






























































Machine learning has revolutionised the manner in which software is built. However, there are many specific challenges associated with ML based application development. MLflow is an open source platform that offers solutions for these challenges. The major advantages of MLflow are the ability to work with any ML library, run the ML app the same way in any cloud, and scalability. This article introduces various features of MLflow.
Software development has undergone a revolutionary change due to machine learning. ML has made it possible to solve complex problems that were unsolvable with traditional approaches. However, the application development process faces newer challenges now, and the major ones are illustrated in Figure 1.

- Difficulty in keeping track of experiments: One of the major challenges of ML projects is keeping track of experiments. In traditional application development, the output is determined majorly by the code and the input. But the case with machine learning is different. Here, the output depends on code, data and the hyper-parameters that are tweaked to get the optimal results. Hence, to track an experiment, the developer needs to track the combination of code, data and parameters involving the current experiment.
- Difficulty in reproducing the working code: In traditional application development the process revolves around one major language with minimal dependencies on external libraries.However, ML projects have more dependencies as compared to traditional application development. Hence, to reproduce the working code to get the same result again, all these dependencies need to be tracked properly.
- Lack of standards to package and deploy models: Another important challenge is the need to have a standard mechanism to package and deploy the models across various environments. The link between the code and the model that produced the actual output needs to be tracked meticulously.
- Lack of a central store to manage models: During the development of a machine learning application, various versions of the models are created. The archiving of these versions needs to be handled properly.
MLflow is designed to address all these pain points and make the machine learning based application development process seamless and efficient. MLflow is an MLOps platform that makes the development and delivery of machine learning projects easy and effective.
MLflow advantages
The major advantages of MLflow are listed below and illustrated in Figure 2.
- One important advantage of MLflow is its ability to support any machine learning library. It has support for various languages.
- MLflow enables machine learning based applications to run the same way in any cloud.
- MLflow has been designed to support a large number of users. It can support one user as well as thousands of users.
- MLflow is scalable. It can work with Apache Spark to support Big Data.
The power of MLflow can be understood by the way it integrates with a large number of ML libraries and languages, as illustrated in Figure 3.

Another proof of the popularity and usability of MLflow is the large number of big organisations that are using and contributing to it. (A few organisations that support and use MLflow are listed in Figure 4. For the complete list, refer to the official website at https://mlflow.org/. )

There are four major components of MLflow (Figure 5):
- MLflow tracking
- MLflow projects
- MLflow models
- Model registry
Now, let’s take a quick look at the purpose of each of these components.
MLflow tracking
The MLflow tracking component serves the purpose of providing an API and UI. It is used for tracking the following items:
- Parameters
- Code versions
- Metrics
- Output files
These parameters are tracked during the execution of machine learning code and later used for visualisation purposes. MLflow tracking gives you the ability to track experiments using Python, Java, R and REST API.
MLflow projects
MLflow projects provide a format for packaging the machine learning projects that can be reused and reproduced later. This component component includes an API and command-line tools that can be used to execute projects. This helps to chain together projects into workflows.
MLflow models
MLflow models provide a standard format for machine learning model packaging. The models can be packaged in a manner that they can later be used with various downstream tools. This enables real-time serving via REST API or batch inference using Apache Spark.
MLflow model registry
The MLflow model registry serves the purpose of providing a centralised store for models, a set of APIs and UI. These are used to collaboratively manage the life cycle of an MLflow model. It enables the following:
- Model lineage
- Model versioning
- Transitions from staging to production
- Annotations
MLflow installation
MLflow can be installed easily. For example, in Python this can be done using the PIP command:
pip install mlflow
With R, it can be installed as follows:
install.packages(“mlflow”) mlflow::install_mlflow()
To go ahead with quickstart, the code at https://github.com/mlflow/mlflow can be cloned.
Tracking an API
With MLflow tracking API, logging of parameters, metrics and artifacts can be carried out easily. A simple example is given below:
import os from random import random, randint from mlflow import log_metric, log_param, log_artifacts
if __name__ == “__main__”: # Log a parameter (key-value pair) log_param(“sample1”, randint(0, 100))
# Log a metric; metrics can be updated throughout the run log_metric(“Test”, random()) log_metric(“Test”, random() + 1) log_metric(“Test”, random() + 2)
# Log an artifact (output file) if not os.path.exists(“outputs”): os.makedirs(“outputs”) with open(“outputs/osfy.txt”, “w”) as f:
f.write(“Welcome to MLflow”) log_artifacts(“outputs”)
The tracking UI
The MLflow tracking UI can be invoked with the following command:
mlflow ui
With the successful execution of the above command, the tracking UI can be launched in the browser with the following URL: http://localhost:5000.
