






























































There’s a lot of buzz around serverless computing. But should everyone shift to it? And why? Here are some insights.
Serverless doesn’t refer to a non-existing server. Basically, serverless computing is a cloud-computing execution model where machine resources are allocated on demand by the cloud provider, which also takes care of servers on behalf of the customers. Hence, it can also be termed as a method of providing backend services as per usage. The advantage is that companies who get backend services from serverless vendors are charged based on usage and not a fixed amount of bandwidth or the number of servers used.
Why serverless?
In server based systems, it is important to manage infrastructure. This includes server/cluster provisioning, patching, operating system maintenance and capacity provisioning. Such management can be eliminated in serverless computing, helping us focus on just the application and its requirements.
Early physical systems had a lot of maintenance issues, added to the long time taken to deploy them. These were followed by servers being managed in virtual machines, but there was still a lot of complexity involved. Next came containerisation, which eased big and complex applications. But all these systems were server based. The idea of serverless has transformed computing infrastructure, as it does not need server management and can be scaled flexibly. Scaling can be done for customers who use the application, thus optimising costs. With flexible scaling, there is no idle capacity, which leads to high availability.
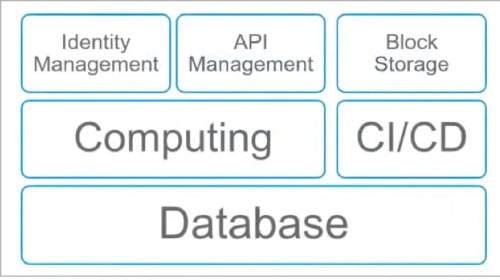
The rate of adoption of serverless computing is increasing every year, making public cloud providers and other leading industries come up with newer serverless based mechanisms. Its offerings are not just limited to computing but also affect databases, storage, identity management, API management, continuous integration and deployment (CI/CD), and so on.
Many startups, where cost plays a significant factor, have considered serverless as their primary choice for cloud services.
Serverless computing is expanding in all directions and is not just limited to one area (Figure 1). This landscape is predicted to only increase and not decrease, as serverless computing reduces costs and is very efficient.
| The advantages of serverless computing: |
| 1. Event driven computing 2. Cost efficiency 3. Smaller DevOps cycle 4. Lower management and compliance burden 5. Faster iterations and rollout of software and services 6. Enhanced reliability 7. Enhanced security; updates to security are rolled out in a timely way and do not affect the availability of services 8. Eliminates the need to time the scaling of capacity and resources; sudden peaks and drops in traffic are managed efficiently |
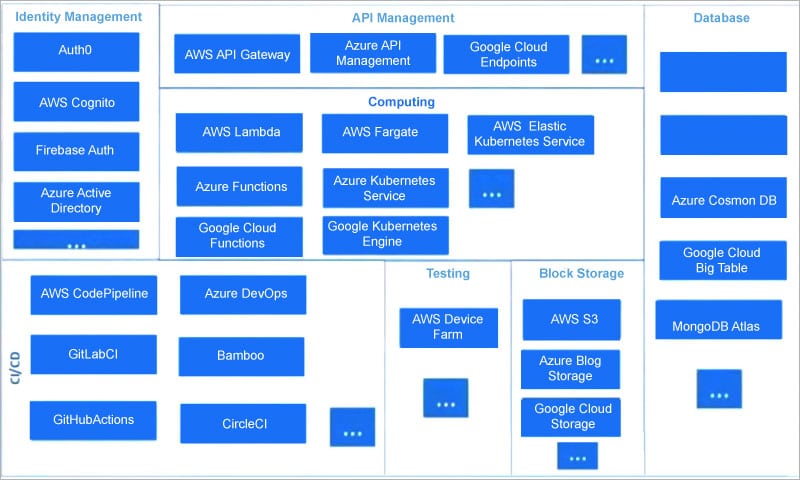
Serverless catalogue
Identity management: From a client perspective, identity management is crucial for any application and involves a lot of effort with respect to compliance. Serverless computing simplifies many things like saving development and maintenance time by integrating with infrastructure resources, both on the cloud as well as on-premise. Services available for this include AWS Cognito, Auth0, Microsoft Azure Active Directory, and Google Firebase Auth, which are especially powerful for sensitive data and help save a lot of time.
