






























































AWS data management services offer scalability, flexibility, and strong security measures, making them an excellent solution for organisations wishing to maximise their data’s value. You need to right-size them for peak efficiency and avoiding unnecessary costs from overprovisioned resources.
Data is the lifeblood of the modern business world, and good data management is crucial for organisations looking to obtain insights, make educated decisions, and keep a competitive advantage. Amazon Web Services (AWS) provides a diverse set of data management solutions across various use cases, including data storage, processing, analytics, and security.
In the development of cloud native architecture, backend storage plays a critical role and employing a cloud native database has many advantages like cost efficiency, agility and seamless migration from legacy platforms.
To harness the power of their data, organisations must carefully choose and efficiently combine AWS data management services. AWS’s scalability, flexibility, and strong security measures make it an excellent solution for organisations of all sizes and industries wishing to maximise their data’s value.
Data migration to the AWS platform
A significant factor for achieving better total cost of ownership (TCO) in cloud adoption involves transitioning from commercial OLTP databases to native offerings like RDS (Relational Database Service) or Aurora in AWS. This transition offers cost benefits and facilitates integration with native services.
Data migration from one source type to another is a complex task, contingent upon factors such as database complexity, data volume, compatibility between source and target (data types, data objects), and more.
AWS provides native migration tools like AWS Schema Conversion Tool (SCT) for migrating data objects and structures from source to target, encompassing tables, indexes, data constraints, functions, and procedures, among others. Once completed, the target database in AWS will have the like-to-like structure of the source, enabling the use of AWS data migration service (DMS) tools. Figure 1 shows these steps in order.
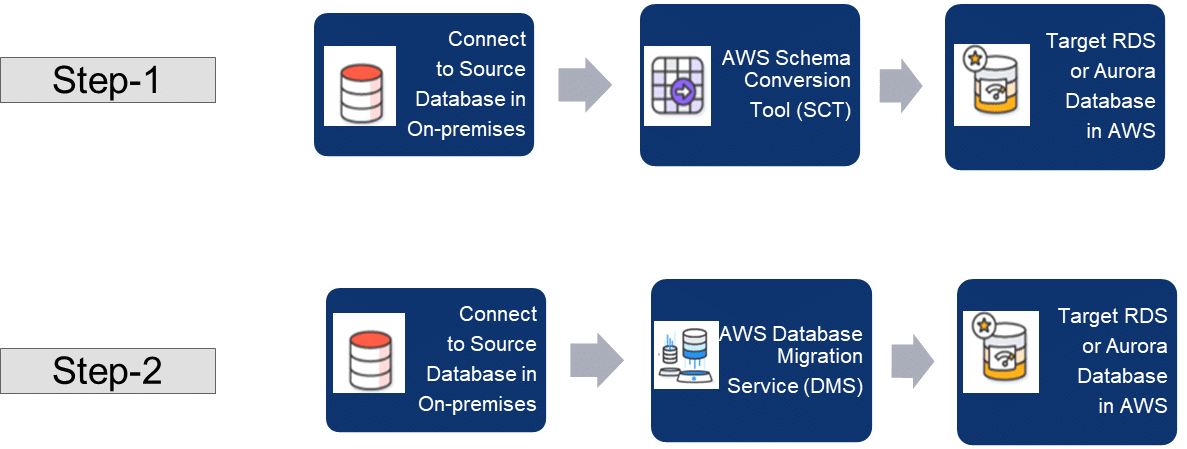
DMS ensures high reliability and recovery of data migration, supporting scheduled migrations to migrate data during weekends, minimising live data traffic in databases from running applications. Also, using S3 bucket for storing buffered data expedites migration to AWS database, and DirectConnect facilitates connection and transfer of data from on-premise to the cloud. For higher data security, DMS encrypts data in transit during migration ensuring data integrity.
