






























































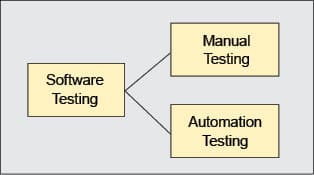
The project development stages of any Web application always end with the testing phase. Testing can be of two types – manual and automated.
Manual testing: This is the oldest method of finding errors in your software. The main goal of manual testing is to ensure that the application is error-free and is working in accordance with the functional requirements of the system. The most common example of manual testing is Black Box and White Box testing.
Automated testing: Software test automation uses special tools to control the execution of test cases, and compares the actual results with the expected results. Usually, regression tests are the ones that are automated. Automated testing is used in cases where there is repetition of code and where requirements do not change frequently.
How testing is automated
We can automate our testing process with the help of a simple scripting language and any automated software application. The various steps to achieve automated testing are mentioned below:
1. Recognising the areas in your code that need to be tested. If that code is repeated very often, then you sure do need automated testing.
2. Choosing the correct tool for automated testing.
3. Writing proper scripts that will cover large portions of your software.
4. Developing test suites to make sure that the automated test cases run one after the other.
5. Executing the scripts.
6. Building result reports.
7. Recognising the problems and trying to resolve them.
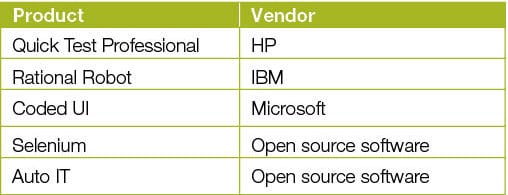
Selenium
Selenium is an open source tool for testing Web apps. It was initially created by ThoughtWorks and now boasts of a dynamic group of designers and clients.
A sample test case
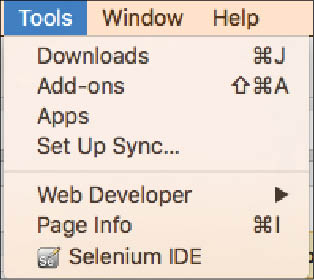
The Selenium IDE is available under Tools, in the Menu bar of the Firefox browser, as an add-on (see Figure 2).
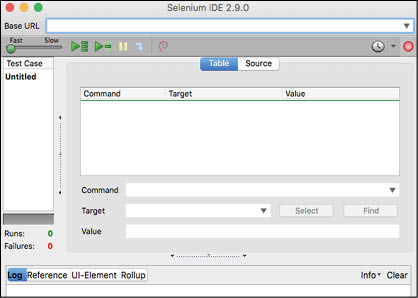
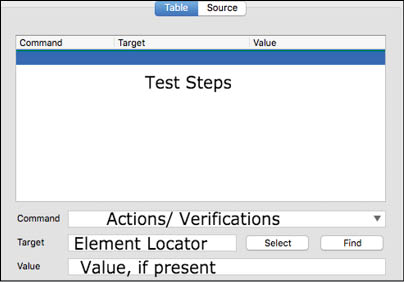
A window of the Selenium IDE pops up with a blank table of a test case (Figure 3).
As we can see in the window, there is a red dot in the top right corner, which helps in recording the test case. The Play options are also available in the top left corner to run the test case. The Base URL talks about the link on which the test case should be applied. We can also slow down or hasten up the testing process. The login at the bottom gives the log information, step wise, about the success or failure of the test case.
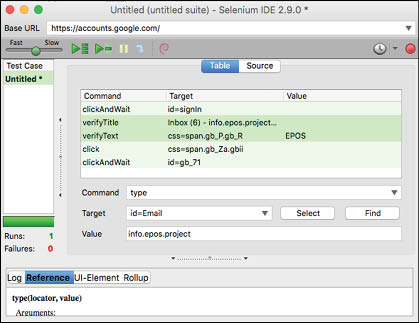
As we can see in this example, we will demonstrate the usage of the Selenium IDE with the Google sign-in process. The input given as the username is info.epos.project and the password is info_epos_project. Keep the ‘stay signed in’ option off and try to access the account while recording the test case in the background.
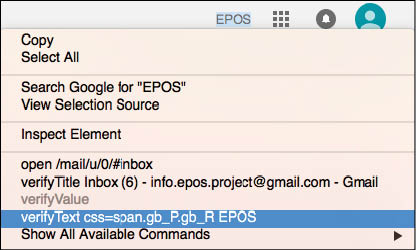
Just after the sign-in, we can also verify the user name present in the location shown in Figure 4, to verify whether the login of the correct user account has taken place or not. This can be done by selecting the name (in the above example, the text is –EPOS), right-clicking on the selected content and then clicking on the ‘verifyText’ (or it could be ‘verifyTextPresent’ in your version of Selenium) option from the menu. Here, CSS is used to identify the element although ID is more preferred as it would be unique throughout the page. Then sign out. With this, one phase of the test case – the recording – is over.
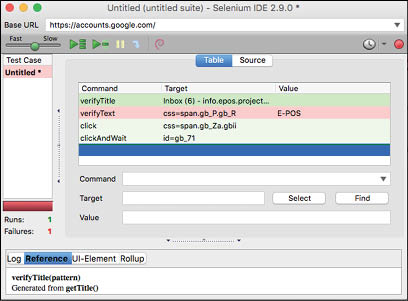
Once the recording is complete, in the table section of the Selenium IDE, the Command column displays the commands (or the actions, to be more precise) which were performed while recording the test case. The Target column displays the ID of the element we have dealt with in the Base URL mentioned. Element ID is unique for each element in a single page. Values mentioned here define the values that the ID must contain to get a successful test case.
At the point when the test is running, every command is highlighted on execution. The colour state of the steps turns green or red, to demonstrate achievement or failure, respectively. The dark green shading is for the confirmed content.
After the entire test is finished, the test is stamped as red or green in the suite. The test also generates the log information about the success or failure of the command, with an error message.
Red indicates failure and green indicates success.
There are multiple options available to save the test suite or the test case in various formats like Ruby RSpec, Ruby Test::Unit, Java JUnit, Java TestNG or C# NUnit.
Pillars of the Selenium IDE
Now let’s understand the functions we just used in the example. There are three pillars that support the Selenium IDE.
1. Action: This refers to the operations that are being performed with the UI.
2. Assessors/Assertion: This helps in verification of the data we get from the UI.
3. Locator strategy: This helps to find the element that will perform the operation, from the UI.
Presently, the Selenium IDE has an exceptionally developed library with a lot of actions, assertion/assessors and locator strategies.
Creating user-defined functions for test cases – user extensions
Typically, every once in a while, we have to add some more features for our venture. In such circumstances, we can grow this library by including custom extensions, called ‘user extensions’.
Let’s assume we require an action that can capitalise the content before filling it in a Web component. We don’t have any action to capitalise the content in the default action library. In this case, we can make our own ‘user extension’. In this instructional exercise, let’s figure out how to make a user extension to change text to upper case.

