






























































Databases are based either on the ACID or the BASE model. The former ensures consistency of transactions while the latter guarantees availability. Both models are governed by the CAP theorem. These key concepts shape your database decisions. Let’s explore them.
Data is the new oil and often referred to as the heart of any organisation. After all, every organisation relies on data to make both short-term and long-term decisions. Choosing the right database is crucial and challenging, as your data resides in it. There are various types of databases, including SQL and NoSQL, centralised and distributed, in-memory and persistence storage — each with advantages and disadvantages.
In this article, we will explore three important concepts: the ACID database model, BASE database model and the CAP theorem. These concepts define different dimensions such as consistency, guaranteed transactions, stable distributed system, and more. There is no single best concept, as each carries its own strengths and challenges. Let’s delve deeper into how each concept ensures data consistency, availability and transaction reliability. Also, let’s explore how each concept is different from another.

The ACID database model
For any database, whether it is SQL, NoSQL or GraphDB, ACID principles are fundamental when it comes to handling transactions.
Before we proceed, let’s first understand what a transaction is — it is a collection of queries that are treated as a single task. So, we need to run all or none at all. If something inbetween fails either intentionally or unintentionally, all changes made within the transaction need to be rolled back to the state just before the transaction began.
For example, XYZ transfers ₹100 to ABC. The transaction is as follows:
- Transaction begin
- Read balance from XYZ
- Proceed only if XYZ > ₹100
- XYZ debit ₹100
- ABC credit ₹100
- Transaction commit
In the above example, we have a ₹100 transaction taking place. If anything fails during the process, the ₹100 will be debited from XYZ but not credited to ABC. Obviously, this is not an ideal situation.
There is another type of transaction which is read only but is still required to be termed as a transaction. We call it a read-only transaction. Let’s explore its requirement through an example.
- Without transaction:
- Count of number of deals booked -> Job 1
- 1 deal got cancelled -> Job 2
- Count of dealers along with count of deals booked -> Continuation of Job 1
- Here you see there will be a conflict in the answers produced by Job 1
- With transaction
- Transaction begin -> Job 1
- Count of number of deals booked -> Job 1
- Count of dealers along with deal booked -> Continuation of Job 1
- Transaction commit
In this case, all the reads within this transaction get consistent data from the database, even if interrupted by other jobs. The current transaction remains unaffected. This is particularly useful while building a huge report or taking a snapshot.
Atomicity
Atomicity represents a single unit — it should not break. All the queries within a transaction must succeed; otherwise nothing occurs, and all changes should be rolled back. There are two types of issues that can cause failure during a transaction.
- Query failure, such as duplicate primary key insert or updating invalid data
- Database failure, such as a hardware crash or power issues
In the case of query failure, we still have the control and can perform the rollback. However, database failures such as hardware crash or crash while performing a commit are serious issues that need to be handled sensitively.
Some databases write directly to the disk and mark the transaction as successful at the end. This approach ensures commit is faster but carries the risk of bad data. To avoid the bad data, some databases copy the old data before applying changes, a technique known as read-copy-update. However, this rapidly increases hard disk space usage.
Other databases maintain changes in the RAM and write in the database only during success. Here the rollback is faster but can lead to issues such as RAM overload and RAM crash. As they say, there’s no free lunch; we need to sacrifice either fast write or fast rollback in these two scenarios.
Typically, several systems implement atomicity through journaling. The system synchronises the logs as necessary after changes have successfully taken place. After crash recovery, it ignores incomplete entries. Different database implementations may vary depending on many factors such as:
- Concurrency issues, allowing the threads of users working on the same data using a lock mechanism. Having time gaps to avoid deadlocks.
- Control of the number of operations included in a single transaction. Here both the throughput and the possibility of deadlock are controlled. The more the operations included in a transaction, the more likely it is that a transaction will block other operations and a deadlock will occur.
- Starting databases only when stale transactions are clear; in some databases they start immediately, and crash changes are fixed in parallel.
However, the principle of atomicity — complete success or complete failure — remains.
Consistency
Consistency means data is in a consistent state when a transaction starts and when it ends. Any progress made from one valid state to another should take care of auto trigger changes, ensure constraints, and so on. For example, when data transfers from A to B, it should verify B exists, and the values after the transaction completes should be valid without any corruption.
Consistency in reading is equally important. This is simpler in a single database where you write and read from the same database. Having distributed databases makes it complicated. If a write is committed and we read from it, if it’s the same database the result would be prompt, but in a distributed database the write needs to be reached from where it is asked to read. At times if we get stale information, we apply a concept called ‘eventual consistency’. This says that while the data is not consistent, it will provide the required information after the sync. Early results of eventual consistency data queries may not have the most recent updates because it takes time for updates to reach replicas across a database cluster.
Isolation
Usually, many transactions run in parallel. Isolation guarantees that the intermediate state of a single transaction is invisible to other transactions, leaving the database in the same state that would have been obtained if these transactions were executed sequentially. As a result, transactions that run concurrently appear to be executed in a serialised or sequential order.
