






























































Artificial intelligence, machine learning, and deep learning have evolved over decades to help computers perform tasks in the way humans do. This article briefly describes three open source machine learning frameworks — OpenCV, PyTorch and OpenNN – in the context of these technologies.
Artificial intelligence (AI) aims to mimic the functions of the human brain using computers. It uses mathematical and statistical models (e.g., probability) to do so. Machine learning (ML) improves the behaviour of AI models using programming models of brain functions, and storing the results of these models for future predictions.
These technologies are inspired by the human neural network, which is the core storage layer of our brain. The processing efficiency of these neural network based solutions is improved by implementing a distributed model for faster processing, as well as simulation of various brain functions like object detection, analytical ability, etc.
Genetic algorithms improve deep learning models. These have a self-learning ability and are intuitive, hence maximising the applications of AIML (artificial intelligence modelling language) models and reducing the effort in training them. They improve the knowledge base in neural networks.
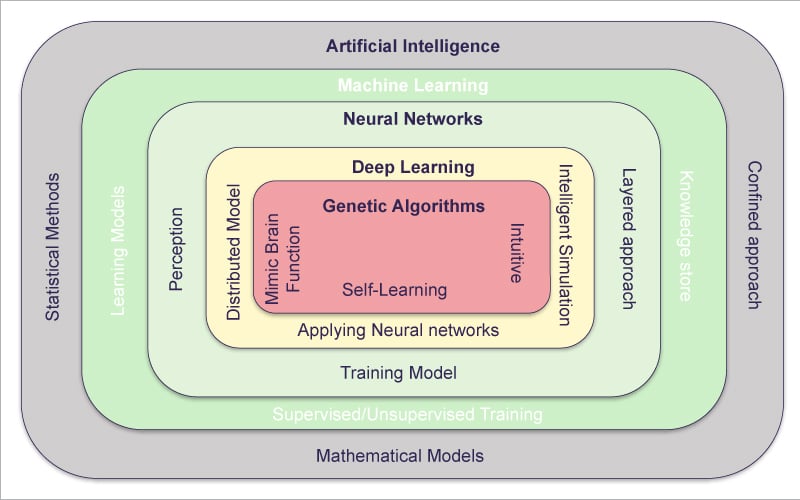
All these technologies are helping computer based applications to improve their ability to come closer to human-like thinking, while reducing the effort needed to build and train models.
Common features of AIML tools
Many tech giants are investing large sums in deep learning projects. These include Facebook, Intel and Google, to name a few. Google Brain is the AI research team in Google, which was first formed in early 2010 to design deep learning solutions using Google platforms. The first software built by this team was DistBelief. Later, it was instrumental in releasing many popular projects like TensorFlow, Google Analytics and Google Translate.
There are many popular machine learning frameworks available in the market, many of which are open source. However, we cannot blindly select a machine learning tool or framework based on convenience. We need to look at the problem scenario, data requirements, data volume to process, training data availability, trainability, algorithm support, visualisation and reporting facility, capability to auto-build the knowledge or training model, processing speed required (CPU/GPU), to name a few, before we make a choice.
In machine learning, building the model is a time consuming task as a lot of training is needed to get higher accuracy in processing the model for the given problem. For example, a lot of training needs to be done to build the neural network of data sets to get greater accuracy in recognising images.
Computational problems are largely solved using a traditional approach like statistical and scientific algorithms. However, some of these problems prove to be costly in terms of time and effort if solved in this way. Pretrained machine learning models can handle such problems using less time and money.
Vision API, image API and face detection
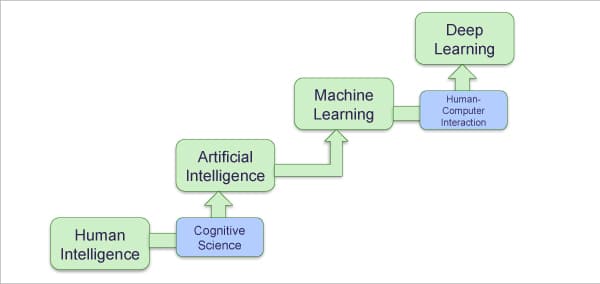
AI grew in importance from the early 1950s to the late 1980s, when engineers developed intelligent machines and programs to address particular problems.
Since training AI models was costly and time consuming, and the accuracy rate or efficiency of the AI algorithms remained static, ML evolved in the 1980s as a subset of AI. ML models learn by themselves without being explicitly programmed, as a self-training capability is slowly built into them. They address specific problems and can be used for image or speech recognition with higher accuracy.
Deep learning (DL) is a subset of ML, which uses a multi-layered neural network and improves accuracy and efficiency by learning from its experience (called historical data). It builds a model based on the history, and is very efficient for large volumes of data. Deep learning started to emerge in the late 2010s and is widely used in speech recognition, image or pattern recognition, object detection in videos and images, and language translation, to name a few.
