





























































Fedora 20 makes it easy to install Hadoop. Version 2.2 is packaged and available in the standard repositories. It will place the configuration files in /etc/hadoop, with reasonable defaults so that you can get started easily. As you may expect, managing the various Hadoop services is integrated with systemd.
Setting up a single node
First, start an instance, with name h-mstr, in OpenStack using a Fedora Cloud image (http://fedoraproject.org/get-fedora#clouds). You may get an IP like 192.168.32.2. You will need to choose at least the m1.small flavour, i.e., 2GB RAM and 20GB disk. Add an entry in /etc/hosts for convenience:
192.168.32.2 h-mstr
Now, install and test the Hadoop packages on the virtual machine by following the article, http://fedoraproject.org/wiki/Changes/Hadoop:
$ ssh fedora@h-mstr $ sudo yum install hadoop-common hadoop-common-native hadoop-hdfs \ hadoop-mapreduce hadoop-mapreduce-examples hadoop-yarn
It will download over 200MB of packages and take about 500MB of disk space.
Create an entry in the /etc/hosts file for h-mstr using the name in /etc/hostname, e.g.:
192.168.32.2 h-mstr h-mstr.novalocal
Now, you can test the installation. First, run a script to create the needed hdfs directories:
$ sudo hdfs-create-dirs
Then, start the Hadoop services using systemctl:
$ sudo systemctl start hadoop-namenode hadoop-datanode \ hadoop-nodemanager hadoop-resourcemanager
You can find out the hdfs directories created as follows. The command may look complex, but you are running the hadoop fs command in a shell as Hadoop’s internal user, hdfs:
$ sudo runuser hdfs -s /bin/bash /bin/bash -c hadoop fs -ls / Found 3 items drwxrwxrwt - hdfs supergroup 0 2014-07-15 13:21 /tmp drwxr-xr-x - hdfs supergroup 0 2014-07-15 14:18 /user drwxr-xr-x - hdfs supergroup 0 2014-07-15 13:22 /var
Testing the single node
Create a directory with the right permissions for the user, fedora, to be able to run the test scripts:
$ sudo runuser hdfs -s /bin/bash /bin/bash -c "hadoop fs -mkdir /user/fedora" $ sudo runuser hdfs -s /bin/bash /bin/bash -c "hadoop fs -chown fedora /user/fedora"
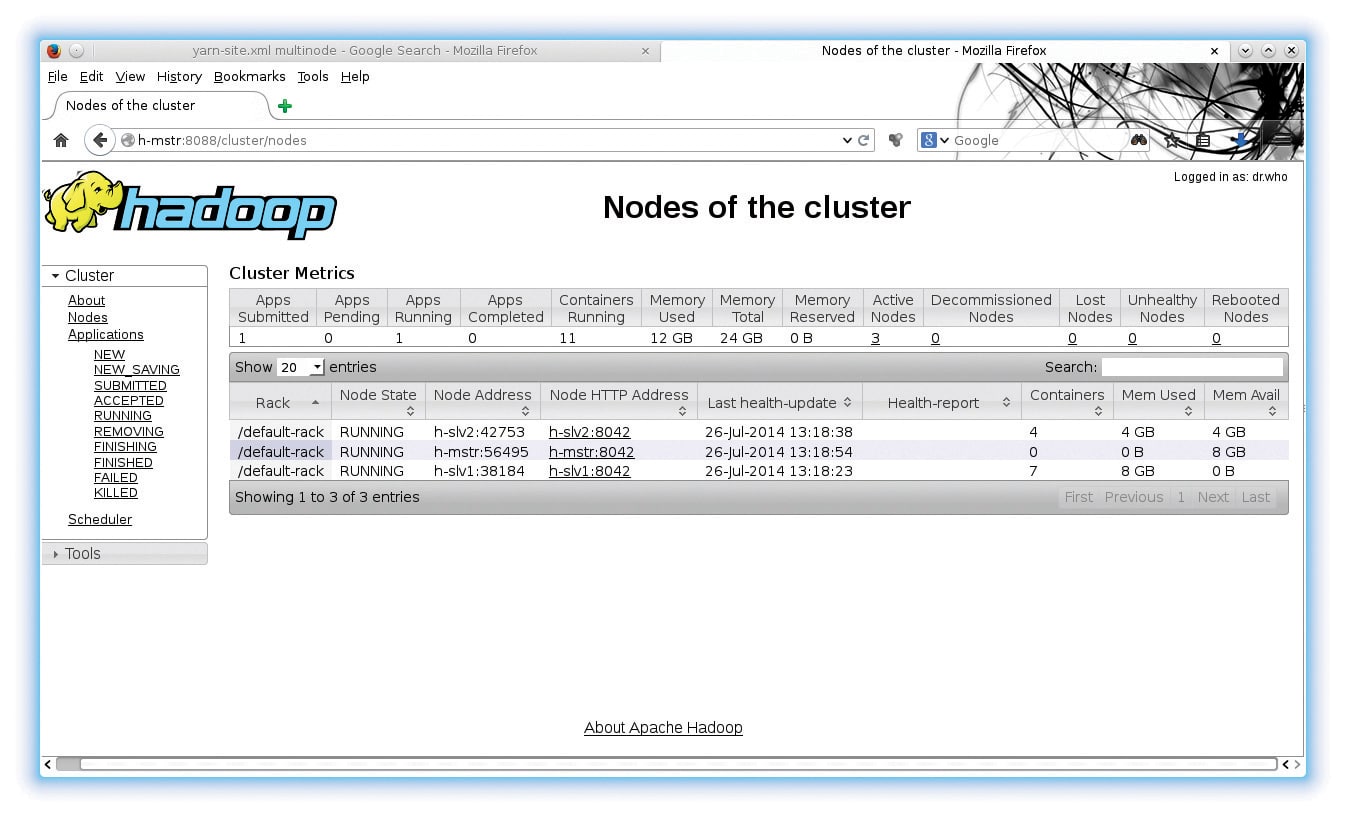
Disable the firewall and iptables and run a mapreduce example. You can monitor the progress at http://h-mstr:8088/. Figure 1 shows an example running on three nodes.
