






























































CloudOps, as the name suggests, comprehensively covers all the tasks required to run a set of cloud based business applications. Organisations are migrating their IoT systems to the cloud to enhance scalability while optimising performance and capacity. In this article, we highlight how Ansible and Jenkins can be used for CloudOps.
When the infrastructure that supports technology changes structurally, it is essential to understand this change in order to make strategic decisions about the future of a business or project. Cloud computing responds to this need by accelerating the development and scalability of technologies such as artificial intelligence, the Internet of Things and machine learning, optimising processes and assisting in strategic decision making. Regardless of which platform is used or the location of the infrastructure, CloudOps provides organisations with proper resource management. It uses DevOps principles and IT operations applied to a cloud based architecture to speed up business processes.
CloudOps relies on continuous operations and this approach has been taken from DevOps. It is similar to DevOps but used for the cloud platform, and has different flavours like native operations, third party operations and agnostic operations. CloudOps differs from DevOps in that it concentrates more on task automation and cost optimisation factors for the cloud infrastructure, platform and application services.
Ansible reference architecture
Ansible is an important open source automation tool or platform used for diverse IT tasks like configuration management, application deployment, intra-service orchestration and provisioning. Automation is crucial for systems administrators as it simplifies tasks so that attention can be focused on other important activities.
Ansible, being an open source tool, is very easy to understand and doesn’t use any sort of third-party tool or complex mechanism for security. It uses playbooks to perform end-to-end automation of varied components. Playbooks make use of YAML (yet another markup language) to manage all files. Ansible is available for both single- and multi-tier systems and infrastructures.
Here is an example of how playbooks are used. A company releases software, and to make this software functional it is important to have the latest version of the WebLogic server on all machines. It is cumbersome for enterprise administrators to manually check that this has been done across all the machines. The best alternative is to install an Ansible playbook written in user-friendly syntax and YAML, and then run it from the central machine. All nodes (clients) connected to the main machine get updates and make all the necessary changes required to run the software. Figure 1 highlights the reference architecture of Ansible.
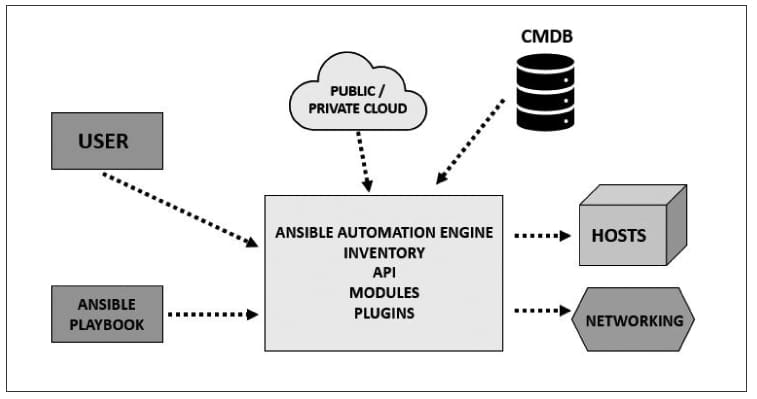
The terms used in this architecture are briefly explained below.
User: This refers to the end user who creates and defines the Ansible playbook, which has a direct connection with the Ansible automation engine.
Ansible playbook: Playbooks comprise code written in YAML, which describes the tasks and their execution via Ansible. These tasks can be synchronously and asynchronously run via playbooks. Playbooks are the heart of Ansible as they not only declare configurations, but can orchestrate the steps of any manual tasks for execution at the same time or at different times on all connected machines. They interact with the Ansible automation engine and configuration management database.
Public or private cloud: Cloud interacts with all the modules, APIs and stores, and it manages as well as processes data. Cloud servers are hosted on the Internet and store data remotely rather than on the local server.
Inventory: This assists in internal provisioning via automation.
API: Systems administrators and developers create APIs for end-to-end interaction of modules.
Modules: Ansible works by connecting to nodes and pushing out small programs, called ‘Ansible modules’ to them. These programs are written as resource models of the desired state of the system. Ansible executes these modules (over SSH by default) and deletes them on finish. Ansible consists of 450 modules for everyday tasks.
