






























































A DataFrame is a two-dimensional structure in which data is arrayed in labelled rows and columns. Pandas is a specialised Python library used effectively with DataFrames.
Data science tasks, nowadays, are not limited to the traditional data analysis with limited attributes and records. Currently, real-time data sets are huge in size with numerous attributes. Such data sets are very complex to evaluate using classical data analysis tools. For example, medical data sets integrate a number of attributes including information on symptoms, diagnosis, travel history, health parameters and many others that need to be evaluated. To deal with such types of data sets, assorted database query tools and programming languages are used.
Assorted tools and suites for database applications
The wide variety of tools and technologies available are used by data analysts and data scientists. This leads to effective prediction and visualisation prior to decision making.
Table 1 gives the commonly used tools for data exploration and analytics.
| Tool | URL |
| Trifacta | https://www.trifacta.com/start-wrangling/ |
| RapidMiner | https://rapidminer.com/ |
| Rattle | https://cran.r-project.org/bin/windows/base/ |
| QlikView | http://global.qlik.com/us/landing/go-sm/qlikview/download-qlikview |
| Weka | https://www.cs.waikato.ac.nz/ml/weka/ |
| KNIME | https://www.knime.org/knime-analytics-platform |
| Orange | http://orange.biolab.si/ |
| Tableu Public | https://public.tableau.com/s/ |
| Open Refine | https://openrefine.org/ |
| Talend | https://www.talend.com/products/data-preparation/#free-desktop |
| Data Preparator | http://www.datapreparator.com/downloads.html |
| Tanagra | http://eric.univ-lyon2.fr/~ricco/tanagra/en/tanagra.html |
| H2O | http://www.h2o.ai/download/h2o/choose |
| Gephi | https://gephi.org/ |
| Table 1: Commonly used tools for data exploration and analytics | |
In addition to the above tools and suites, programming languages that can do high-performance statistical and database handling are also used. These include Python, Julia, R and many others. Depending on the application area and data set, one decides on whether to use a high-level language or any other tool for data science. Data scientists use the tools or programming languages as per the outcomes they expect from the data science task.
Using Python Pandas
Python is a very powerful, multi-featured, cross-platform and high performance programming language that is used for multiple applications including data science, machine learning, deep learning, cyber security, cloud computing, grid computing, the Internet of Things, parallel computing, social media mining and many others.
To implement data science tasks, Python has different packages that enable predictive mining and analytics to be done with high accuracy. Python is enriched with multiple libraries and packages for data science based evaluations.
Working with DataFrames in Python Pandas for database applications
In Python, there is a specialised library called Pandas that is easy to use for data analysis and processing. The Pandas library executes very fast and integrates numerous functions for statistical analysis, data evaluation, database management, and many others.
Data scientists and analysts use the Pandas library as it has so many features that ensure high accuracy.
- The following are the key functionalities in Python Pandas:
- Effective DataFrame management for data sets
- Loading and processing of data in multiple formats
- Reshaping of data for assorted research implementations
- Pivot table generation and visualisation
- Grouping and aggregation of data
- High-performance data wrangling
- Missing value imputations and data treatments
- Indexing, slicing and subsetting of large data sets
- Melting, joining, concatenation and merging
- Time series based analysis and predictions
Data analysis on a COVID-19 data set using Python Pandas
Currently, the world is facing the menace of COVID-19 that has resulted in the loss of millions of lives worldwide. Medical experts as well as data scientists are making ceaseless efforts to analyse the patterns of COVID-19 virus using different techniques.
The data sets of COVID-19 are available on the public domain for researchers and academicians, so that solutions and predictions can be worked out by different experts.
Listed below are a few of the links to data sets on COVID-19 which are publicly available for data scientists and researchers:
- data.humdata.org/dataset
- ieee-dataport.org/open-access/corona-virus-covid-19-tweets-dataset
- data.world/datasets/covid-19
- kaggle.com/sudalairajkumar/novel-corona-virus-2019-dataset
- kaggle.com/imdevskp/corona-virus-report
- github.com/datasets/covid-19
- dimensions.ai/news/dimensions-is-facilitating-access-to-covid-19-research/
- sirm.org/category/senza-categoria/covid-19/
- dev.to/anujgupta/google-s-25-million-ddatasets-a-perfect-gift-for-aspiring-data-scientists-3ekh
- github.com/CSSEGISandData/COVID-19
- kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/kernels
- data.humdata.org/dataset/novel-coronavirus-2019-ncov-cases
- github.com/ieee8023/covid-chestxray-dataset
- github.com/CSSEGISandData/COVID-19
- github.com/ieee8023/covid-chestxray-dataset
- kaggle.com/kimjihoo/coronavirusdataset
- open-source-covid-19.weileizeng.com/
- github.com/beoutbreakprepared/nCoV2019/tree/master/latest_data
- kaggle.com/einsteindata4u/covid19/version/4
- cebm.net/covid-19/covid-19-signs-and-symptoms-tracker/
- tableau.com/covid-19-coronavirus-data-resources
For the upcoming data analysis tasks, the COVID data set in the comma separated values (CSV) format is downloaded and then evaluated using Python Pandas. These data sets can be directly imported into the DataFrames using Python Pandas. DataFrames are used for high-performance operations on the data sets.
