






























































This is a practical guide to choosing the right open source database. This choice depends on a clear understanding of the CAP theorem and the unique characteristics of various open source databases.
Data surrounds us in every aspect of our lives, thanks to the pervasive role of technology. From the devices we hold in our hands to enterprise databases, data storage has become essential. The days of relying on a few well-known companies for data storage are long gone, and we now have a plethora of choices when it comes to selecting databases for different use cases. However, with so many options, especially in the open source realm, it can be overwhelming to evaluate the right database for your needs. This article aims to guide you in making that decision.
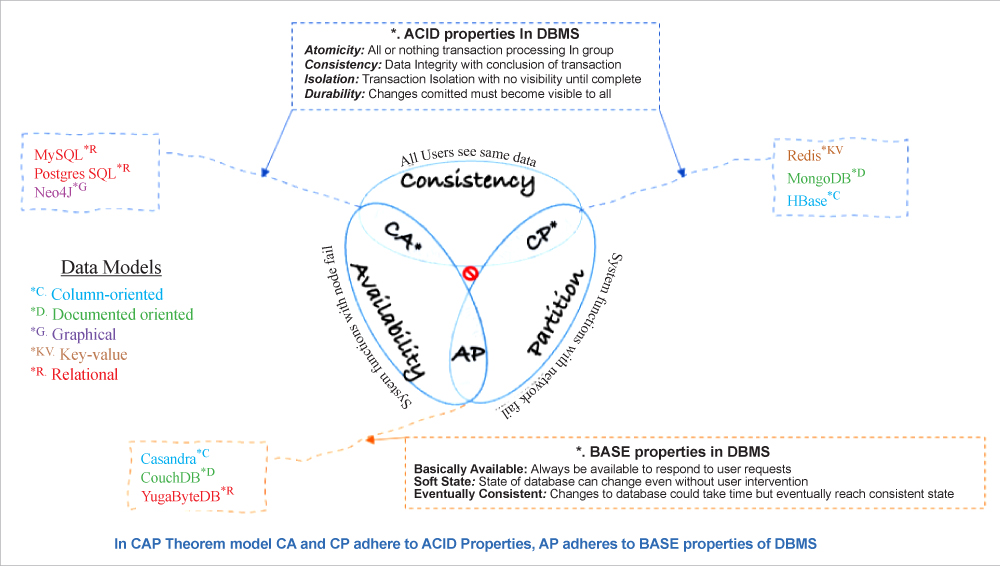
Deploying modern applications in the cloud, with a distributed architecture across multiple cloud environments, has become a common practice for organisations seeking high availability, performance, and resiliency. While this approach is beneficial for meeting non-functional requirements, a deeper look at database deployment would have to be considered in a distributed deployment. Factors such as performance, characteristics and properties of the database are important when selecting a product for specific use cases. Over the past two decades, experts in database technology have adopted proven methods to evaluate databases. The CAP theorem is one of the most popular methods for screening databases, especially for open source databases, where so many options are available. Let’s explore how the application of the CAP theorem in data and transaction models compares for some of the most popular open source databases.
| Database | Data model | Transaction model | CAP theorem adherence |
| MySQL | Relational | ACID | Consistency – Availability |
| PostgreSQL | Relational | ACID | Consistency – Availability |
| Neo4J | Graphical | ACID | Consistency – Availability |
| Cassandra | Column oriented | BASE | Availability – Partition Tolerance |
| CouchDB | Document oriented | BASE | Availability – Partition Tolerance |
| YugabyteDB | Relational | BASE | Availability – Partition Tolerance |
| Redis | Key-value | ACID | Consistency – Partition Tolerance |
| Mongo | Document oriented | ACID | Consistency – Partition Tolerance |
| HBase | Column oriented | ACID | Consistency – Partition Tolerance |
Table 1: Characteristics and properties of open source databases
Distributed databases and the CAP theorem
In modern application design, distributed architecture is widely employed, where databases are deployed across multiple interconnected locations to achieve higher resilience and performance. While this approach is crucial for various reasons, it is equally important to evaluate and select the right database that works for specific use cases. When evaluating a database, we need to consider what we expect from the database out-of-the-box and what we can address through design in terms of consistency, availability and partition tolerance. Let’s take a quick look at what each of these characteristics means and how we can apply them while evaluating a database in a distributed system.
