






























































With organisations being overwhelmed by unstructured data, intelligent document processing is the need of the hour.
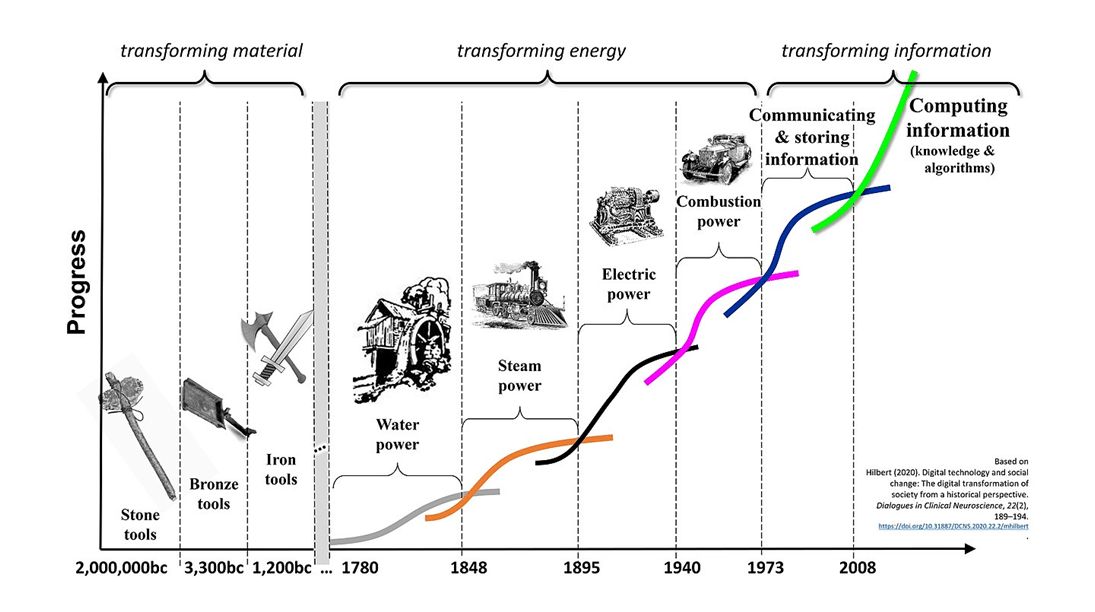
The human race has come a long way over thousands of years of evolution, with the methods employed to pass knowledge and data to future generations evolving from Stone Age writings and paper documents to Xerox machines and the modern-day computers.
There are two interesting dimensions to this data evolution: the physical (paper or analogue) and the digital. Digital data evolution has been ongoing since the 1980s, and today, major businesses have integrated digital elements into their essential functions and processes, creating a hybrid operational model.
However, organisations are still overwhelmed with high volumes of physical and digital documents from multiple sources, often in unstructured formats. This complexity makes it difficult to manage, govern, and use data with external systems.
While some challenges are traditionally addressed by arranging physical documents with manual indexing and extraction techniques, making data analysis simple and scalable is a continuous exploration.
Besides, the affordability and accessibility of digital media storage, coupled with the internet’s growth, make Big Data processing and storage a tough proposition.
Document processing
As information started being stored in document form, ‘search and retrieval’ emerged as a key challenge for both paper and digital mediums. This challenge intensified due to the two facets of digital information: born-digital, and paper digitised through scanning.
Although digital processes have surpassed paper in efficiency, they still grapple with challenges related to unstructured data arriving in high volumes from multiple sources. Let’s take a peek into the journey of document processing through the lens of digital information to understand this better.
