

In a phishing attack, a user is sent a mail or a message that has a misleading URL, using which the attacker can collect important data like the passwords of the banks your money is in. This article gives a short tutorial on how to detect such phishing attempts.
Through phishing attacks, attackers acquire important credentials that can be used for getting access to your bank or other financial accounts. The URLs sent by the attacker look exactly the same as the original applications we use on a daily basis. That is why people often believe these and enter their personal details. A phishing URL can open a Web page that looks similar to the original login page of your bank. Detecting such URLs has become very important of late as such phishing attacks are becoming pretty common. So let’s see how we can check whether a URL is a misleading one or a genuine one using machine learning in Python, as it can help us see the code as well as the outputs. We will be using Jupyter Notebook. You can use Google Colab or Amazon Sagemaker too, if you are more comfortable with those.
Download the data sets
To start, we will need the data set to work upon. You can download the data sets from the links given below.
Genuine URLs: https://github.com/jishnusaurav/Phishing-attack-PCAP-analysis-using-scapy/blob/master/Phishing-Website-Detection/datasets/legitimate-urls.csv
Phishing URLs: https://github.com/jishnusaurav/Phishing-attack-PCAP-analysis-using-scapy/blob/master/Phishing-Website-Detection/datasets/phishing-urls.csv
Training the machine to predict
Once we have the data sets, we need to import the required libraries using the following lines of code:
<em>import pandas as pd</em> <em>from sklearn.ensemble import RandomForestClassifier</em>
If you do not have the libraries, you can use pip to install the libraries, as shown in Figure 1.
Once this is done, you can import the data sets and convert them into pandas dataframe for further processing using the following lines of code:
legitimate_urls = pd.read_csv(“/home/jishnusaurav/jupyter/Phishing-Website-Detection/datasets/legitimate-urls.csv”) phishing_urls = pd.read_cs v(“/home/jishnusaurav/jupyter/Phishing-Website-Detection/datasets/phishing-urls.csv”)
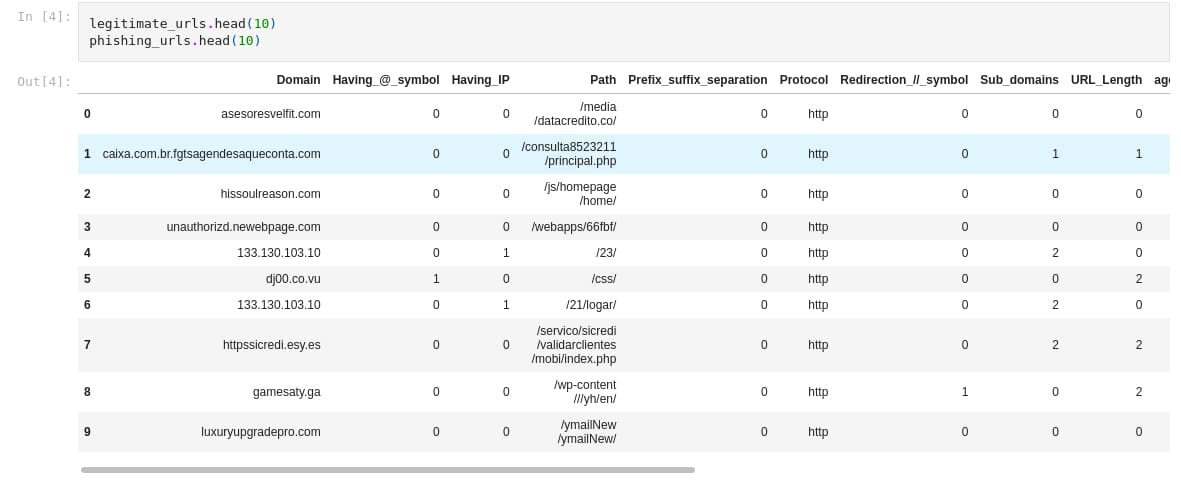
After successful import, we need to merge both the dataframes — the legitimate and the phishing ones, in order to make one data set. The first few lines of the merged data set are shown in Figure 2.
We then drop the columns like path, protocol, etc, that we do not need for the purpose of prediction:
urls = urls.drop(urls.columns[[0,3,5]],axis=1)
After this, we need to split the data set into testing and training parts using the following code:
data_train, data_test, labels_train, labels_test = train_test_split(urls_without_labels, labels, test_size=0.30, random_state=110)
We now make a model using the random forest classifier from sklearn, and then use the fit function to train the model:
random_forest_classifier = RandomForestClassifier() random_forest_classifier.fit(data_train,labels_train)
Once this is done, we can use the predict function to finally predict which URLs are phishing. The following line can be used for the prediction:
prediction_label = random_forest_classifier.predict(test_data)
That is it! You have built a machine learning model that predicts if a URL is a phishing one. Do try it out. I am sure you will have fun.



{kind=link}