For example, in an application that transfers funds from one account to another, the isolation property ensures that another transaction sees the funds transferred from one account to the other, not leaving both the accounts without credits or debits.
Isolation properties can face a problem due to concurrency, called ‘read phenomena’. This is when a transaction reads data that another transaction may have changed.
- Dirty reads: Reading data that is not fully committed.
- Non-repeatable reads: Reading the same data twice. The query could be different, but the same data is read. For example, if one reads the sum of picture likes and that of the users who liked the picture, the values would have changed due to other transactions. This leads to a mismatch between the sum of likes from the user table and the total number of likes from the pictures table.
- Phantom reads: Re-reading non-existence data, such as reading the sum of likes; then a new record gets inserted by another transaction and that is not read.
- Lost updates/serialisation anomaly: Reading the written data, but unable to find it because other transactions have been deleted or modified.
Isolation levels define the degree to which a transaction must be isolated from the data modifications made by any other transaction in the database system. A transaction isolation level is defined by the above phenomena.
There are different types of isolation.
- Read uncommitted isolation: Allows to read uncommitted changes across transactions. This will be fast as nothing is to be maintained. However, as a downside, there will be several dirty reads happening.
- Read committed isolation: Most popular and default isolation levels, while running a transaction, can only see the changes committed by other transactions.
- Repeatable read isolation: When transactions read a row, they will remember it and keep it unchanged. This remembered value remains the same as the one read before; hence, when re-read happens, it is not affected. The caveat here is that this is expensive, and comes at the cost of valid reads.
- Serializable isolation: All the transactions run here serially, losing the concept of concurrency. This is the slowest of all.
- Snapshot isolation: Each transaction takes the snapshot of the committed changes before the start of the transaction. Here the new inserted rows that cause phantom reads will not occur as these get read from the snapshot. If the number of concurrent transactions increases, it would be costly in terms of the space holding N number of snapshots.
Durability
All the successful transaction information needs to be stored in persistent storage (non-volatile system storage), so that even in the event of a system failure such as hardware crash or power failure, we can recover the committed changes.
To make writing faster, some databases tend to write into RAM and in a backend batch-wise snapshot to the disk. While this is faster, it is also less durable. For example, in an application that transfers funds from one account to another, the durability property ensures that the changes made to each account have made persistent changes irreversible.
Here are a few techniques that ensure high durability.
- WAL – Write ahead log
- Writing in the direct database is expensive and also risky when performing uncommitted changes. This is because during a failure you need to reverse everything.
- WAL records the changes in the log in stable storage and later transfers to the database.
- There is always an issue with OS cache, which writes in RAM and transfers to the hard disk batchwise; we need to record every item in a persistent database. Calling the fsync OS command resolves this, as it forces writes to the disk.
- Checkpoint is a point where the program writes all the changes specified in the WAL to the database and then clears the logs.
- Snapshot
- Generates complete snapshots of the data set in the memory within the specified time interval, and then saves it in the hard disk.
- The save operation can be synchronous or asynchronous.
- There are primarily two issues with this technique. First, the last in-memory data may be lost. Because there is a time interval for generating snapshots, it will cause the last data to fail to generate a snapshot. Second, it is time-consuming and performance-consuming, because the data in the memory needs to be completely snapshotted and written to the hard disk.
- AOF – Append only file
- This writes all write operations to the log file as only append files but not rewrite files.
AOF file is essentially a redo log, through which the database state can be restored. - When the data is restored, the file is read to rebuild the data, that is, if the database is restarted. The write command is executed from front to back according to the content of the log file to complete the data recovery work.
- As the number of commands executed increases, the size of the AOF file increases, which can lead to several problems, such as increased disk usage and slow restart loading. But there are several ways to control this issue.
- This writes all write operations to the log file as only append files but not rewrite files.
The BASE database model
In a distributed environment, the BASE concept is generally applied, prioritising availability over consistency. The BASE model emphasises high availability as the primary principle.
NoSQL, in general, follows BASE. NoSQL databases, which store data in documents such as key-value pair, wide-column, pure documents, and graphs rather than the traditional relational model, are easy to query. NoSQL enables rapid changes, believes in zero downtime, and supports large users distributed globally.
While NoSQL databases usually adhere to BASE principles, some of them also hold certain degrees of ACID compliance.
Given below are the three main properties of BASE.
Basic availability
The system must guarantee availability to all users at all times, even in the event of failures. Ideally, the system should always be available, reach the replica in case of failures, not lock up, and the data should be available while the operation is in progress. Immediate consistency is not the priority; the key is assurance of availability.
Soft-state
As we are not consistent, the stored values may change due to the eventual consistency model. Here we could get stale information which was in sync before. It becomes the developer’s responsibility to ensure consistency.
Eventual consistency
Currently the data may be stale, but the system state is gradually replicated to all the nodes. Data reads are still possible, but may not reflect reality.
From the above principles it’s quite clear that BASE favours availability over consistency.
