

Kubernetes is a production grade open source orchestration system used to deploy, scale and manage containerised applications. It is based on the same principles that allow Google to run billions of containers a week. Read on to know more.
Docker has fundamentally changed the way we build, ship and run our applications. Docker has been a big winner when it comes to portability, primarily due to the fact that it is able to package an application and all its dependencies into a format that is easy to build, distribute and run. The availability of Docker runtime on multiple operating systems and the widespread support for it, across both cloud infrastructure providers and operating system vendors, has finally made it easier to achieve portability. This functionality has been a true enabler of DevOps, where the developers and the operations team can do a smooth handover.
So, while Docker with its easy-to-use tool set has made it convenient to launch a few containers on a single host, at best, the tooling is good enough for a few host machines running several containers on it. But when it comes to running large sites, one would probably need several large clusters, running thousands of nodes, if not more. This is not a trivial software problem. In fact, it lies in the realm of distributed software, which makes it a challenge to run Docker containers at scale. The challenge lies in the areas of managing the installation, rolling out upgrades, monitoring the Docker hosts and containers for their health, scaling up/down the number of containers needed as per the load and more.
From their perspective, it is important that developers do not have to worry about infrastructure and provisioning, even if the applications that they have dockerised need to scale. Similarly, from an operations point of view and, especially from a data centre angle, the days of allocating VMs and running your applications on them are gone. Infrastructure providers cannot run their data centres efficiently by simply spinning up VMs, which may end up not getting fully utilised.
So what we need is orchestration software that provides automated container deployment, scaling and management. In a nutshell, this is what Kubernetes is all about.
A bit of history
Google has been running some of the largest Web properties on the planet. Think of Gmail, Google Docs and you can imagine the millions of users at any given time. To support systems of this nature, Google has spent the last 10-15 years building an advanced infrastructure across the world. Before Docker was unleashed on the world, Google already understood the concept of containers, and has been running a distributed system that allowed the company to service its application requests by running and bringing down containers on demand. This inhouse system in Google was called Borg. It is reported that Google runs billions of containers per week to process requests from some of its largest Web properties like Gmail, Google Docs and others. So once Docker streamlined the containerisation of apps via its container format and tools, Google thought it fit to open its expertise acquired over the last decade in running distributed containerised workloads via a modified version of Borg that would provide a battle-tested orchestration system. Thus Kubernetes was born and has been available as open source for a while.
The Kubernetes ecosystem
The Kubernetes project is available at the GitHub URL https://github.com/kubernetes/kubernetes and has been one of the most active projects over the last 12-18 months. Major infrastructure providers and Linux vendors have supported this project and have been contributing to it. A significant portion of the code being contributed to Kubernetes is from major players like Red Hat, Citrix, IBM and others.
In addition to the core contributors, an entire ecosystem of vendors is evolving around Kubernetes. These vendors are providing a higher layer abstraction around it, offering tools around visualising or managing your Kubernetes clusters, CI/CD workflows and more. This is probably the right time to get into this space since, currently, it is being actively worked on, and it is widely accepted that containers and orchestration tools will be the way we deploy our applications, moving forward.
The need for Kubernetes
So far, we covered some brief points about why we need Kubernetes, its history and its current momentum in the industry. It is important to highlight the technical reasons we need an orchestration layer for our container applications, especially when we are talking of large clusters running hundreds and thousands of containers.
Let us look at a few key requirements when you are dealing with distributed workloads.
Auto-scaling: As the load on your application increases or decreases, you require a system that takes care of launching more containers in the pool or bringing down the containers.
Health checks and readiness: In a cluster, it is important to know whether the containers are healthy or not, and whether they are ready to take the traffic routed to them or not. This ensures that the system can start up other containers, mark the unresponsive ones as bad and manage the traffic across healthy containers.
Portability: Docker has gained widespread acceptance due to the fact that it actually enables portability. This means that the container runtime is portable across infrastructure and operating systems, and the tools are simple, lean and available on not only the high-end machines but also on our laptops.
Rolling updates: All software undergoes changes due to newer features or fixes. In a system that is running with hundreds of containers, it is essential to have a smooth mechanism to roll out updates to the containers without bringing the whole system down. This ensures the availability of the application.
Extensibility: To encourage a healthy ecosystem, it is important for the system to be modular in nature, with extensibility provided via plugins that can be written by software vendors and individual developers.
