






























































Web scalability is a very vast topic of research, practices and experiments. In this article, we will discuss it in detail.
Web scalability is a vast topic for discussion. This article will discuss the story so far, followed by describing the tenets of Web scalability. Then it will offer a perspective on which direction it is headed.
The story so far
Let us first circle back to the OSI 7-layer network stack that we had studied in our undergraduate Networking-101 course.
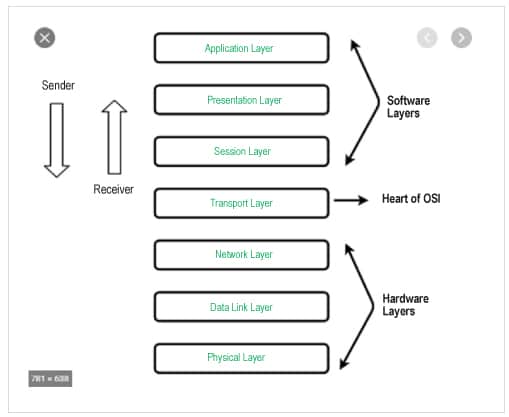
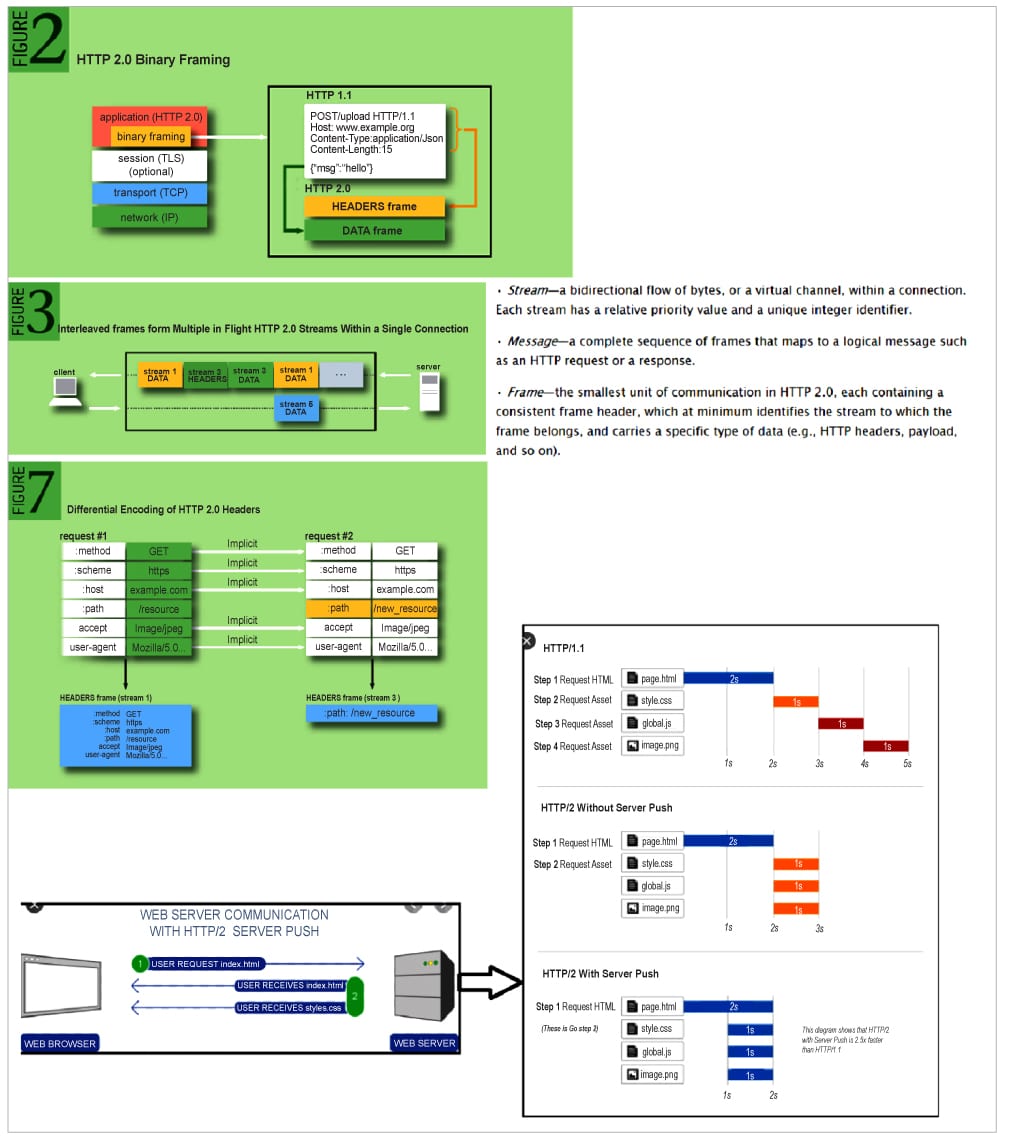
In Figure 1, the top three layers are the soft layers, and the bottom three layers are the hardware-centric layers. The transport layer is at the heart of the soft and hard layers. When an application talks to the underlying hardware, the data flows from top to bottom and vice versa. The application layer is numbered as ‘layer-7’, the presentation layer as ‘layer-6’, and so on.