In a distributed system, these non-functional characteristics have specific meanings.
Consistency: All data across all nodes in a distributed system is the same.
Availability: Every request made to the database receives a response, even if some nodes are unreachable.
Partition tolerance: The system continues to operate even if network partitions occur, adversely affecting nodes and creating isolations.
The CAP theorem provides a valuable framework for screening databases when designing distributed systems. It is named after all the three critical DBMS properties — consistency, availability and partition tolerance. According to the theorem, a distributed system must choose between consistency and availability depending on the presence of network partitions. This means that under network partitions, the system can either sacrifice consistency to maintain availability or sacrifice availability to maintain consistency.
While the CAP theorem offers insights into current distributed systems, in practical implementations, availability and consistency can be adjusted and configured to meet specific requirements. Ensuring adherence to each property requires the skills of seasoned database architects in designing, as well as subject matter experts who ensure that configurations are updated to achieve the desired database performance.
Open source databases, like any other distributed databases, are also subject to the CAP theorem. The design choices made by the developers of these databases determine whether they prioritise consistency or availability in the face of network partitions.
Let’s take a look at some of the popular open source databases, each with its own approach to the CAP theorem.
Cassandra, developed by Apache foundation, is a NoSQL database that emphasises availability and partition tolerance over strong consistency. It provides tunable consistency levels, allowing users to choose their desired trade-off between consistency and availability.
MongoDB is another NoSQL database that prioritises availability and partition tolerance. It offers eventual consistency by default, but also provides options for stronger consistency guarantees if required.
CockroachDB is a distributed SQL database that aims to provide strong consistency, high availability, and partition tolerance. It uses a distributed consensus protocol called Raft to ensure consistency across its nodes.
MySQL is a relational database system (RDBMS) designed to provide atomicity, consistency, isolation, and durability (ACID).
YugaByteDB is a distributed SQL database that aims to provide strong consistency, high availability, and partition tolerance. It adopts CP (consistency-partition tolerance), prioritising consistency and partition tolerance in the event of network partitions, sacrificing immediate availability.
Neo4J is a graph database primarily deployed as a single node or small scale clustered database. However, when deployed in distributed systems, it adheres to CA with strong constancy and transactional integrity.
Redis is another database which is deployed in a single-server model in most use cases. However, when deployed in distributed systems, it adheres to CP, lacking availability which needs to be addressed by deployment architecture.
HBase, developed by the Apache foundation, is a columnar database designed for consistency and partitioning in terms of workload profile management.
PostgreSQL is the most popular open source relational database and continues to be the leading choice across all types of organisations. It adheres to CA, leading to implementation focus on partition tolerance.
Any of these databases can be configured for any of the three properties. Striking the right balance between the properties would depend on the use case.
Table 1 provides an overview of the characteristics and properties of various open source databases. It compares them in terms of data model, transaction model and adherence to the CAP theorem. While not comprehensive, this table provides context for comparing different databases against the use cases of interest for any distributed system.
It is important to note that while the CAP theorem offers valuable insights into the trade-offs in distributed systems, not every database strictly adheres to one of the three properties. Many databases offer different levels of consistency and availability depending on the specific requirements of the application.
Engineers and architects designing systems must have a thorough understanding of database properties to fulfil their basic functions effectively. Factors such as heavy reads vs light writes, heavy reads and heavy writes, high volume transactions, changes expected to schema, and more, define the basic characteristics of database requirements. Applying the CAP theorem, ACID, BASE along with considering the data model and transaction model, can help identify the right set of databases that fit the needs. Balancing the trade-offs between consistency, availability and partition tolerance while considering the proof-of-concept will ensure a solid foundation for a well-designed system that meets organisational needs.

