Plugins: Plugins are pieces of code that increase the code functionality of Ansible. Ansible is pre-loaded with a number of plugins and also helps the users to write their own. Examples include Action, Cache and Callback.
Networking: Ansible automates diverse networks to make use of all agentless frames and generates useful configurations.
Hosts: These are client machines running Linux or UNIX that come under automation control using Ansible.
CMDB (Configuration Management Database): CMDB is like a repository comprising complete computer networks of IT infrastructure that are fully operational and active for automation of tasks.
Advantages of Ansible:
- Powerful, efficient and highly versatile
- Easy to understand and deploy
- Supports provisioning, application deployment, and orchestration
- Agentless and fully secured
Official website: www.ansible.com
Latest version: 2.10.5
Jenkins reference architecture
Jenkins is an open source automation tool used by DevOps teams for bringing continuous integration into projects. It is written in Java and is used throughout the software development process. It not only supports developers in designing, coding and testing but also in deployment by integrating changes to the project in an easy manner. Jenkins is a continuous integration tool, having hundreds of plugins that provide support for automating tasks like building, testing, delivering and deploying the users’ own projects; running tests to detect bugs and other issues, and doing static code analysis, so that users can spend time doing things that machines cannot.
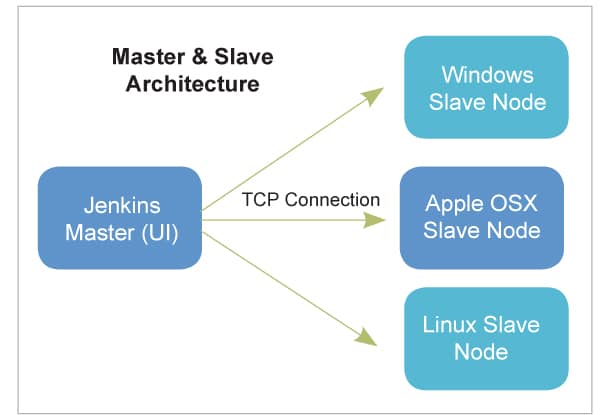
The tool can be accessed and configured using a Web interface, and can be extended with more functionalities through plugins. Jenkins also supports work distribution across several devices, and across diverse platforms.
As a continuous integration tool, Jenkins allows seamless development, testing, and deployment of newly created code. Continuous integration is a process wherein developers commit changes to source code from a shared repository, and all these changes are built continuously. This can even occur multiple times daily. With every commit continuously monitored by the CI server, code efficiency and verification improve. Jenkins architecture is based on distributed computing. It comprises two components:
1. Jenkins server
2. Jenkins node/slave/build server
Jenkins server: When installed, the Jenkins server can be accessed using a Web interface and run-on port 8080. All the jobs and projects are configured using a Web portal dashboard, and build takes place in nodes/slaves. Only one node is configured by default (running on Jenkins’ server), and more nodes can be added using an IP address, user name and password through SSH, jnlp or webstart methods.
The tasks performed by Jenkins server are:
- Scheduling jobs
- Connectivity between nodes and server for execution of tasks
- Monitoring of nodes
- Monitoring of results, and design of overall tasks
Jenkins slave: Slaves work the way they are configured in the Jenkins server, which involves executing build jobs dispatched by the master. Systems administrators can configure the project to always run on particular slave machines or any specific machine, or let Jenkins pick the next available slave/node.
Advantages of Jenkins:
- Open source tool, easy to use and configure, and no need for any extra component to use it
- Supports Windows, Linux, UNIX, MacOS X, and others
- Automates all integration works, saving money and time spent on a project life cycle
Easy to extend and modify;can test, build, automate and deploy code on different platforms. - Detects and fixes issues, and has a diverse range of plugins
- Supports developers for early error detection
Official website: www.jenkins.io
Latest version: 2.281
CloudOps: The technical view
The IT operations landscape and life cycle stages are today more agile, cost-effective, smooth and well-defined, due to technologies like ITOps, CloudOps, DevOps, NoOps, AIOps, BizDevOps, DevSecOps, SysOps and DataOps.
These Ops have not grown to the next stage in a sequential manner but can be logically arranged, as shown in Figure 3.