Kubernetes meets the above requirements, all of which are expected from a container orchestration layer.
The building blocks
To understand Kubernetes a bit better, it is important to get familiar with its terminology. This helps when you start to download and explore Kubernetes.
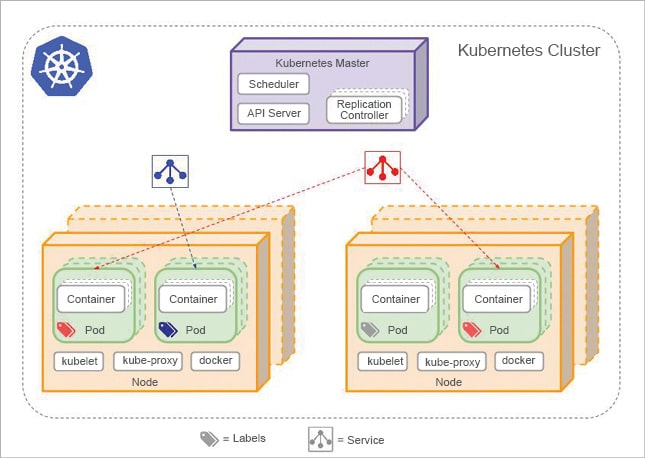
Pod: The first thing to understand is a pod, which is the smallest deployable unit. Think of it as a collection of containers that logically form an application. For example, if you are writing a Web application running in a Web server that is supported by a MySQL database at the backend, you can think of the pod as running your Web application with a couple of containers, one that runs the Web application and the other that runs your database. All the containers in the pod can share the volumes, and a pod will be scheduled on one or more nodes.
Node: A node is a physical machine or virtual machine running Kubernetes. The pods will be scheduled to run on one or more nodes. Each of the nodes will have the Docker engine that is responsible for eventually running the containers, though Kubernetes also supports another runtime—rkt from CoreOS. It will also have a kubelet, which takes the commands from the master. The kube-proxy is a proxy that runs on each node and helps enable the services, which is mentioned later in the Service section.
Cluster: A Kubernetes cluster includes all your physical machines, virtual machines and the infrastructure on which you are going to run your applications. These clusters could be co-located in a single data centre, across data centres or even regions. The goal of Kubernetes is to run seamlessly across any of the physical regions in a transparent manner for the developers.
Replication controller: Earlier, we spoke about the need to bring containers up and down. More specifically, since pods are the basic deployment unit, we are talking about scheduling pods across nodes—starting and stopping them — depending on the scale or even a requirement to keep a certain number of pods running. A replication controller is what makes this possible, and it controls the lifecycle of the pods.
Service: This is the magical piece in the whole puzzle. You might have a single pod or a collection of them forming your applications. To achieve the goal of being able to keep the infrastructure independent from the application, you have to expose your pods or, in other words, allow outside applications to access it. This is what a service is for. It provides a single interface to access your collection of pods, making it possible for pods to be created and brought down in a seamless fashion, without affecting the interface or needing to bring the application down.
The whole thing is woven together via the concept of a label, which is a collection of key-value pairs that can identify all the above artefacts.
The discussion is incomplete without covering the Kubernetes master, which is the server that manages all the Kubernetes nodes. The master has a service discovery mechanism, a scheduler and an API server to deal with client tools (kubectl) that can manage the Kubernetes cluster.
There are several other concepts in Kubernetes like volumes, secrets, etc. I suggest that you look up the official documentation.
Container orchestration: Other players
Kubernetes definitely has taken the lead when it comes to container orchestration solutions, especially when it comes to the range of features that it supports. However, we have Docker, which has competition in the form of Docker Swarm.Docker Swarm is the native clustering solution that has been built into the Docker runtime itself. It was announced a few months back at Dockercon and should see traction as it builds on the features that Kubernetes already has. In addition to these two solutions, you also have Apache Mesos.
It seems likely that Kubernetes and Docker Swarm might eventually battle it out in the orchestration solutions space. Irrespective of which emerges as the frontrunner, interoperability and simplicity, which have been the key to widespread Docker usage, should be kept intact.
Use Minikube to get familiar with Kubernetes
It may seem that to run Kubernetes, one needs a cluster of machines; but this is not the case. There is a great tool called Minikube that allows you run a single-node Kubernetes cluster on your laptop.