Architectural decisions on choosing the right database solution for the target architecture hinge on various factors, including functional and non-functional requirements (NFR). Table 1 lists various AWS database services and their potential use cases aiding in decision-making for selecting the right database solutions.
| Database service | Features/Design requirements | Potential use cases |
| Amazon RDS | Managed relational databases and support for various database engines (MySQL, PostgreSQL, etc) Automated backups and scaling High availability Security and compliance |
Web applications, e-commerce, content management |
| Amazon DynamoDB for RDBMS | Managed NoSQL database Seamless scalability High performance Low latency access Automatic sharding Encryption at rest and in transit Global tables for multi region replication |
Mobile and web applications, gaming, IoT |
| Amazon Redshift for data warehouse | Data warehousing High performance analytics Columnar storage Massively parallel processing (MPP) Integration with data visualisation tools Security and compliance | Data analytics, business intelligence |
| AWS Kinesis data streams for Big Data processing | Scalable Big Data solutions Suitable for data lake architecture |
Data analytics and data predictions |
| Amazon Aurora for large scale OLTP applications | High performance, MySQL, and PostgreSQL compatible relational database Automated backups and scaling Low latency read replicas Data replication across multiple availability zones Security and compliance |
High performance applications, e-commerce, SaaS |
| Amazon Neptune for graphical data store | Managed graph database Fully managed and highly available Supports property graph and RDF graph models SPARQL and Gremlin query languages Encryption at rest and in transit Security and compliance |
Social networks, recommendation systems, knowledge graphs |
| Amazon DocumentDB for document/content managed store (DMS/CMS) | Managed NoSQL database compatible with MongoDB Fully managed and scalable High availability with automatic failover Encryption at rest and in transit Security and compliance |
Content management systems, catalogues, user profiles |
| Amazon Timestream (time series data store) | Managed time series database Scalable and serverless Storage and analytics for time series data Data retention policies Data life cycle management Security and compliance |
IoT applications, industrial monitoring, log data |
| Amazon Quantum Ledger DB (QLDB) |
Managed ledger database Fully managed and scalable Immutable, transparent, and cryptographically verifiable journal Support for SQL-like queries Security and compliance |
Supply chain, financial services, audit trails |
Table 1: AWS database services and their potential use cases
Right-sizing database solutions in AWS
Right-sizing is the process of matching the database resources with your actual workload requirements. This involves analysing your database usage patterns, such as CPU, memory, and I/O, and then selecting the instance type and size that offers the best performance for your workload at the lowest possible cost.
Right-sizing your database solutions in AWS is an essential step in optimising your cloud costs and ensuring that your databases are at peak performance. By selecting the right instance type and size for your workload, you can avoid both overprovisioning and under-provisioning, mitigating unnecessary costs and potential performance bottlenecks.
Right-sizing is important for several reasons.
Cost optimisation: By right-sizing your databases, you avoid paying for unused resources, resulting in significant cost savings on your AWS bill.
Performance optimisation: Under-provisioned databases may struggle to keep up with workloads, leading to performance bottlenecks. Conversely, overprovisioned databases incur costs for unused resources.
Compliance: Certain regulatory requirements mandate that your databases be right-sized. For example, the HIPAA regulations require that healthcare organisations right-size their databases to protect patient data.
How to right-size your databases in AWS
There are several steps you can take to right-size your databases in AWS.
Analyse your database usage patterns: Utilise AWS CloudWatch or other monitoring tools to analyse CPU, memory, I/O, and other key metrics.
Identify your workload requirements: Once you have a good understanding of your database usage patterns, you need to identify your workload requirements. This includes understanding the number of concurrent users, the type of queries that are being run, and the amount of data being stored.
Select the right instance type and size: AWS offers various instance types and sizes. The best instance type and size for your workload will depend on your specific requirements. Use the AWS RDS instance advisor tool to guide your selection of the right instance type and size.
Monitor and adjust: Continuously monitor database performance after right-sizing it. This will help you to identify performance bottlenecks and make necessary adjustments to instance type and size.
Creating testable solutions with AWS Data Lab
Throughout the cloud adoption journey, challenges arise in database migration, data analytics, data lake solution development, and creating real-time data pipelines with machine learning solutions. Addressing these challenges requires expertise and highly skilled resources to manage risks and mitigate them in real-time.
AWS provides engineering support through AWS Data Lab, facilitating accelerated data engineering activities through skilled AWS technical resources and lab facilities. AWS Data Lab is like a black box setup for data engineering activity to develop solutions; it comprises two categories — Build Lab and Design Lab.