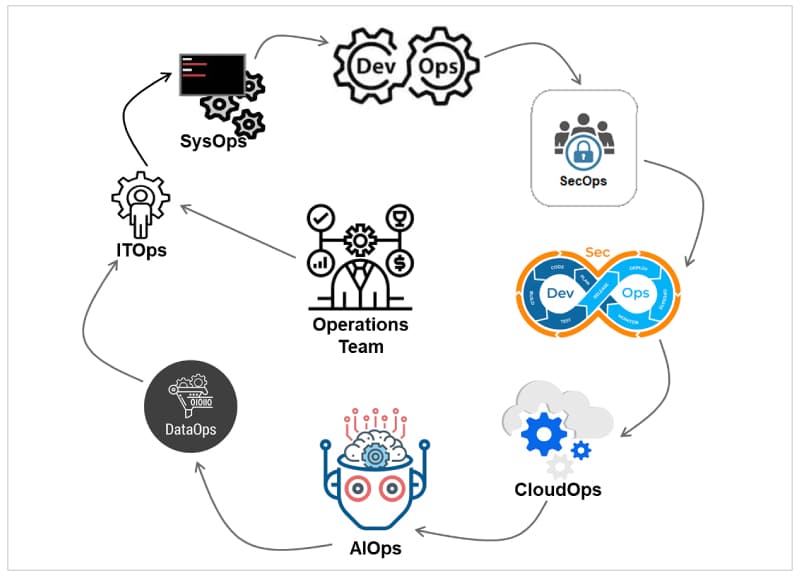
ITOps comprises traditional IT operations for IT management, networks, infrastructure, application management and technical support or help desk operations.
SysOps is more of infrastructure activities (or traditional software configuration management) to handle build, deployment, migration and managing systems in cloud platforms; it is the early stage of CloudOps.
DevOps creates agile teams for Development and Operations that work together in frequent iterations. The improved version of DevOps 2.0 is also called BizDevOps; it enables the business team (e.g., business analyst, consultant) to collaborate with the DevOps team for product development.
SecOps focuses on the relationship between the security and risk management team and the operations team to strengthen various security activities like infrastructure security, network security, data security, application security, etc.
DevSecOps combines DevOps and SecOps for smooth interaction between the development, security and operations teams to design, develop, implement, build, deploy and maintain activities.
AIOps was originally defined by Gartner to handle Big Data platforms, machine learning platforms and analytics platforms. It also aims at automation to reduce the complexity of IT operations.
DataOps is a sliced down version of AIOps to handle data platforms. It includes data management, migration, validation and analytics, and sets up processes and standards for data management activities.
NoOps implies automating everything and spending nothing on the operations team. This is the ultimate aim of organisations. For example, Netflix and Facebook are focusing on development and not setting up an operations team for support.
CloudOps is based on four factors, as shown in Figure 4.
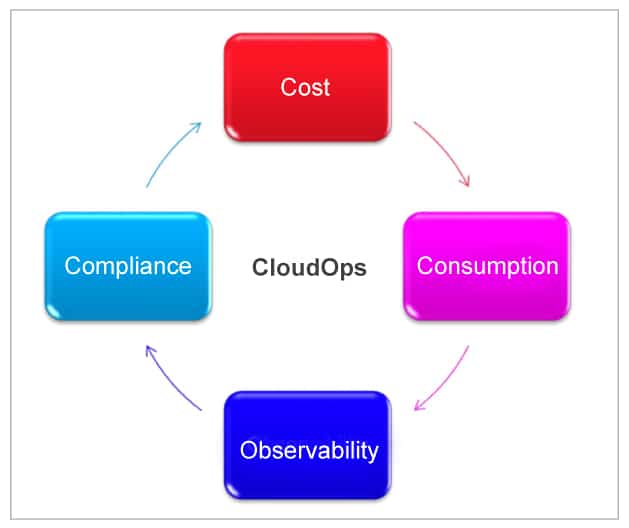
Cost: The monitoring and cloud analytics solution must be cost optimised for better cloud governance.
Consumption: Helps to derive template based options for CloudOps solutions like Terraform templates or CloudFormation/ARM templates in order to reduce the effort and complexity of setting up these solutions.
Observability: Though it is built on traditional services like monitoring, log handling, tracing and auditing, this is one of the key pillars of CloudOps. It ensures that reliability and agility in cloud governance can be handled easily.