The CAP theorem
Now let’s look into the CAP theorem; it is the key to understand when your database needs to be distributed. It can be applied to both NoSQL and SQL databases.
Some systems need to be live all the time — 24*7*365. However, it could be tricky to have them running in a single server and single data centre, as there could be hardware crashes, power failure or any natural disaster in the city. Consequently, we always need to anticipate and plan for system failures and design our system to run from different servers and different locations at all times to improve user experiences. Additionally, data should be reliable and highly available.
The CAP theorem is also called Brewer’s Theorem, because it was first put forth by Professor Eric A. Brewer during a talk he gave on distributed computing in 2000. Two years later, MIT professors Seth Gilbert and Nancy Lynch published a proof of ‘Brewer’s Conjecture’.
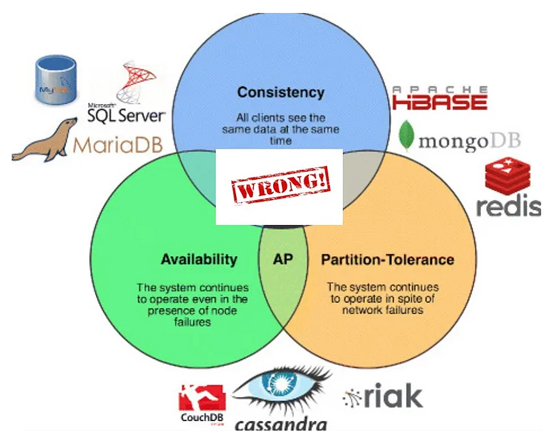
Consistency
This consistency is different from the ACID model’s consistency. Here, a consistent view of data at each node means all the nodes always have the same and most recent view of the data. If not the most recent or if it is not consistent, an error must be returned. Any write to the database should be immediately replicated to the replicas. This will be challenging since syncing globally at the same time is hard. There are several techniques such as change log capturing, querying based on the time stamps, acknowledgement from maximum nodes, and so on, that provide the fastest replication across the nodes.
Also, at times, consistency goes for a toss when we read from the non-updated cache. An example of consistency would be maintaining all the changes done to your bank balance. These should be the same at all times in every distributed system they are saved in. And every retrieval should give the same balance, irrespective from where it is checked.
Availability
Availability of data at each node means the system always responds to requests. The data may not be the most recent, but getting the response is most important. Also, the responses should not be erroneous. Caching can be used to respond even though the data may be stale. While this may sound contradictory with consistency, in availability getting a response is very important.
Partition tolerance
Tolerance to network partitions means systems remain online even if network problems occur. During power shutdowns or natural disasters, the system may be down partially but is still tolerant to accept and process the user’s requests. Ideally, replication across nodes and networks helps here. For example, if I hold an account in the Chennai branch of a bank but there is a power outage in the city, it should not stop me from accessing the money from another or the same location.
CAP guarantees
The CAP theorem guarantees only two properties at a time; we cannot achieve all three together. We need to trade off these properties based on our requirements. Let’s see how.
AP: Availability and partition tolerance
Here the application needs to provide high levels of availability. For example:
- You have one master node and two replica nodes.
- Write to the master; you will be successful immediately after write access.
- Asynchronous replication takes place at the backend.
- One of the replicas loses its connection with the master for the time being.
- Now the disconnected replica is contacted; it gives the response but that’s stale.
- As per our requirement it should be available; we are available, but not consistent.
- For example, YouTube needs to be highly available.
CP: Consistency and partition tolerance
Here the application needs to be consistent at all times. For instance:
- You have one master node and two replica nodes.
- Write to the master; you are successful only if all the nodes or the maximum nodes get the replica applied successfully.
- Here the write is blocked until it gets the success message.
- The blocking makes the system slow and not available.
- The replica nodes in the system send a heartbeat (ping) to every other node to keep track if other replicas or primary nodes are alive or dead. If no heartbeat is received within N seconds, then that node is marked as inaccessible.
- Yes, we can call it partition tolerance, because if one replica goes down the other can still serve the purpose.
- As the commit happens in the end, the consistency is maintained.
- Each node also maintains the operations logs for the fall back server coming up and getting synced like other nodes.
- As an example, banking systems need to be highly consistent.
CA: Consistency and availability
CA database enables consistency and availability across all nodes. RDBMS databases are CA guaranteed. As these systems are usually in a single system, we can have both consistency and availability.
The CA database can’t deliver fault tolerance. Hence, these cannot be used as distributed systems.
To sum up, we have explored the properties of the ACID model that are crucial for determining how to select a database based on each of its parameters. As the ACID model is mostly used in RDMS – SQL databases because of its nature, it needs to be highly consistent. NoSQL, which is distributed in nature, uses the BASE model, which needs to be highly available. The ACID model is usually used in banking applications while BASE is generally used in social network applications. The CAP theorem states that we have to choose any two parameters from availability, consistency and partition tolerance. Now that we are aware of the two major database models and the theorem that governs them, we can choose the database that meets our requirements.


















{kind=link}