Need for user extensions
To generate the user extension, one needs to learn the basics of JavaScript. We have to generate JavaScript functions, and add these to the Selenium object prototype and PageBot object prototype to create their own user extensions.
How does the Selenium IDE recognise the user extension?
After adding the user extension to the Selenium IDE, when we open it, all the extensions in the JavaScript prototype get loaded and the Selenium IDE recognises them by their name.
Creating a user extension
Step 1 – Action: All actions are to begin with ‘do’; for example, in our case, the action could be doTextUpperCase. The Selenium IDE will automatically generate the wait method when we include the extension. So, for this situation, when we initiate the doTextUpperCase action, the IDE will generate a corresponding wait method as TextUpperCaseAndWait, which will accept two arguments.
Example:
Selenium.prototype.doTextUpperCase = function(locator, text) {
var element = this.page().findElement(locator);
text = text.toUpperCase();
this.page().replaceText(element, text);
};
Step 2 – Assessors/Assertion: All assessors are prefixed by ‘get’ or ‘is’; for example, getValueFromCompoundTable and isValueFromCompoundTable. Two arguments, one for the target field and another for the value field of the test case, are required.
For each assessor, there will be the corresponding verification functions prefixed by ‘verify’ and ‘assert’ and the wait function prefixed by ‘waitFor’.
Example:
Selenium.prototype.assertTextUpperCase = function(locator, text) {
var element = this.page().findElement(locator);
text = text.toUpperCase();
var actualValue = element.value;
Assert.matches(expectedValue, actualValue);
};
Selenium.prototype.isTextEqual = function(locator, text) {
return this.getText(locator).value===text;
};
Selenium.prototype.getTextValue = function(locator, text) {
return this.getText(locator).value;
};
Step 3 – Locator strategy: If we wish to generate our own method to locate an element, then we need to extend the PageBot prototype with a method having the prefix locateElementBy. It will take two arguments – the first to locate the string and the second to record where it has to be searched.
Example:
PageBot.prototype.locateElementByUpperCase = function(text, inDocument) {
var expectedValue = text.toUpperCase();
var allElements = inDocument.getElementsByTagName("*");
for (var i = 0; i < allElements.length; i++) {
var testElement = allElements[i];
if (testElement.innerHTML && testElement.innerHTML === expectedValue) {
return testElement;
}
}
return null;
};
Step 4 – Using the user extension:
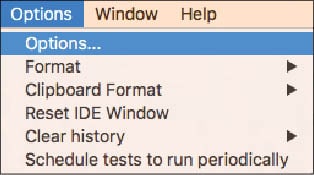
1. Go to Options -> Options in Selenium IDE.
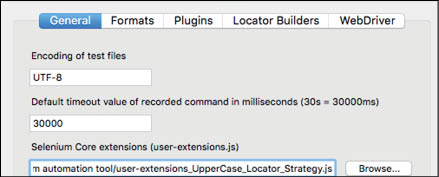
2. Browse the location of the recently created Selenium Core Extension in the general tab of Options.
3. Press OK and restart the IDE.
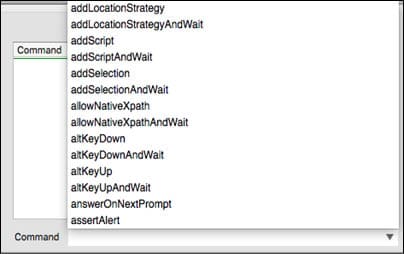
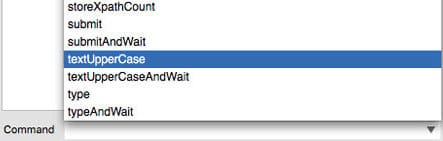
4. One can find the commands called textUpperCase and textUpper CaseAndWait in the command list.
One can get all these extensions and numerous more from the download segment of the SeleniumHQ official website http://docs.seleniumhq.org/download/
While Selenium is no magic tool for the issues challenging the Web application analyser, it handles a significant amount of the problems. Selenium is worth a look for those requiring a capable Web testing tool.

















{kind=link}