






























































Duplicate files have their uses, but when they are duplicated multiple times or under different names and in different directories, they can be a nuisance. This article shows readers how to use Python to eliminate such files in a Windows system.
Computer users often have problems with duplicate files. Sometimes we mistakenly create the same file again and again with different names, or copy one file to different locations with different names. So it becomes very difficult to find the duplicate file due to its different name. There is also the case of files with the same name having different content. In order to solve this problem, let’s check out a new Python program.
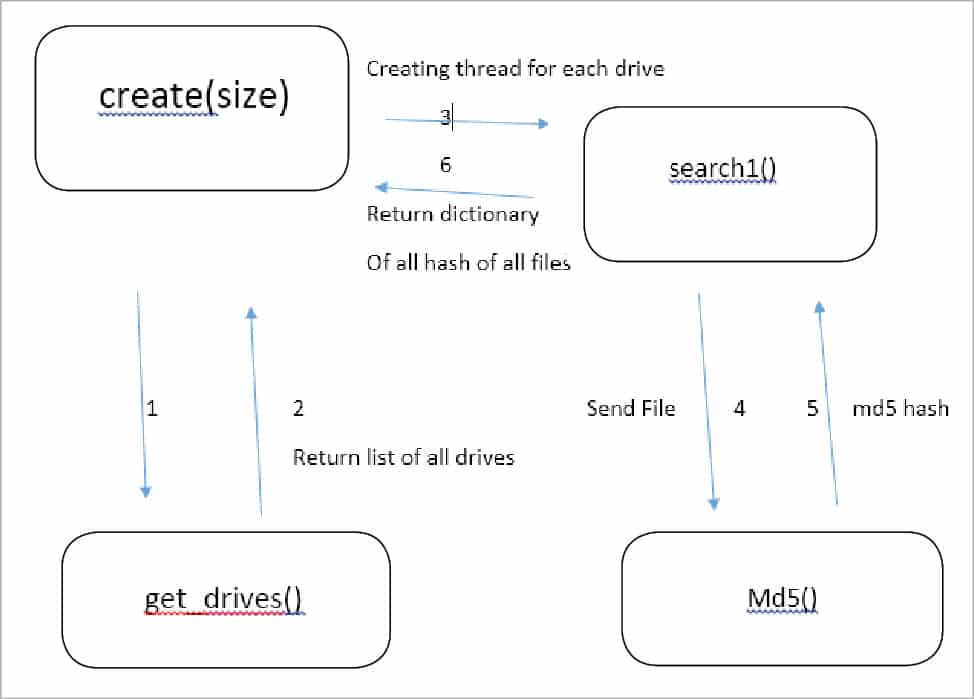
Before jumping to the source code, I want to explain the principle of the code, which is based upon the integrity of the file. If two files have the same content, with the same or different names, then their MD5 hash (or other hash algorithm) must be the same. In this article, I am going to use the MD5 hash to find the integrity of files. In the first step, let’s create and save the MD5 hash of all the files of all drives. See the basic code flow in Figure 1, which signifies the functionality of generating a database file that contains hashes of all files.
The function create() will be called by the user with arguments. It accesses all hard disk drives through the get_drive() function; then, it creates threads for each drive and calls the search1() function. The search1() function uses the md5() function to generate the MD5 hash for each file. In this way, the search1() function creates a Python default dictionary, which contains hashes as keys and files with paths as values. Finally, the create() function dumps the Python default dictionary into a pickle file.
Let’s discuss the code.
#program created by mohit #offical website L4wisdom.com # email-id mohitraj.cs@gmail.com
The following modules will be used in the program. Do not worry about creating MD5 hashes because there is a module hashlib which will do this for you.
import os import re import sys from threading import Thread from datetime import datetime import subprocess import cPickle import argparse import hashlib import collections · Create a Python default dictionary dict1 = collections.defaultdict(list)
The md5() function calculates the MD5 hash of the file.
def md5(fname,size=4096): hash_md5 = hashlib.md5() with open(fname, “rb”) as f: for chunk in iter(lambda: f.read(size), b””): hash_md5.update(chunk) return hash_md5.hexdigest()
The all_duplicate() function in the following code is used to print all duplicate files in the drive. It gives the output to a file named duplicate.txt in the current running folder.