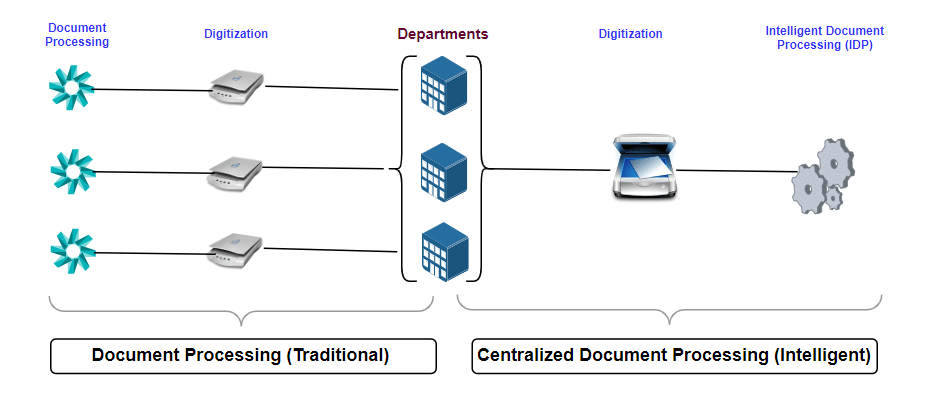
Document processing has evolved from manual indexing to OCR (optical character recognition) technologies and, presently, AI/ML and LLM models. However, managing and making the data consumable by downstream systems remains an uphill task, and scalability is an area for continuous improvement.
Intelligent document processing
To address traditional document processing challenges, intelligent document processing (IDP) has taken the driver’s seat in recent years. The operational efficiencies achieved so far are encouraging, and IDP is able to handle the format and scale issues well. So, what is IDP, and how does it differ from the traditional OCR technologies?
Transitioning from paper-based to scanned digitised copies poses challenges in searching, which are addressed through metadata tagging (also called indexing). Additionally, OCR enabled technology allows text extraction, simplifying full-text keyword searches. Though OCR is a subset of the broader computer vision, its text-based focus makes it an immediate saviour for intense document processing activities.
OCR technologies are mostly template-based, and are not mature enough to deal with unstructured formats. They extract text from images; however, they cannot do many other tasks like classifying and validating the extracted data. Also, they can be template-based and use little/no AI technologies, and hence there is no room for improving the accuracy over time. Overall, this is more of an approach to reduce labour than providing better analytics/insights for continuous improvement.
Identifying gaps in OCR technologies shaped the need for IDP. IDP, with AI/ML as the core technology, facilitates continuous learning and improvement, enhancing accuracy. Compared to OCR, IDP can automate 80% to 85% of the documents, with rare exceptions requiring human intervention. IDP not only leverages OCR results as an input but goes beyond, producing more matured results. It has proven handy in enhancing process automation, particularly in high-volume industries like financial services and healthcare.
As per recent predictions, the IDP market is poised to touch US$ 12.81 billion by 2030, growing at a CAGR of 32.9% during the period 2023-2030.
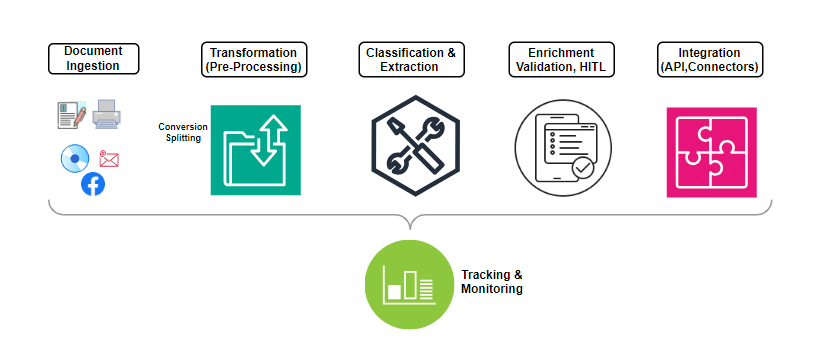
The typical steps involved in IDP processing include:
Document ingestion: This supports many formats with the flexibility to create preprocessors to convert unsupported formats into supported ones when needed. OCR can be leveraged to detect text, including hand-written text, and bulk processing of documents in batches is seamless with IDP.