Grouping and aggregation of data on the COVID data set
In the actual data set shown in Figure 1, there are thousands of records with date-wise entries.
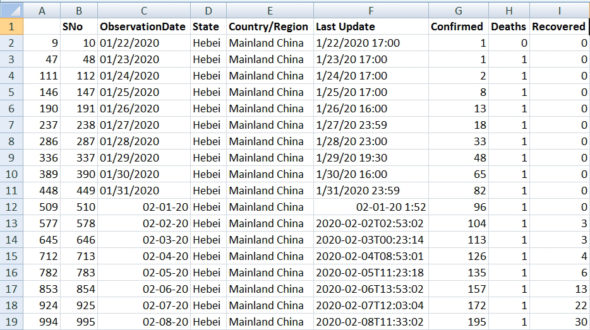
First of all, the data set is imported in the DataFrame, which is available in Python Pandas. The following is very small code snippet of Python Pandas that is executed to perform the grouping of data from the COVID data set after importing the CSV data set in DataFrame:
import pandas as pd dataset = pd.read_csv(“covid_19_data.csv”) dval = dataset.values print (dataset) grouped=dataset.groupby(‘State’) print(grouped.get_group(‘Hebei’)) grouped.get_group(‘Hebei’).to_csv(‘n.csv’)
With the execution of code, the grouping is done by the State and then presented in an understandable and grouped format, as shown in Figure 2. With this approach, the date-wise grouping is performed so that the large data set can be confined and be presented effectively.
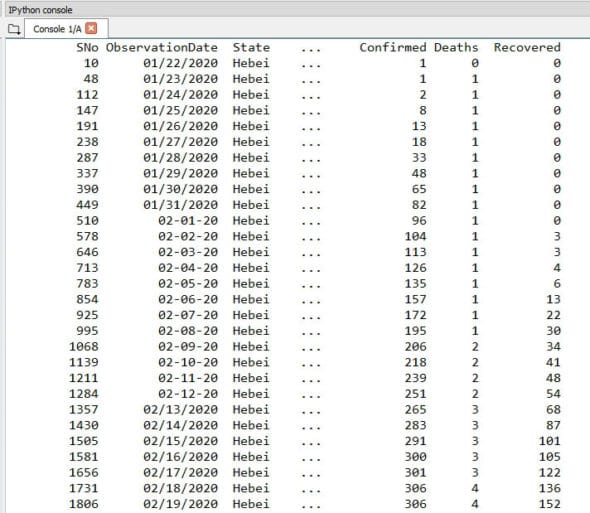
Melting of large data sets using Pandas
Another task that is being performed relates to melting or decomposing the huge data set. In the data set shown in Figure 3, the age, gender and death (Yes / No) is recorded.
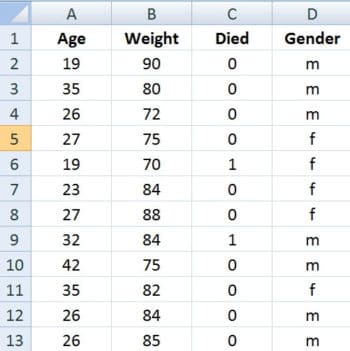
The data set from other formats can also be imported in DataFrame. Once the data is imported to a DataFrame, then different operations can be done. The following is a code snippet of data melting on the COVID data set:
import pandas as pd dataset = pd.read_csv(“covid.csv”) print (dataset) d2=pd.melt(dataset, id_vars =[‘Age’], value_vars =[‘Gender’]) print (d2) d3=pd.melt(dataset, id_vars =[‘Died’], value_vars =[‘Gender’]) print (d3)
As depicted in Figure 4, after melting, the data set can be used for machine learning tasks and data science based evaluations. In the process of melting, the mapping of age and gender is done separately, and the association of gender with death is presented. Using this approach, the large data set can be broken down for further implementations of data science and research tasks with controlled variables.
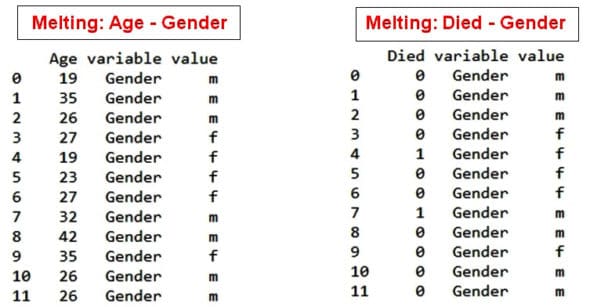
Scope of research and development
As the data sets of COVID-19 as well as other viruses are available in the public domain, these can be used by data scientists and researchers to identify the root causes of the disease and make predictions about its spread or control. Such data sets can be trained using machine learning and deep learning models for predictive mining and analysis, for the benefit of society.
