def all_duplicate(file_dict, path=””): file_txt = open(‘duplicate.txt’, ‘w’) all_file_list = [v for k,v in file_dict.items()] for each in all_file_list: if len(each)>2: file_txt.write(“-------------------\n”) for i in each: str1 = i+”\n” file_txt.write(str1) file_txt.close()
The get_drives() function shown below returns the list of all drives. If you insert a pen drive or external drive while running the program, it will also be listed.
def get_drives(): response = os.popen(“wmic logicaldisk get caption”) list1 = [] total_file = [] t1= datetime.now() for line in response.readlines(): line = line.strip(“\n”) line = line.strip(“\r”) line = line.strip(“ “) if (line == “Caption” or line == “”): continue list1.append(line) return list1
The search1() function shown in the following code gets the drive’s name from the above function and accesses all files. It then sends the file with the full path to the md5() function to get the MD5 hash. Finally, it builds the global default dictionary dict1.
def search1(drive,size): for root, dir, files in os.walk(drive, topdown = True): try: for file in files: try: if os.access(root, os.X_OK): orig = file file = root+”/”+file if os.access(file, os.F_OK): if os.access(file, os.R_OK): s1=md5(file,size) dict1[s1].append(file) except Exception as e : pass except Exception as e : pass
The create() function is what starts to create the hashes of all files. It creates the threads for each drive and calls the search1() function. After the termination of each thread, the create() function dumps the default dictionary dict1 to the pickle file named mohit.dup1, as shown below:
def create(size): t1= datetime.now() list2 = [] # empty list is created list1 = get_drives() print “Drives are \n” for d in list1: print d,” “ , print “\nCreating Index...” for each in list1: process1 = Thread(target=search1, args=(each,size)) process1.start() list2.append(process1) for t in list2: t.join() # Terminate the threads print len(dict1) pickle_file = open(“mohit.dup1”,”w”) cPickle.dump(dict1,pickle_file) pickle_file.close() t2= datetime.now() total =t2-t1 print “Time taken to create “ , total
The following function opens the pickle file and loads the dictionary into the memory (RAM):
def file_open(): pickle_file = open(“mohit.dup1”, “r”) file_dict = cPickle.load(pickle_file) pickle_file.close() return file_dict
The file_search() function in the following code is used to match the hash of the file provided by the user. It first opens the pickle file and loads the Python default dictionary. When you provide the file with the pathname, it calculates the MD5 hash of the file and then matches it with the dictionary’s keys.