The first test is to calculate pi using 10 maps and 1,000,000 samples. It took about 90 seconds to estimate the value of pi to be 3.1415844.
$ hadoop jar /usr/share/java/hadoop/hadoop-mapreduce-examples.jar pi 10 1000000
In the next test, you create 10 million records of 100 bytes each, that is, 1GB of data (~1 min). Then, sort it (~8 min) and, finally, verify it (~1 min). You may want to clean up the directories created in the process:
$ hadoop jar /usr/share/java/hadoop/hadoop-mapreduce-examples.jar teragen 10000000 gendata $ hadoop jar /usr/share/java/hadoop/hadoop-mapreduce-examples.jar terasort gendata sortdata $ hadoop jar /usr/share/java/hadoop/hadoop-mapreduce-examples.jar teravalidate sortdata reportdata $ hadoop fs -rm -r gendata sortdata reportdata
Stop the Hadoop services before creating and working with multiple data nodes, and clean up the data directories:
$ sudo systemctl stop hadoop-namenode hadoop-datanode \ hadoop-nodemanager hadoop-resourcemanager $ sudo rm -rf /var/cache/hadoop-hdfs/hdfs/dfs/*
Testing with multiple nodes
The following steps simplify creation of multiple instances:
- Generate ssh keys for password-less log in from any node to any other node.
$ ssh-keygen $ cat .ssh/id_rsa.pub >> .ssh/authorized_keys
- In /etc/ssh/ssh_config, add the following to ensure that ssh does not prompt for authenticating a new host the first time you try to log in.
StrictHostKeyChecking no
- In /etc/hosts, add entries for slave nodes yet to be created:
192.168.32.2 h-mstr h-mstr.novalocal 192.168.32.3 h-slv1 h-slv1.novalocal 192.168.32.4 h-slv2 h-slv2.novalocal
Now, modify the configuration files located in /etc/hadoop.
- Edit core-site.xml and modify the value of fs.default.name by replacing localhost by h-mstr:
<property> <name>fs.default.name</name> <value>hdfs://h-mstr:8020</value> </property>
- Edit mapred-site.xml and modify the value of mapred.job.tracker by replacing localhost by h-mstr:
<property> <name>mapred.job.tracker</name> <value>h-mstr:8021</value> </property>
- Delete the following lines from hdfs-site.xml:
<!-- Immediately exit safemode as soon as one DataNode checks in. On a multi-node cluster, these configurations must be removed. --> <property> <name>dfs.safemode.extension</name> <value>0</value> </property> <property> <name>dfs.safemode.min.datanodes</name> <value>1</value> </property>
- Edit or create, if needed, slaves with the host names of the data nodes:
[fedora@h-mstr hadoop]$ cat slaves h-slv1 h-slv2
- Add the following lines to yarn-site.xml so that multiple node managers can be run:
<property> <name>yarn.resourcemanager.hostname</name> <value>h-mstr</value> </property>
Now, create a snapshot, Hadoop-Base. Its creation will take time. It may not give you an indication of an error if it runs out of disk space!
Launch instances h-slv1 and h-slv2 serially using Hadoop-Base as the instance boot source. Launching of the first instance from a snapshot is pretty slow. In case the IP addresses are not the same as your guess in /etc/hosts, edit /etc/hosts on each of the three nodes to the correct value. For your convenience, you may want to make entries for h-slv1 and h-slv2 on the desktop /etc/hosts file as well.
The following commands should be run from Fedora on h-mstr. Reformat the namenode to make sure that the single node tests are not causing any unexpected issues:
$ sudo runuser hdfs -s /bin/bash /bin/bash -c "hadoop namenode -format" Start the hadoop services on h-mstr. $ sudo systemctl start hadoop-namenode hadoop-datanode hadoop-nodemanager hadoop-resourcemanager
Start the datanode and yarn services on the slave nodes:
$ ssh -t fedora@h-slv1 sudo systemctl start hadoop-datanode hadoop-nodemanager $ ssh -t fedora@h-slv2 sudo systemctl start hadoop-datanode hadoop-nodemanager
Create the hdfs directories and a directory for user fedora as on a single node:
$ sudo hdfs-create-dirs $ sudo runuser hdfs -s /bin/bash /bin/bash -c "hadoop fs -mkdir /user/fedora" $ sudo runuser hdfs -s /bin/bash /bin/bash -c "hadoop fs -chown fedora /user/fedora"
You can run the same tests again. Although you are using three nodes, the improvement in the performance compared to the single node is not expected to be noticeable as the nodes are running on a single desktop.
The pi example took about one minute on the three nodes, compared to the 90 seconds taken earlier. Terasort took 7 minutes instead of 8.
Note: I used an AMD Phenom II X4 965 with 16GB RAM to arrive at the timings. All virtual machines and their data were on a single physical disk.
Both OpenStack and Mapreduce are a collection of interrelated services working together. Diagnosing problems, especially in the beginning, is tough as each service has its own log files. It takes a while to get used to realising where to look. However, once these are working, it is incredible how easy they make distributed processing!
