Executing MLflow projects
As stated earlier, MLflow can be used to package code and the associated dependencies into a project. The saved projects can be executed with the MLflow run command. The projects can be located from the local folder or from GitHub. A sample is shown below:
mlflow run sklearn_elasticnet_wine -P alpha=0.5
mlflow run https://github.com/mlflow/mlflow-example.git -P alpha=5.0
An example using a linear regression model
Let us explore a complete example with a simple linear regression model. Carry out the following steps to get the environment ready.
- Install MLflow and Scikit-learn (if it is not already installed in your system):
pip install mlflow[extras]
- Install Conda.
- From the MLflow repository, clone the code:
git clone https://github.com/mlflow.mlflow
- Navigate to the examples folder.
The training code is located at examples/sklearn_elasticnet_wine/train.py. - A portion of the code is shown below. (The complete code is available at https://mlflow.org/docs/latest/tutorials-and-examples/tutorial.html.)
with mlflow.start_run():
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42) lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print(“Elasticnet model (alpha=%f, l1_ratio=%f):” % (alpha, l1_ratio)) print(“ RMSE: %s” % rmse) print(“ MAE: %s” % mae) print(“ R2: %s” % r2)
mlflow.log_param(“alpha”, alpha) mlflow.log_param(“l1_ratio”, l1_ratio) mlflow.log_metric(“rmse”, rmse) mlflow.log_metric(“r2”, r2) mlflow.log_metric(“mae”, mae)
tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme
# Model registry does not work with file store if tracking_url_type_store != “file”:
# Register the model mlflow.sklearn.log_model(lr, “model”, registered_model_name=”ElasticnetWineModel”) else: mlflow.sklearn.log_model(lr, “model”)
The code can be executed with the default hyper-parameters:
python sklearn_elasticnet_wine/train.py
The hyper-parameters can be supplied as arguments as well:
python sklearn_elasticnet_wine/train.py <alpha> <l1_ratio>
Every time the code is executed, the information is logged in the folder mlruns.
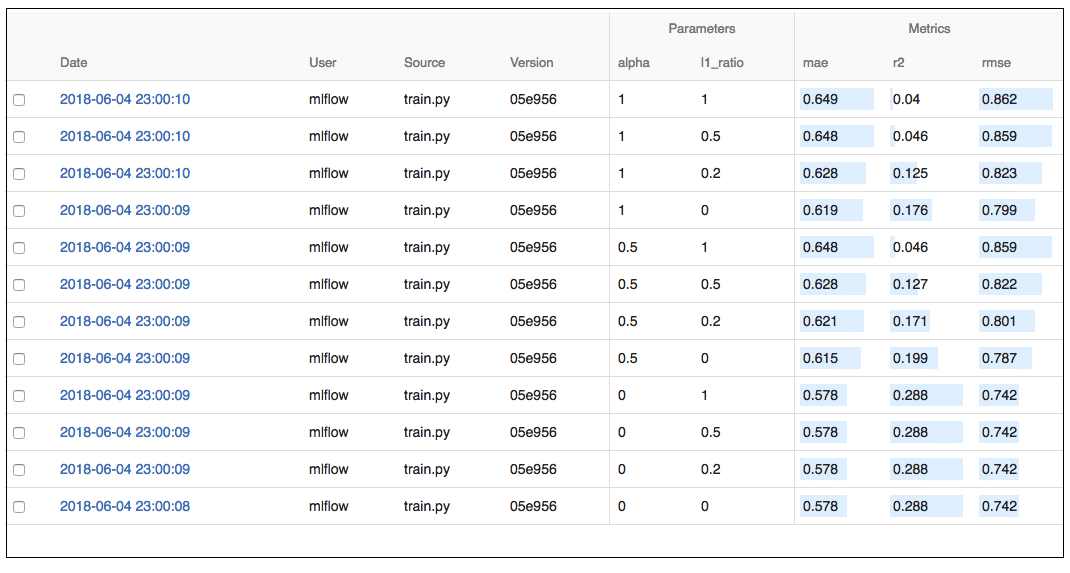
Comparing the models with the UI
The trained models can be compared by launching the UI with the following command:
mlflow ui
The MLflow UI is shown in Figure 6.