From a Web scalability perspective, the most important layers are:
1. Application (Layer-7): Http and WebWorker (WSS)
2. Session (Layer-5): SSL/TLS
3. Transport (Layer-4): TCP, UDP, ICMP
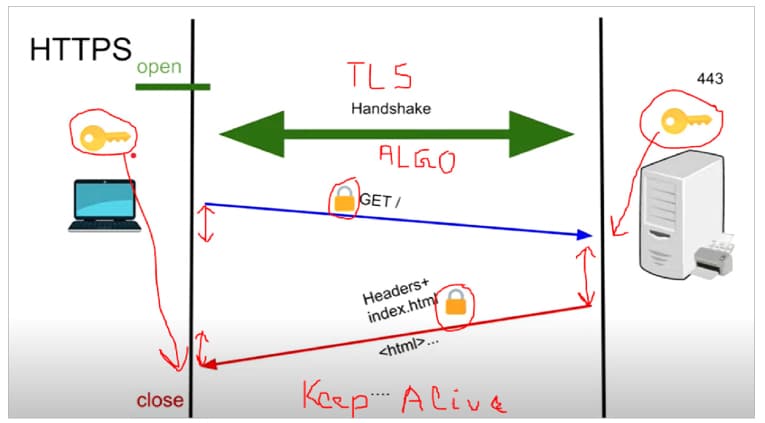
Let us now go back to when an application sends the data over the OSI stack to see how things work – the anatomy of request/response transfer over a network.
![Figure 3: Anatomy of HTTP request [Ref: https://queue.acm.org/detail.cfm?id=2555617]](https://www.opensourceforu.com/wp-content/uploads/2021/06/Figure-3-Anatomy-of-HTTP-request.jpg)
Once the secure channel is set up, the application makes a request. The request takes some time to go to the server. This is called the send time.
Once the data is available to the server, it does some processing. This is the processing time component of the HTTP request, called wait time. Then the data travels back as a response from the server to the client.
The time spent is called the receive time. Figure 3 depicts all of the above.
| Note: Blocked returns the time in milliseconds spent waiting for a network connection. Connect returns the time in milliseconds spent making the TCP connection (0ms to 56ms). Send returns the time in milliseconds spent sending the request to the server (56ms to 84ms). Wait returns the time in milliseconds spent waiting for the first byte of response from the server (84ms to 124ms). Receive returns the time in milliseconds spent reading the complete response from the server (124ms to 152ms). |
Now let us look at the legacy version of HTTP, which is http1.1. The way typical modern Web browsers handle http-1.1 is depicted in Figure 4.