Design Lab offers 1.5 to 2 days of engagement with the AWS engineering and technical team to build a solution design for data engineering projects for customers. Build Lab offers 2-5 days of intense workshop engagement with the AWS technical team to develop a working trailblazer for the full-blown architecture/solution design. There are five AWS Data Lab hubs, located in Seattle, New York, Herndon, London and Bengaluru. You can engage with these labs online or through in-person visits.
Using AWS Data Lab, you can develop solutions using AWS Quick Sight, build machine learning solutions for data analytics using SageMaker, develop data lake formation templates, and carry out real-time streaming using AWS EMR for Apache Spark. AWS Data Lab works on three principles:
- Think big to develop a robust data engineering solution
- Start small to create a prototype solution
- Scale fast to ensure all the best practices advised by the AWS technical team are incorporated in the solution design
In-memory data storage services
For Big Data processing like data aggregation or data analytics, we may need high-speed data operations like querying, updating and storing data to physical data stores. With disk-based services, this cannot be achieved to the high speed that we need, as they are physical IO operations. Modern techniques introduced later with first level and second level caching, and then data storage with solid-state devices (SSD) gave better transaction rates and fault-tolerant read-write operations.
However, these could not solve the problem and hence modern cloud architecture introduced in-memory data stores like Memcached, which can store entire databases in memory and does not need any physical IO operation. The ultra-speed design includes an in-memory data store with persistent state using a framework like Redis to handle main memory data for backend synchronisation.
Amazon MemoryDB for Redis is such an in-memory datastore with persistent facility, and is now generally available (GA) across multiple regions. It doesn’t use any disk IO for non-change (read-only) operations, and uses a backend synchronised data store for data change operations like update/add/delete. This design ensures reliable, real-time synchronisation.
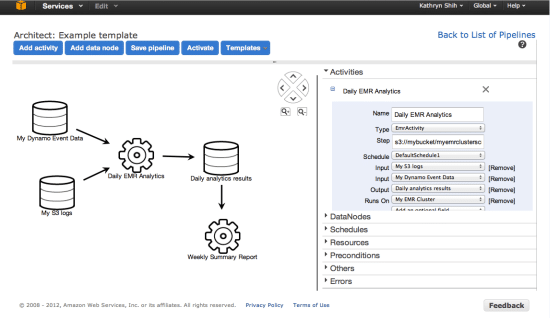
AWS Data Pipeline
AWS Data Pipeline is a fully managed service designed to automate the movement and transformation of data between AWS compute and storage services, as well as on-premise data sources. It helps you build reliable, managed data pipelines to collect, transform, and move your data at scale.
These are the key characteristics of this service.
Orchestrated data movement: AWS Data Pipeline allows the orchestration of data movement between different data stores.
Data transformation: It allows you to transform data using a variety of pre-built AWS services, such as Amazon EMR and Amazon Redshift.
Dependency management: It also allows you to define dependencies between tasks, so that tasks can only run after their dependencies have completed successfully.
Error handling: AWS Data Pipeline provides several features for handling errors, such as retries and notifications.
Monitoring and alerting: It provides monitoring and alerting capabilities that allow you to track the status of your pipelines and receive notifications when there are problems.
AWS Data Pipeline works by orchestrating the movement and transformation of data between different AWS compute and storage services, as well as on-premise data sources. It does this by defining a pipeline, which is a collection of tasks that are scheduled to run at specific times or when certain conditions are met.
Here is a step-by-step overview of how AWS Data Pipeline works.
Create a pipeline: A pipeline definition is created by specifying the data sources, data destinations, and transformation tasks that you want to run. You can use the AWS Data Pipeline console, the SDK, or the CLI to create a pipeline.
Schedule the pipeline: Schedule the pipeline to run on a regular basis or when certain conditions are met. You can specify the frequency of the pipeline execution, as well as the start time and end time of each execution.
Data movement: AWS Data Pipeline transfers data between the data sources and destinations using the appropriate AWS services. For example, it can use Amazon S3 to transfer data between data lakes or Amazon EMR to transform data in batch.
Data transformation: It can transform data using a variety of pre-built AWS services, such as Amazon EMR and Amazon Redshift. You can use these services to clean, filter, and aggregate data before loading it into the destination.