API management: With most enterprises migrating to an API-first approach for their solutions, API management is essential for building a distributed and scalable architecture. It provides a proxy for your computer storage layer. Many solutions also support microservices architecture. REST and GraphQL are popular for designing APIs. AWS API gateway, Azure API management, and Google Cloud Endpoints provide many default services. This is unlike yesteryears where developers had to take care of even minute services.
Computing: This involves two aspects, namely, serverless functions and containerisation. The functions expand and provide the ability to focus just on business logic and not on setting up the runtime environment. It works on event triggers like API invocation, message pushing in a queue, identity events, etc; integrates well with mobile as well as Web front-ends, and can scale up to millions of requests. Popular application runtimes like AWS Lambda, Azure Functions and Google Cloud Functions are supported by cloud providers.
Serverless containerisation involves containers that are fast becoming viable alternatives to virtual machines and reduce deployment issues. Cloud providers also provide serverless containerisation — for example, AWS Fargate, AWS Elastic Kubernetes Service, Azure Kubernetes Service and Google Kubernetes Engine. These services are quite powerful, and you only pay for what you use.
Database: Serverless computing offers the feasibility of databases, which are the fundamental building blocks of any application and help in storing structured and unstructured data. Both SQL and NoSQL databases are offered by cloud providers. They also support different open source and proprietary database engines while drastically reducing operational, maintenance, scalability, and security efforts. Working on a database has been simplified through serverless computing. One good serverless database is AWS Aurora Serverless. It is cost-effective and supports both open source and proprietary software. AWS DynamoDB, Azure Cosmos DB, MongoDB and Google Cloud Big Table are also supported by serverless computing.
Block storage: Along with databases, block storages are also essential as they store media, and log files at scale. Large volumes of data, based on the type of application, can be stored by enterprises as well. With the need for storage space increasing, this serverless solution charges nominally as per usage, and is highly available and durable as well. AWS S3, Azure Blob Storage, Google Cloud Storage are some of the popular serverless block storages available.
Continuous integration and continuous deployment: Playing an important role in deployment of applications, a serverless CI/CD solution allows developers themselves to manage CI and CD (though automation is a one-time process). It saves time, is prone to fewer errors, and is readily available and cost-effective. The consistent server performance leads to a faster build process as businesses now expect quick releases. AWS Code, Pipeline, GitLab CI, GitHub Actions, Azure DevOps, CircleCI and Bamboo are a few serverless CI/CDs.
| Design principles to consider |
|
Serverless is a paradigm shift
“Serverless is not for all use cases, but for only a few that can be implemented. It can be only be a part of a solution, not the entire solution.” This is a myth and not a fact.
Serverless computing can be implemented in mobile applications by placing a simple API gateway. Real-time analytics can also be done by utilising a combination of different services.
Serverless is popular and powerful when it comes to usage. Triggering event driven platforms like SNS, S3, DynamoDB, and Lambda can result in customised performance and execution. The Lambda layer is very powerful for implementing some applications.
Due to its simplicity, serverless computing needs a few design principles (see box). It must be designed smartly by architect developers since even though each service is different, assembling all of them in the right fashion is what matters. Earlier, people would guess a capacity and design the service accordingly. However, if something did change from the capacity perspective, a huge rework had to be done in setting up the infrastructure. Instead of being given an architecture system and expecting it to survive for the next five years, evolution of services makes experimentation easy in serverless computing. So it has given engineers and developers new parameters to think and plan accordingly. Hence, serverless computing is a paradigm shift and not just a technology.
Myths about serverless computing
1. Serverless comes with latency: Giving cost-effective solutions along with a provision to implement these services doesn’t mean there is always a latency. There are ways to fix this, which unfortunately many are not aware of.
2. Only compute is serverless: Based on the landscape and catalogue of serverless, it is quite obvious that this is not the case. Many of us use serverless in various aspects but are not aware of it.
3. All serverless APIs are microservices: All microservices are not serverless though it can be used for the same.
4. Serverless is only for limited use cases: As per the different architectural flavours seen, we can conclude that this is not true.
Amidst all that has been spoken about here, the privacy of data being processed is not compromised in serverless, as all cloud providers give a provision to implement a certain way of keeping data private. AWS Cognito is both popular and powerful for data privacy. Similarly, for databases and transition of data, there are provisions to keep the written data in an encrypted way. In conclusion, serverless is a shift in mindset and not just a technology that developers and architects need to understand.
Transcribed by Sharon A Katta




















{kind=link}