Packaging training code
With the MLflow projects conventions, the dependencies and the entry point can be listed. For the example code explained above, the file is located in sklearn_elasticnet_wine/MLproject.
name: tutorial
conda_env: conda.yaml
entry_points:
main:
parameters:
alpha: {type: float, default: 0.5}
l1_ratio: {type: float, default: 0.1}
command: “python train.py {alpha} {l1_ratio}”
conda.yaml lists the dependencies: name: tutorial channels: - defaults dependencies: - python=3.6 - pip - pip: - scikit-learn==0.23.2 - mlflow>=1.0
This project can be executed with specific parameter values, as shown below:
mlflow run sklearn_elasticnet_wine -P alpha=0.48
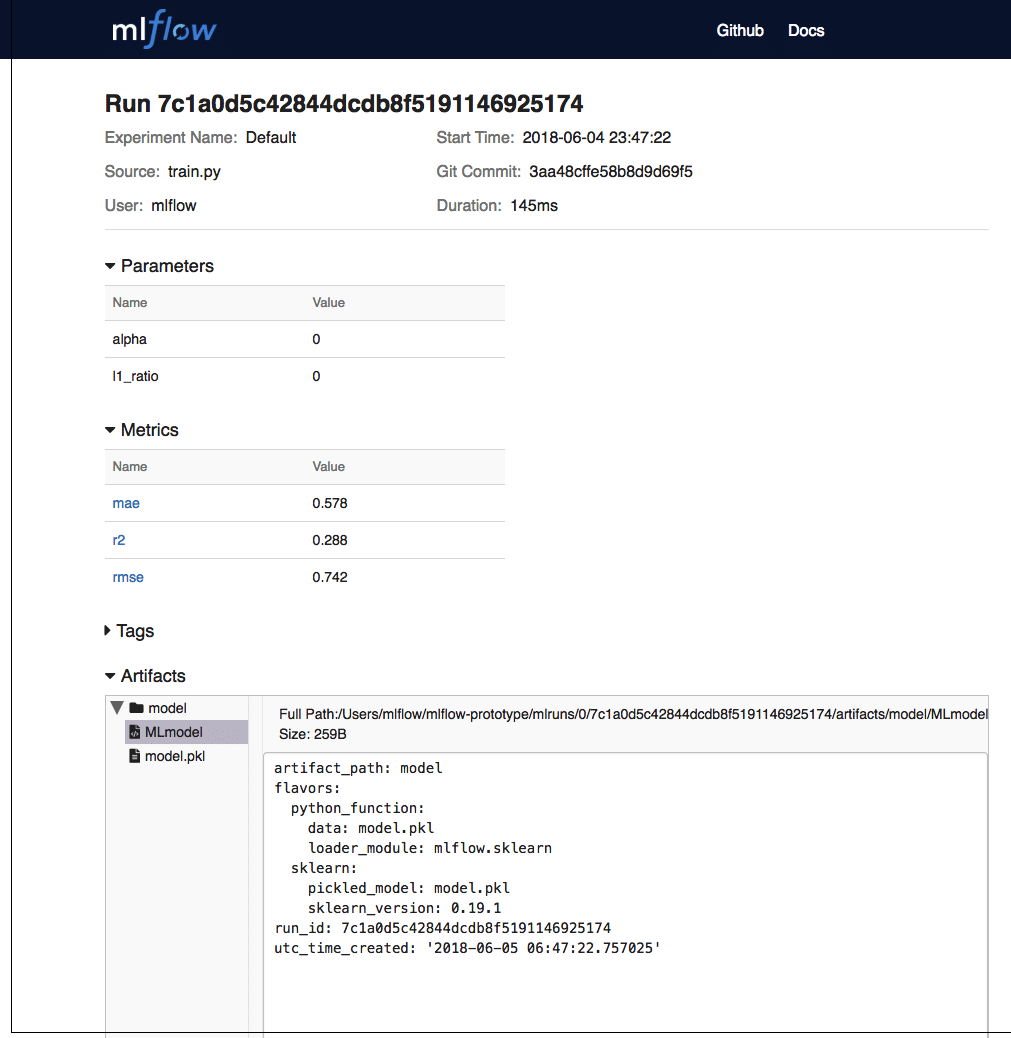
Serving the model
It can be observed from the sample code that it saves the model as an artifact with the command code:
mlflow.sklearn.log_model(lr, “model”)
The artifacts can be explored through the UI by clicking the specific date. A sample is shown in Figure 7.
The model can be served with mlflow models serve.
MLflow makes the ML application development life cycle efficient. Though there are alternatives available, a salient feature of MLflow is its simplicity. The universal support for ML libraries makes it an important platform.



















