘89000’,’ECE’)]) #Delete row where name=Neha sql.execute(‘Delete from data_table where name = (?) ‘, engine, params=[(‘Neha’)]) # Read from the relational table res = pd.read_sql_query(‘SELECT ID,Dept,Name,Salary,start_date FROM data_table’, engine) print(res)
For the output, see Figure 2.
To recapitulate, Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages, numerous libraries and built-in features. This makes it easy to tackle the needs of data science. Pandas is a powerful data analysis tool kit, which is intended to be a high-level building block for actual data analysis in Python. SQLite is the most widely deployed SQL database engine in the world, which can be integrated with Python using a Python module called Sqlite3. Compared to writing the traditional raw SQL statements using Sqlite3, SQLAlchemy’s code is more object-oriented, and easier to read and maintain.
















