





























































Using AI to identify and track pedestrians in real-time is helping autonomous vehicles become smarter and safer than ever before. Here’s an outline of an indigenous project developed to do just that using YOLOv5, a deep learning object detector.
On a cool evening in Bangalore, as I was coming out of my office, I saw an electric shuttle come to a smooth halt as a child dashed across a crosswalk inside our tech park. No driver. No delay. Just action. That’s when I realised that autonomous vehicles aren’t just futuristic concepts anymore—they’re real and learning how to navigate the very same unpredictable streets that we humans do every day when driving our vehicles.
Behind this seamless stop was an intelligent system trained to spot, track, and respond to every human movement. So let’s talk about what brought about this vision system’s intelligence to life—a system that combines YOLOv5, one of the fastest and best deep learning object detectors, with SORT, a lightweight yet powerful tracking algorithm. Together, these allow machines to detect, recognise and follow pedestrians in each frame as they manoeuvre using the sensor systems they are equipped with.
This isn’t just a lab demo or a theoretical model that we are talking about here. This is a real-world implementation that I have seen and helped to develop. It’s been built with excellently engineered deployment in mind—starting from the way it selects the visual clutter to the way it assigns unique IDs to every person who appears in its view.
And, most importantly, this intelligent AI system prioritises human safety.
The challenge of human movement
While vehicles follow lanes and signals, pedestrians generally don’t. They hesitate sometimes, may reverse their course, may get distracted by phones, or emerge from occluded spaces like other parked vehicles or some tree lines. Tracking such unpredictable movement requires more than just detection—it needs some kind of memory.
This is where YOLOv5 and SORT excel. YOLOv5 helps to identify all objects present in a scene, and isolates only the ‘person’ class from these. SORT connects the dots between frames, maintaining a person’s identity across both space and time, even when two individuals cross paths or temporarily vanish from view.
Inside the project workflow
You can imagine this system as a digital eye that is connected to a short-term memory.
- YOLOv5 detects every human in the video feed.
- These detections are then filtered to retain only the pedestrian class.
- SORT uses the detections captured to assign each pedestrian with a consistent tracking ID.
- In the end, as an output, a bounding box is drawn around each pedestrian class object in the video, along with persistent labelling.
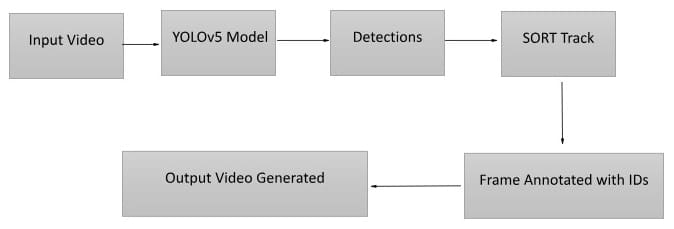
Each frame thus becomes a story, not just about who is there, but also about where they’re going. The complete architecture of this tracking system is described in Figure 1, highlighting how each module interacts from the moment a video is captured to the point where tracked results are rendered.
The code behind the magic
Here’s a peek into the core logic, built in Python using PyTorch and OpenCV:
from sort import Sort
import cv2, torch, numpy as np
# Think of this as giving the system a pair of trained eyes — YOLOv5 is a fast, accurate object detector.
model = torch.hub.load(‘ultralytics/yolov5’, ‘yolov5s’, pretrained=True)
# This tracker is what gives the system memory — it helps remember who’s who across frames.
tracker = Sort()
# Open the input video — one frame at a time, like flipping through a digital flipbook.
cap = cv2.VideoCapture(‘video.mp4’)
# Go through the video frame by frame
while cap.isOpened():
ret, frame = cap.read()
if not ret: break # End of video
# Pass the current frame through the object detection model
results = model(frame)
detections = []
# Loop through everything YOLO detected in this frame
for *xyxy, conf, cls in results.xyxy[0]:
if int(cls) == 0: # We’re only interested in people, not cars, bikes, or dogs.
x1, y1, x2, y2 = map(int, xyxy)
# Store the bounding box coordinates and confidence for each detected person
detections.append([x1, y1, x2, y2, float(conf)])
# Hand over the list of detections to the tracker — it figures out which ID to assign or keep
tracked_objects = tracker.update(np.array(detections))
# For each person being tracked, draw their box and label on the frame
for x1, y1, x2, y2, track_id in tracked_objects:
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
# Show their ID just above the bounding box — so we know who’s who as they move
cv2.putText(frame, f’ID: {int(track_id)}’, (int(x1), int(y1)-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
This code doesn’t just spot pedestrians. It tracks them like a human driver would—focusing, remembering, and anticipating.