Error handling: AWS Data Pipeline automatically retries failed tasks and sends notifications when there are errors. This ensures that your pipelines are resilient to failures and that data processing is not interrupted.
Monitoring and alerting: It provides monitoring and alerting capabilities that allow you to track the status of your pipelines and receive notifications when there are problems. This helps to identify and troubleshoot issues quickly.
The key components of the AWS Data Pipeline are:
Agent: The agent is a small piece of software that runs on each worker node in the pipeline. It is responsible for executing tasks and communicating with the data pipeline service.
Catalogue: The catalogue is a database that stores information about data sources, data destinations, and transformation tasks. This information is used by the data pipeline service to schedule and execute pipelines.
Jobs: A job is a collection of tasks that are scheduled to run together. Each job has a start time, an end time, and a list of tasks that need to be executed.
Tasks: A task is a unit of work that is executed by the data pipeline service. Each task has a type, such as Copy, Transform, or HiveJar, and a set of parameters.
There are many benefits of using the AWS Data Pipeline.
- Reduced operational overhead: AWS Data Pipeline automates many of the tasks involved in managing data pipelines, such as scheduling, error handling, and monitoring. This can free up your team to focus on more strategic projects.
- Increased reliability: This service is designed to be fault-tolerant and can handle transient failures. This means that your data pipelines will continue to run even if there are occasional problems with the underlying infrastructure.
- Scalability: AWS Data Pipeline can handle large volumes of data and can scale up or down to meet changing needs. This means that you can easily accommodate spikes in data volume without having to worry about infrastructure capacity.
- Security: AWS Data Pipeline uses encryption and access control to protect your data, securing it from unauthorised access and tampering.
- Cost-effectiveness: The pipeline is a pay-as-you-go service, so you only pay for the resources that you use. This can help save money on data processing costs.
Disaster recovery (DR) architecture for AWS database services
Disaster recovery (DR) architecture for AWS database services refers to the strategies and infrastructure that are implemented to protect and restore AWS database services in the event of a disaster. A comprehensive DR plan ensures business continuity and minimises data loss by enabling rapid recovery from disruptive events such as natural disasters, hardware failures, or cyberattacks.
The key components of DR architecture for AWS database services are:
Primary database: The primary database resides in the production environment and handles all read-write operations.
Recovery region: A separate AWS region serves as the recovery site, where a replica or standby database is maintained.
Replication technology: Data replication techniques like Amazon RDS replication or Aurora Global Database are used to synchronise data between the primary database and the recovery site.
Failover mechanism: A failover mechanism is established to automatically switch to the recovery database in case of a disaster.
Monitoring and alerting: Monitoring tools are implemented to track the health and performance of the DR infrastructure, and alerts are configured to notify administrators of potential issues.
Common DR strategies for AWS databases are:
- Backup and restore: Regularly create backups of the primary database and store them in a remote location, such as an S3 bucket or Glacier vault in a different AWS region. In case of a disaster, restore the most recent backup to a new database instance in the recovery region.
- Pilot light: Maintain a read-only replica of the primary database in the recovery region. The replica is kept up-to-date using replication technology, and it can be quickly promoted to a read-write instance if the primary database becomes unavailable.
- Warm standby: Maintain a warm standby database in the recovery region. The standby database is kept in a near-ready state, with data refreshed periodically or on-demand. It can be activated as the primary database with minimal downtime in case of a disaster.
- Multi-site active/active: Operate active-active production databases in multiple AWS regions. Data is replicated between the regions in real-time, allowing failover to either region with minimal disruption.
The choice of DR strategy depends on factors such as recovery time objective (RTO), recovery point objective (RPO), cost, and complexity.
RTO: This is the time acceptable for downtime following a disaster. Backup and restore strategies may have longer RTOs compared to pilot light or warm standby.
RPO: This is the acceptable amount of data loss following a disaster. Warm standby and active/active strategies minimise data loss compared to backup and restore.
Cost: Backup and restore is the most cost-effective DR strategy, while active/active is the most expensive. Pilot light and warm standby offer a balance between cost and performance.
Complexity: Backup and restore is the simplest, while active/active is the most complex to implement and manage.


















{kind=link}