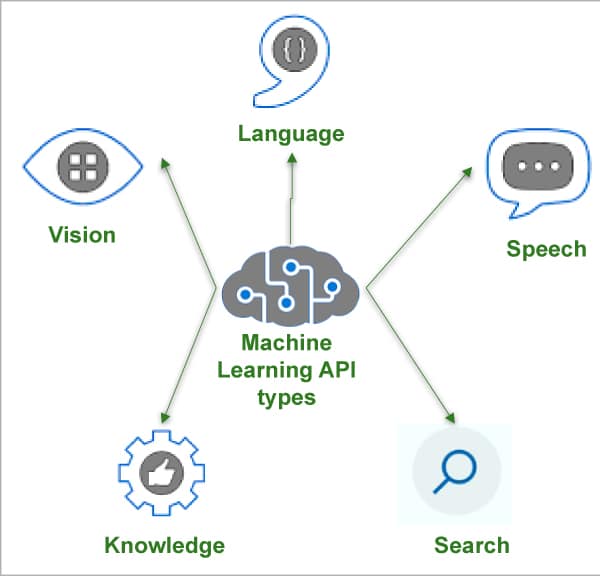
Cognitive services help to quickly develop AI models for applications to manage human-like decision making services such as pattern recognition, speech recognition and search facilities. Machine learning cognitive services can be grouped into five major categories of activities, as given below.
Vision API: This service helps to handle image and video processing in face detection, object detection, and pattern recognition with specific use case features like celebrity/landmark detection, handwritten character recognition and OCR activities.
Language API: This service handles sentiment analysis, language understanding (termed as LUIS), bot facilities for answering questions from the knowledge base, language detection, language translation, phonetic analysis, etc.
Speech API: This service handles speech-to-text and text-to-speech translation, real-time speech translation and transcribing, custom voice moderation, etc.
Knowledge API: This service facilitates bot services, contact centre AI facilities for knowledge base creation, QA extraction from textual documentation, self-training from voice answers, content customisation, personalised learning, semantic matching, anomaly detection in content search, etc.
Search API: Based on Bing or Google search APIs, this service offers a search facility for images, videos, text and audio content; image identification, extraction and classification; lead generation based on search results, etc.
OpenCV
OpenCV is one of the most popular vision API facilitated open source machine learning frameworks. It provides various libraries and hardware simulators for building, deploying and testing machine learning models. One of the most important implementers of OpenCV is the Microsoft Azure platform, which uses it for its MMLSpark framework for advanced Big Data services.
Microsoft has contributed to the Apache Spark framework by introducing the Microsoft Machine Learning for Apache Spark (MMLSpark) framework. MMLSpark expands the distributed machine learning solution of Apache Spark by adding OpenCV, Microsoft Cognitive Toolkit (CNTK) and many other machine learning framework capabilities to the Spark framework in Big Data processing using the enterprise data lake solution.
MMLSpark comprises a group of machine learning libraries. These are listed below.
- Vowpal Wabbit: Library services for machine learning to enable text analytics like sentiment analysis in tweets.
- Cognitive services on Spark: These combine the features of Microsoft cognitive services in SparkML pipelines in order to get a solution design for cognitive data modelling services like anomaly detection.
- LightBGM: Machine learning model to enable training for predictive analysis like face ID detection.
- Spark Serving: Provides a REST API facility to use Spark streaming resources at ease.
- HTTP on Spark: Enables distributed microservices orchestration in integrating Spark and HTTP protocol based accessibility.
- Cognitive Toolkit (CNTK): Deep learning framework from Microsoft to enable a Spark solution for data validation in streaming data.
- Lime: Classifier and modelling solution for distributed models in Spark streaming data.
- Spark Binding Auto-generation: Enables PySpark (Python) and SparklyR (R programming) coding facility for modelling Spark streaming data models.
MMLSpark enables data processing with Spark for modelling solutions using machine learning libraries for image processing, video analytics, text analytics, etc.
Latest version: 4.5.5
Official website: https://opencv.org/
PyTorch
PyTorch is an open source machine learning framework based on the Torch library and is primarily used for computer vision and natural language processing (NLP). Developed by the Facebook AI Research Lab, it facilitates building deep learning models and allows them to be expressed in idiomatic Python. It is an optimised tensor library for deep learning using GPUs and CPUs. Functionality can be extended with common Python libraries such as NumPy and SciPy. The easiest way to get started with PyTorch is to use NGC containers. The PyTorch NGC container comes with all the dependencies that are useful to design applications for conversational AI, natural language processing, recommendation systems and computer vision.
It has two good features:
- Tensor computations with strong GPU acceleration.
- Deep neural networks are built on a tape-based autograd system.
The PyTorch library comprises the following components:
- Torch: This is considered a tensor library like NumPy.
- Torch.autograd: This is a tape based automatic differentiation library.
- Torch.jit: Torch script to create serialisable and optimisable models from code.
- Torch.nm: This is a neural network library.
- Torch.multiprocessing: Python multiprocessing and useful for data loading and Hogwild training.
- Torch.utils: Miscellaneous utilities for developers for using code.
Features:
- Production ready: Easy to use and has flexibility to integrate code in runtime environments.
- Torchserve: Strong tool for deploying PyTorch in an easy manner.
- Mobile support: Supports end-to-end workflow — from Python to deployment on iOS and Android environments.
- Robustness in integration of tools and libraries.
- With a C++ frontend, design and architecture becomes easy to understand, and has low latency.
- Cloud computing ready: PyTorch is well supported for cloud API-based seamless integration.
Latest version: 1.11.0
Website: https://pytorch.org/
OpenNN
OpenNN is a C++ based software library designed for advanced analytics and implements neural networks. The library is stable and very fast in memory allocation. It is constantly optimised and parallelised to attain efficiency in code. It implements data mining methods.
Features:
a. High processing speed
b. Easy design and implementation
c. Proof-of-concept
d. C++ oriented
Website: https://www.opennn.net/

















{kind=link}