To understand what the system sees initially, Figure 2 depicts a raw video frame that hasn’t yet been processed or annotated.

Figure 3 shows how the same frame looks after being processed by the YOLOv5 detector and SORT tracker, with unique IDs and bounding boxes assigned.
The pedestrian tracking system starts by explaining to the machine how exactly to ‘see’ its surroundings, which is achieved by YOLOv5, a deep learning model that is trained to recognise various object classes in a particular scene.
The focus is solely on the pedestrian class, and the unpredictable and crucial elements present in road environments. First, the input video is handled in a frame-by-frame sequence; then this model identifies all visible objects and filters out all non-human detections.
This step ensures that only the pedestrian class is sent to the next step, which is tracking. The SORT algorithm now handles the functioning as the system’s short-term memory companion. It assigns a unique ID to all the detected pedestrian class objects and maintains this identity across all the frames, even if the individuals in the frame try to disappear or overlap with other objects. This temporal continuity allows the system to follow the path of each pedestrian even if they move through the frame, just like a normal human driver should be tracking someone walking across a street while driving.
After analysing each frame, the AI system overlays bounding boxes and ID tags onto the video in the system, providing a more clear and persistent view of the pedestrian movement across the frames. This output video is then compiled into a new annotated video format that visualises detection and has an intelligent tracking component.
This pipeline is truly exceptional because of its real-time capability; it sees the pedestrians and remembers them, as well as reacts to their movements quickly. This makes the pipeline adequate for deployment in real live systems, and can be integrated into autonomous vehicles or used for smart surveillance purposes. Ultimately, this system works like a human driver. Its real-world use cases include autonomous vehicles, urban surveillance, smart crosswalks and fleet monitoring.
Edge performance and optimisations
Performance is non-negotiable in this project. Real-time systems in the industry can’t afford lag, i.e., high latency.
To ensure a very smooth 30 FPS playback, YOLOv5s (the smaller but faster version of the model) has been used. The computation has been offloaded to the GPU that used torch.device(‘cuda’) where available. Frame size has been trimmed and used at almost half-precision (that is float16) inference.
But for environments that don’t have GPU access, this model still works on a CPU, albeit at a lower frame rate.
Real-world challenges
There are real-world challenges when we start integrating such AI systems in real cars running on the road with uncontrolled environmental conditions.
Lighting: Early morning shadows and low-light environments are both hurdles. In this project, this challenge was handled by a preprocessing step that used histogram equalisation and contrast adjustment techniques.
Occlusion: This occurs when people overlap or cross paths. The major problem here is that their IDs may get switched. The SORT algorithm can handle mild occlusions but falters when faced with some complex crowd movement scenarios. So, in future updates, there are plans to incorporate the DeepSORT algorithm, which adds appearance-based embedding for higher accuracy.
From Python script to AV module
What makes this project more than just a coding experiment is its extensibility. You can integrate it into a larger autonomy stack. Here’s how:
|
Component |
Integration |
|
YOLOv5 |
Detection backbone |
|
SORT |
Realtime multi-object tracking |
|
ROS / WebRTC |
Live streaming into navigation stack |
|
TensorRT |
Edge deployment for NVIDIA Jetson or Orin |
|
Flask API |
Serves frame results to front-end dashboards |
Remember, you’re not building an AI toy—you’re contributing to the digital senses of a vehicle. This project is special not because of the maths behind it but the human instinct being replicated using an AI vision system. When a 6-year-old starts crossing a zebra line, a human driver slows down. This system allows a machine to do the same, not because it was told to, but because it learned to observe, identify, and track the human in its path.
The last step before deployment
You’ve got a working model. Now what?
- I recommend you test it on multiple city datasets (e.g., CityPersons, ETHZ, etc).
- Further finetune it for local traffic behaviour as well.
- You can also add alert mechanisms, for either audio or in-vehicle heads-up display.
- For more advancement you can integrate it with braking systems or steering logic.
And that’s the journey so far…
You don’t need to be Tesla or Waymo to contribute to safer streets. Sometimes, all you need is a laptop, a good model, and a genuine concern for human life.
This project is my step in that direction—and, perhaps, it can be yours too.