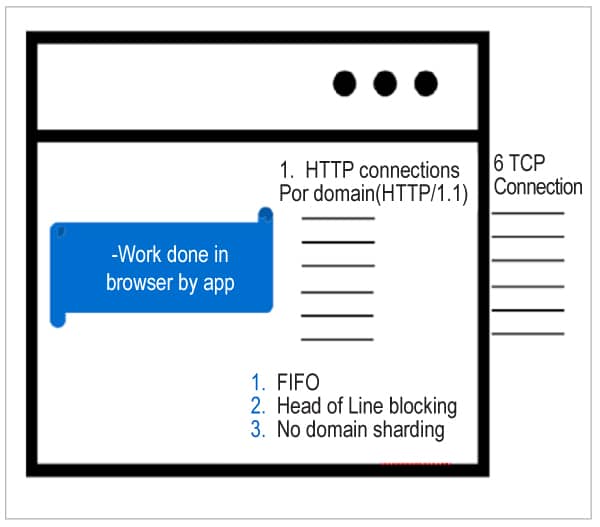
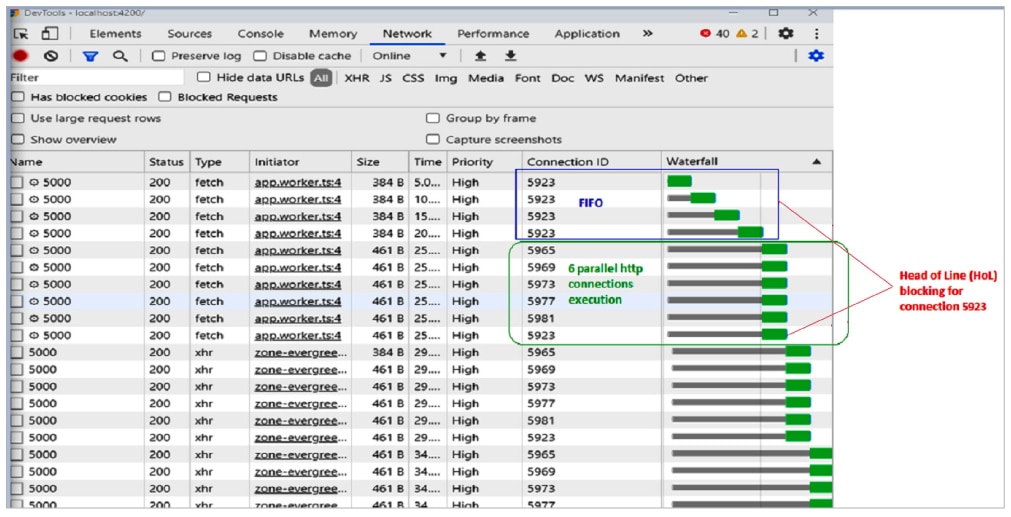
If you want to process multiple requests for a higher throughput requirement of the application, the protocol restricts you to only six concurrent requests at most, at a given time. Note that the http-1.1 protocol RFC does not say a lot about the number of concurrent requests. Most browsers support up to six requests by default. Some browsers can support up to eight. The problem with http1.1 is shown in Figure 5 as the waterfall timing diagram of an application, captured in the Chrome dev tool (press F-12 in the Chrome browser) network tab.
Web scalability tenets
Let us look at the various tenets of Web scalability, in a nutshell (Figure 6).
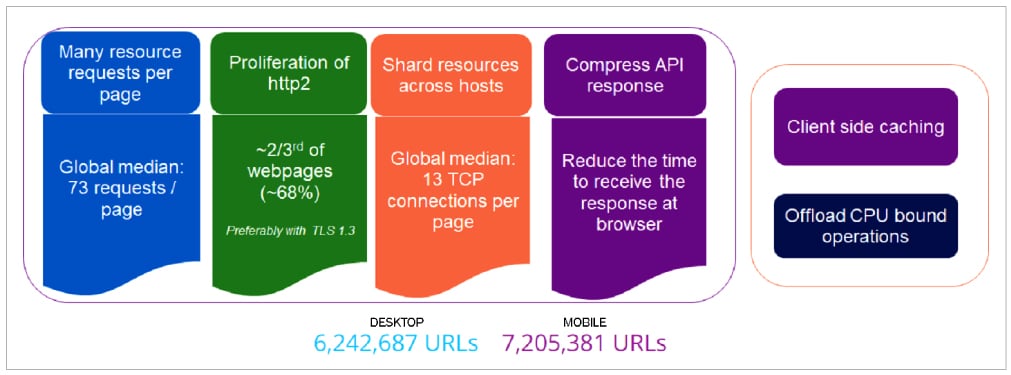
1. The average number of requests per page is 73 – quite a large number.
2. Only one-third of the Web pages are still in legacy http-1.1. Others have moved to http2.
3. Average connections per page are 13, which are more than six (the browser limit for http1.1).
4. Compression of the response is commonplace at the server side; the browser handles the decompression as per the HTTP protocol support.
5. In the client context, client-side caching (layer-7 as well as layer-4), along with usage of Web workers to offload the CPU intensive browser operations into another worker thread(s), is often deployed. The worker thread concept is particularly interesting as the underlying JavaScript execution is single-threaded in a browser.
To demonstrate this further, let’s look at some of the familiar websites we often use (Figure 7).