Compliance: Security, risk management and compliance handling are key activities, and require swift action to ensure the solution blueprint and cloud platform services are as per the geographic, industry or customer expectations.
CloudOps aims at defining a framework with the above key pillars in order to handle governance, operational activity and cloud platform management efficiently.
Automation of alerts and events in CloudOps helps to simplify activities. Azure provides Azure Monitor, AWS provides CloudWatch and GCP provides Google Cloud Monitoring to proactively monitor any service or resource for performance and health status checks.
They create alerts based on a predefined rule about the threshold of the cloud service utilisation. There are other native services, too, which are very handy for the Ops team to check the health status of the cloud service and its underlying resources from a customisable dashboard facility.
Real-time monitoring and tracking of resources plays an important role in cloud architecture as it helps to understand the behaviour, health status and utilisation of cloud services easily, and helps to drive CloudOps.
Integrating Ansible with CloudOps
Developing an integrated CloudOps pipeline activity includes continuous development, continuous build/integration and continuous deployment. In advanced implementation, we can integrate instance provisioning, role-based permissions and various configuration modules together.
Ansible is a powerful tool for automation of infrastructure services for CloudOps integration using playbooks. Ansible playbooks with integrated CloudOps have a structure as shown in the script below:
Directory structure for ansible: |--aws-ansible/azure-ansible (Playbook for AWS/Azure) |--roles |--instance_provisioning |--tasks (VPC, S3, EC2 instances for AWS and VPN, VM instances for Azure) |--main.yml |--vars (configuration module) |--main.yml |--deploy.yml |--hosts (whitelisting IP)
In general, for CloudOps activities, Ansible is used for orchestration of application packages to artifacts, and a build tool like Jenkins or native code pipeline can be used to build/deploy on top of cloud orchestration.
Ansible works well with AWS and Azure as an integrated orchestration and infrastructure provisioning tool, and can be integrated with native pipelines as well.
Integrating Jenkins with CloudOps
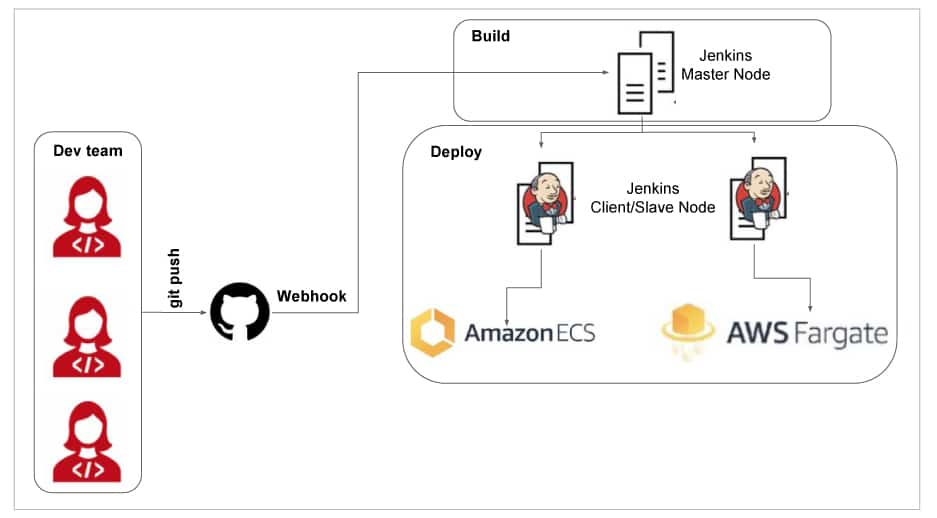
Jenkins is a powerful CI/CD implementation tool/framework that can be used for CloudOps for build and deployment of application services. It can be integrated to AWS, Azure or GCP and be used for native integration to build and deploy Web applications, serverless applications, REST API services, and container services like Kubernetes service orchestration with Dockerized images.
During pipeline integration, Jenkins offers a facility to promote or demote an application build to various stages like development, test, UAT and production. We can use Helm for image registry, or use any container registry like ECS in AWS platform, AKS in the Azure platform, or GKE in the Google platform. We can use native monitoring tools and dashboard facilities from Jenkins to monitor and validate the builds from it.




















{kind=link}