Transformation: Data may be in different formats or may need some massaging prior to putting it up for processing. This can be as simple as converting the input files from one format to another, or enhancing or enriching the quality of the scanned image, etc.
Document classification: By training the models on the expected document structure and content, document classification can be achieved easily. If documents are bundled together, a splitter logic can segregate them prior to the classification step.
Machine learning techniques can be implemented either manually or automatically (AutoML). The latter automates some machine learning steps like algorithm selection and hyper-parameter tuning, allowing data scientists to focus on more complex problems.
Data extraction: The next important step is to extract data from the already classified document. The extraction can range from simple printed text (structured) to complex unstructured tabular content. A simple model may not always suffice, and a ‘divide and conquer’ approach, stitching individual models together into a composite model, provides a holistic output. By augmenting NLP, the named entities (names, locations, etc) can be easily identified and extracted seamlessly.
Data enrichment: Extracted data can be massaged and enriched to suit the formats required by downstream or other external systems. There are many scenarios where post-processing can come handy including normalising tables, cleaning content by removing unwanted characters, etc.
Human-in-the-loop (HITL): HITL provides ways and means of reviewing, validating, and correcting the data through human intervention when the machine is not confident about the extraction. An intuitive UI will help the labellers tasked with this responsibility. Every machine learning project needs to factor in estimates to accommodate a percentage split between straight-thru processing and HITL.
Overall, IDP has enhanced accuracy levels, making document processing more seamless without compromising on scale. However, for IDP to work optimally, more sample data and associated model training are necessary. Accessing sample data may not be easy and straightforward, but this can be compensated to some extent by relying on synthetic data.
How LLMs augment the capabilities of IDP
Large language models (LLMs) help advance document processing as they can simply work by providing the right prompts without explicit training. There is no need for sample data as they are pre-trained on the enterprise corpus of data. However, they are more suitable for key-value (KV) scenarios. When there is a combination of KV pairs along with complex unstructured content, a composite model that blends traditional ML models with LLMs can be effective.
In spite of all this, there is still a chance of hallucinations. The latest developments in the form of RAG (retrieval-augmented generation) have introduced a next level of validation through external validation(s), amplifying the LLM output by providing a better overall response.
How to choose the right IDP platform
With numerous choices in the market for IDP, choosing the right one can be challenging. The following criteria/features can help in making a selection.
- Intuitive low code interface/platform
- Flexibility to choose vendor-agnostic OCR engine
- Ability to have vendor-agnostic cloud service provider
- Option to create/configure document taxonomies
- Multiple language support
- Support for auto ML models
- Augment ML models with LLMs and RAG features
- Ability to continuously up-train for better accuracy
- Option for exception handling through human operators in the loop
- Seamless integrations and connectors
- Ability to create complex workflows allowing effortless collaborations
- Processing of large document batches
- Support for retention policies/rules
- Dashboards and reporting
IDP value proposition
Documents are pivotal for any business function, cutting across domains like finance/banking, healthcare, public sector, insurance, retail, etc. Important use cases include mortgage, invoice processing, claims, KYC (know your customer), EMR/EHR, etc.
Traditionally, document processing is more siloed at the department level. To derive better results and have cross-pollination of best practices, it is recommended to converge this into a centralised document processing shared service. IDP comes in handy to promote this by sharing models and best practices, enabling reusability across the organisation.
Overall, it is not a one-size-fits-all kind of setup. Document processing can be done based on factors like complexity, volume, etc. If the content is structured with a standard format/layout, then an OCR-based solution should be sufficient. However, if the content is complex, mapped to different document types, with a need for extraction of hand-written text along with a greater emphasis on accuracy, then AI-ML based intelligent document processing makes a perfect fit.
To ensure the most informed decision, assess and evaluate an organisation’s document processing needs. Consider factors like budget, timelines, and desired accuracy levels to arrive at the better option suitable for the organisation.


















{kind=link}