![Common websites [Reference: https://opensourceforu.com/2020/03/the-evolution-of-web-protocols-2/]](https://www.opensourceforu.com/wp-content/uploads/2021/06/Figure-7-Common-websites.jpg)
The trends
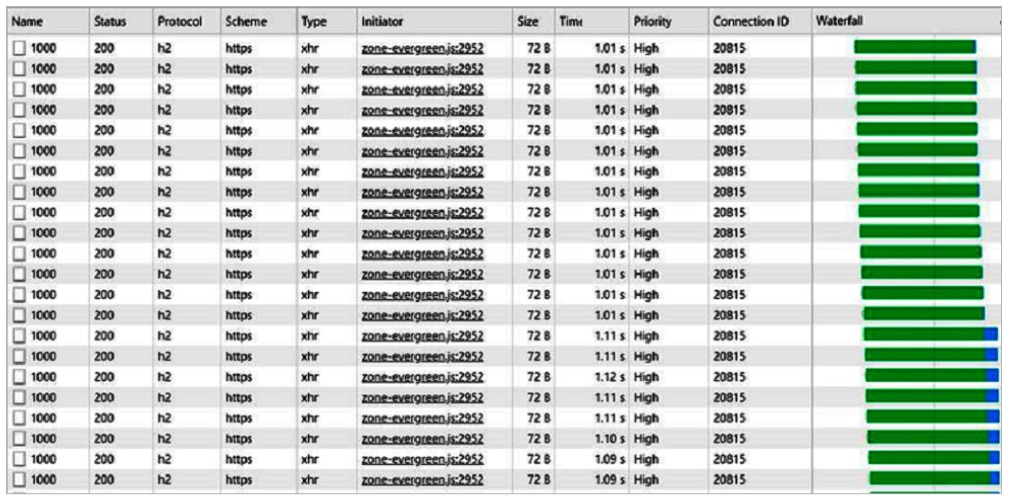
Http2: The following advantages of http2 protocols are seen (Figure 9):
1. Same TCP connection (20815) due to stream multiplexing.
2. Response size reduction, due to header compression
3. Impressive overall performance gain.
The series of pictures given in Figure 10 depict the advantages of http2 in a better way (Reference: https://queue.acm.org/detail.cfm?id=2555617 and https://www.igvita.com/).
TLS v1.3: This has the following advantages:
1. Better speed as one round-trip-time (RTT) is reduced by one-third in TLS v1.3.
2. Better security as fine tuning has been done to avoid attack surfaces like RC4 and BEAST exploits (Reference: https://en.wikipedia.org/wiki/Transport_Layer_Security).
3. Released in 2019 and works seamlessly with http2.
Compression
We carried out a small experiment with the following setup:
1. We placed the client at Bengaluru and the server on the East Coast, USA (North Carolina).
2. We saw that roughly 1.3MB of data was used for 1000 records. And some of the AutoSupport was used for 8000 records max. So, roughly, 10MB data size was taken as representation in this experiment.
3. API returns 30k records, compression level=6 (default), chunkSize=16384 bytes, threshold=0.
And the results are stunning (in our experimental setup), as shown in Table 1.
| Scenario | Elapsed time | Receive time | Data transfer |
| Http1.1 without compression | 10s | 7s | 10MB |
| Http1.1 with compression | 5s | 2s | 2.6MB |
| Http2 without compression | 9.7s | 6.4s | 10MB |
| Http2 with compression | 2.5s | 1s | 2.6MB |
Table 1: REST API compression results
One major advantage of putting all these together is that there is nothing to be changed in the client-side code, as all the code is at the server side only. Browser support for http2 is available. Figure 12 depicts the strategy one can adopt for putting all the above features together in the same basket.
So what lies ahead? Well, there is a lot happening that is very promising. Let us look at it one-by-one.
| Browser | Version implemented (Disabled by default) | |
| Chrome | Stable build (79) | December 2019 |
| Firefox | Stable build (72.0.1) | January 2020 |
| Safari | Safari Technology Preview 104 | April 2020 |
| Edge | Edge (Canary build) | April 2020 |
Http3
The new kid on the block is QUIC or http3. Google and Facebook are already latched on to it. It is UDP driven at layer-4 (transport).
The advantages of Http3 over its predecessors are:
1. Till now the OS (kernel) abstracted out the network stack implementation. So making changes was difficult, and it was time consuming to try and test these changes.
2. QUIC is all about pushing the ‘network stack’ (transport protocol implementation) from the kernel to user space.
3. It is different from http2 because:
a. It is on UDP, so is lighter than TCP. Even vis a vis the latest congestion techniques of TCP (like Cubic, reference: https://en.wikipedia.org/wiki/CUBIC_TCP), UDP is minimalistic and has often proven to be better.
b. Http2 also multiplexes multiple streams through the same TCP connection.
c. However, if the ‘head’ frame suffers a packet loss, the other frames get stuck – that’s http2 Head of Line (HOL) congestion.
d. QUIC solves the problem differently:
- Each overlay data stream has its own end-to-end flow state.
- Delay in one data stream does not affect another.
4. Http3 is now with the Internet

















{kind=link}