To install it on your machine, please follow the guide available at https://github.com/kubernetes/minikube
Once you install it successfully, you will have the Minikube utility that neatly packages the Docker tools inside it.
To get started, we need to launch our single node cluster. To do that, give the Start command as shown below:
$ minikube start Starting local Kubernetes cluster...
Kubectl is now configured to use the cluster.
At this point, you can check the status of the node via the following command:
$ kubectl get nodes NAME STATUS AGE minikubevm Ready 1m
We can now run a default echo service that is provided by Minikube via the following command:
$ kubectl run hello-minikube --image=gcr.io/google_containers/echoserver:1.4 --port=8080 deployment “hello-minikube” created
It will take a while to schedule the container on a pod. You can get the list of pods in your cluster via the command shown below. Note that you might have to run this command a few times, in case the pod is still starting.
$ kubectl get pods NAME READY STATUS RESTARTS AGE hello-minikube-2433534028-2j49e 1/1 Running 0 42s
It also creates a deployment that you can view as given below:
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE hello-minikube 1 1 1 1 1m
The next step now is to expose our deployment as a service. This will make it available to the outside world via a single interface. To do that, use the command given below:
$ kubectl expose deployment hello-minikube --type=NodePort service “hello-minikube” exposed
We can check the list of services exposed in the cluster now via the command given below:
$ kubectl get services NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE hello-minikube 10.0.0.50 <nodes> 8080/TCP 30s
To get the URL with which we can access this service, use the following command:
$ minikube service hello-minikube --url http://192.168.99.100:31499
One way to test our service is via the popular Curl utility as shown below. The output is what is echoed back by the service.
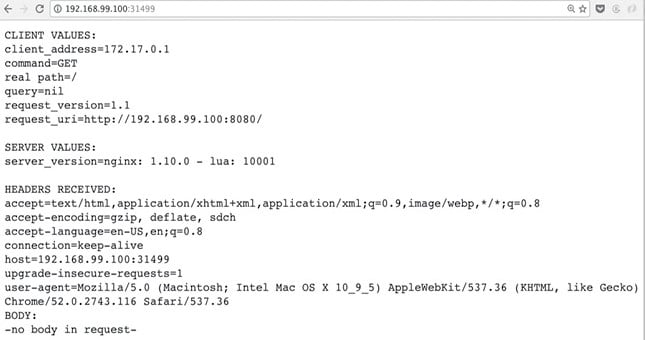
$ curl $(minikube service hello-minikube --url) CLIENT VALUES: client_address=172.17.0.1 command=GET real path=/ query=nil request_version=1.1 request_uri=http://192.168.99.100:8080/ SERVER VALUES: server_version=nginx: 1.10.0 - lua: 10001 HEADERS RECEIVED: accept=*/* host=192.168.99.100:31499 user-agent=curl/7.30.0 BODY: -no body in request-
Alternatively, you could also invoke it via the following:
$minikube service hello-minikube
This will open up the browser at the URL, and you should be able to see the echo service as shown in Figure 2.
You can view the Kubernetes dashboard by using the following command:
$ minikube dashboard
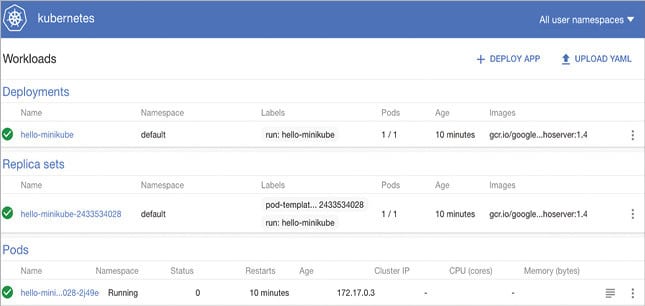
This will open up the dashboard in a browser, as shown in Figure 3. You can manage the deployment, services, pods and also click on them to view the details.
To clear up the resources, you can use the kubectl delete command as shown below:
$ kubectl delete service,deployment hello-minikube service “hello-minikube” deleted deployment “hello-minikube” deleted
Minikube is a great way to get familiar with Kubernetes, and the fact that it is available as a self-contained application on common operating systems makes it a good tool to start with.



{kind=link}
[…] code lab helped make sense of the ever-changing scalable application landscape. Lewis showed how to use Docker and Kubernetes to deploy, scale and manage microservices-based […]