






























































Programming is basically telling a computer what to do. Traditional programming practices assume that you understand the problem clearly and, using that understanding, will write a series of clear instructions to solve that particular problem or to do a particular task. Examples for these types of problems/tasks are many; in fact, most of the programs are written with very clear expectations of input, output and a neat algorithm for the process for instance, sorting of numbers, removing a particular string in a text document, copying a file, etc.
However, there is a certain class of problems for which traditional programming or problem-solving methods will not be of much use. For example, lets assume that you have about 50,000 documents that have to be classified into specific categories like sports, business and entertainment without manually going through each of them. Or consider another example of searching for a particular object in thousands of images. In the latter case, the object could be photographed in a different orientation, or under various lighting conditions. How can you tell which images contain the object? Another very useful example is of building an online payment gateway and wanting to prevent fraudulent transactions. One way is to identify signs of potentially fraudulent transactions and triggering alerts before the transaction is complete. So how would you predict this accurately without creating unnecessary alarms?
As you can easily guess, it’s not possible to write very precise algorithms for each of these problems. What we can do is to build systems that work like a human expert. A doctor can tell what disease a particular patient has by looking at the test reports. While it’s not possible for him to make an accurate diagnosis 100 per cent of the time, he will be correct most times. Nobody programmed the doctor, but he learned those things by studying and by experience.
What we need is a system that can learn from experience, even when we can not program it to do specific tasks. What we do is, we show a large number of examples and the computer will be programmed to learn from this large pool of information, after which itll be ready to predict/do the required task. This is what machine learning is all about. While the example of the doctor may be slightly different from actual machine learning, the core idea of machine learning is that machines can learn from large data sets and they improve as they gain experience.
Machine learning and mathematics
Many machine learning algorithms basically attempt to approximate an unknown mathematical function, and most of these algorithms are mathematical in nature. As data contains randomness and uncertainty, well have to apply concepts from probability and statistics. In fact, machine learning algorithms are so dependent on concepts from statistics that many people refer to machine learning as statistical learning. Apart from statistics, another important branch of mathematics thats very much in use is linear algebra. Concepts of matrices, solutions for systems of equations and optimisation algorithms all play important roles in machine learning.
Machine learning and Big Data
These days, machine learning is closely associated with Big Data. Big Data refers to large volumes of stored data, and it always makes sense to use. Lets look at a specific case to understand what exactly I mean. Lets suppose that you’ve been collecting customers transaction data on an e-commerce platform. The volume of data collected can easily grow and eventually reach a level at which it gets categorised as Big Data, along with other data youre storing. Now, there are primary uses of this data to check the status of that customer order, to calculate profits/losses of the business, for accounting purposes and some other routine operational/technical purposes. Apart from these, businesses also want to make use of this data in a unique way. Some people have a specific word for this analytics. While straightforward arithmetic can give answers on profits/losses, total expenditure, total inventory, etc, and slightly advanced data manipulation can slice and dice the information available, we would still want to go beyond this basic reporting and identify patterns that are not obvious. We may also want to build predictive models.
Different machine learning algorithms
There are basically two types of machine learning - supervised learning and unsupervised learning. Supervised learning refers to data with labels, examples of which are shown below:
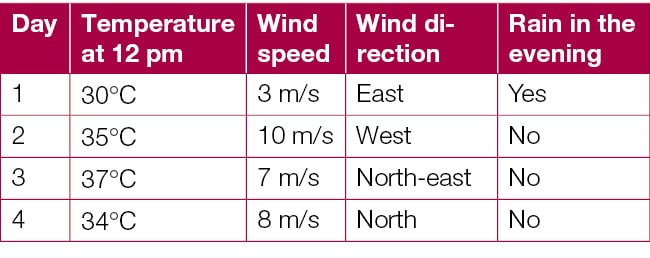
Lets assume that we have to predict if it rains in the evening, using temperature and wind data. Whether it rains or not is stored in the column Rain in the evening, which becomes the label. Here, temperature, wind speed and wind direction become predictors or input variables and Rain in the evening becomes the output variable.
The algorithms that learn from such data are called supervised learning algorithms. While some data can be extracted/generated automatically, like in a machine log, often it may have to be labelled manually, which would increase the cost of data acquisition.
Examples for supervised learning algorithms include linear regression algorithms, Naïve-Bayesan algorithms, k-nearest neighbour, etc.
If the data doesnt have labels, it becomes an unsupervised learning algorithm. Some examples are k-means clustering, principal component analysis, etc.
We can also classify machine learning algorithms using a different logic regression algorithms and classification algorithms. Regression algorithms are machine learning algorithms that actually predict a number like the following days temperature, the stock markets closing index, etc. Classification algorithms are those that can classify an input, like whether it will rain or not; if the stock market will close positive or negative; if it is disease x, disease y, or disease z, and so on.
Tools of machine learning
Its important to understand and appreciate the fact that machine learning algorithms are basically mathematical algorithms and we can implement them in any language we like. It can be C, PHP, Java, Python, or even JavaScript. But the one I personally like and use a lot is the R statistical language. There are many popular machine learning modules or libraries in different languages. Weka is powerful machine learning or data mining software written in Java and is very popular. Scikit-learn is popular among Python developers. One can also go for the Orange machine learning toolbox available in Python. While R comes with many basic statistical packages or modules, there are different packages like e1071, Randomforest, Ann, etc, depending on different machine learning algorithms. Apache Mahout is a scalable machine learning algorithm typically for Big Data systems. While Weka is really powerful, it has some licence issues for commercial use. You can also use Java-ML, a Java machine learning algorithm. Though development appears to have stopped, it is a decent library worth trying and with enough documentation/tutorials to get started easily. I would recommend people with advanced needs to explore the deep learning algorithms.

















{kind=link}