def file_search(file_name): t1= datetime.now() try: file_dict = file_open() except IOError: create() file_dict = file_open() except Exception as e : print e sys.exit() file_name1 = file_name.rsplit(“\\”,1) os.chdir(file_name1[0]) file_to_be_searched = file_name1[1] if os.access(file_name, os.F_OK): if os.access(file_name, os.R_OK): sign = md5(file_to_be_searched) files= file_dict.get(sign, None) if files: print “File(s) are “ files.sort() for index, item in enumerate(files): print index+1,” “, item print “---------------------” else : print “File is not present or accessible” t2= datetime.now() total =t2-t1 print “Time taken to search “ , total
Shown below is the main() function responsible for all actions. We will discuss all its options later with diagrams.
def main(): parser.add_argument(“file_name”,nargs=’?’, help=”Give file with path in double quotes”) parser.add_argument(‘-c’,nargs=’?’, help=”For creating MD5 hash of all files”,const=4096, type=int) parser.add_argument(‘-a’,help=”To get all duplicate files in duplicate.txt in running current folder”, action=’store_true’) parser.add_argument(‘-f’,help=”To find the MD5 hash,provide file with path in double quotes “, nargs=1,) args = parser.parse_args() try: if args.c: print args.c create(args.c) elif args.a : file_dict = file_open() all_duplicate(file_dict) elif args.f : if os.access(args.f[0], os.R_OK): print “Md5 Signature are : “, md5(args.f[0],4096) print “\n” else : print “Check the file path and file name\n” else: file_search(args.file_name) print “Thanks for using L4wisdom.com” print “Email id mohitraj.cs@gmail.com” print “URL: http://l4wisdom.com/finder_go.php” except Exception as e: print e print “Please use proper format to search a file use following instructions” print “dupl file-name” print “Use <dupl -h > For help” main()
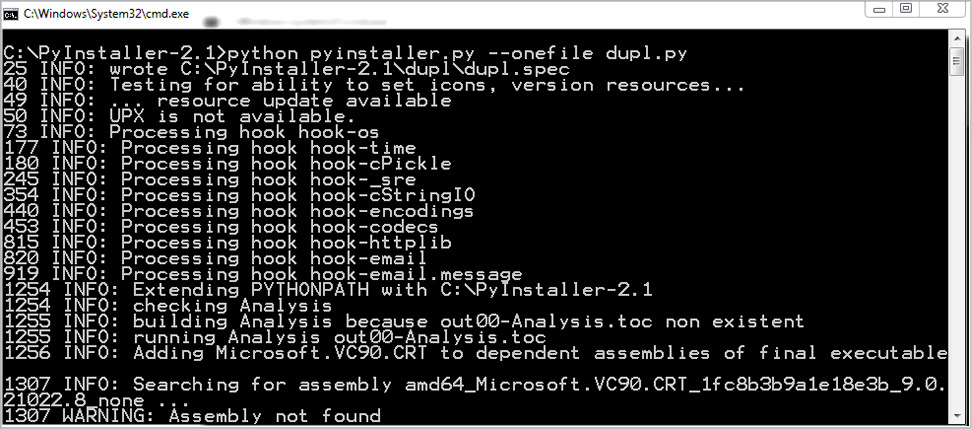
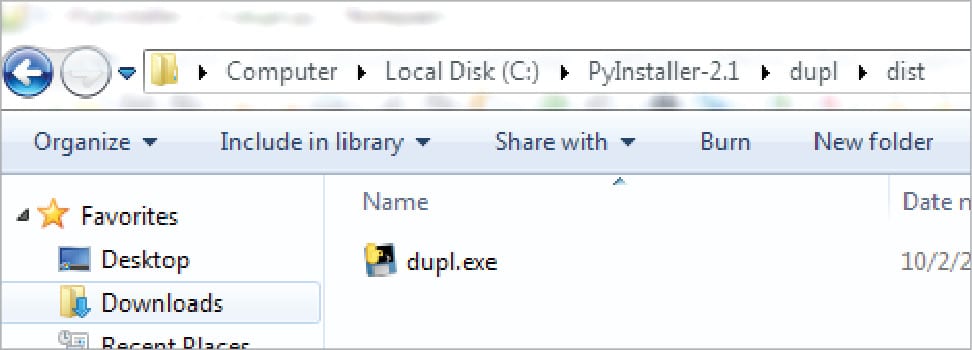
Let us save the complete code as dupl.py and make it a Windows executable (exe) file using the Pyinstaller module. You can also download a readymade exe file from http://l4wisdom.com/dupl_go.php. Run the command as shown in Figure 2. After running it successfully, you can find the dupl.exe in folder C:\PyInstaller-2.1\dupl\dist, as shown in Figure 3. You can put the dupl.exe file in the Windows folder, but if you place this in a different folder, you will have to set the path to that folder. Let us run the program with the following command:
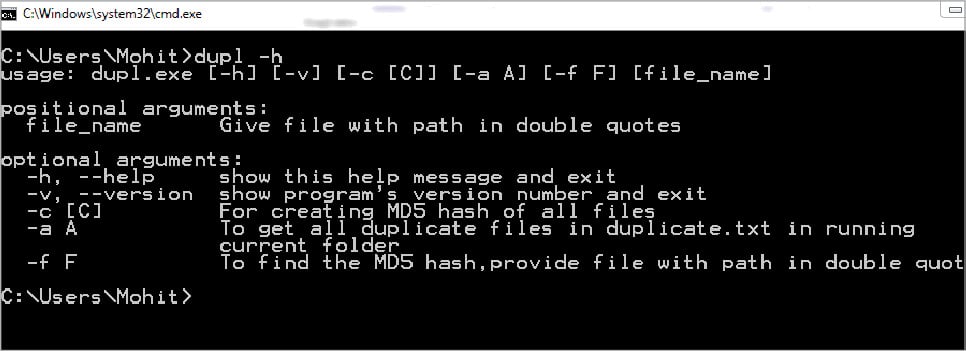
1. dupl –h
This helps to show all options, as seen in Figure 4.
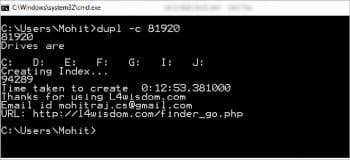
2. dupl –c 81920
The above command will create the database pickle file mohit.dup1, which contains the hashes of all files. The argument 81920 is the byte size used by the MD5 algorithm — you can change it. If you increase the size, the calculating speed of the hashes will be increased at the expense of the RAM. If you don’t provide the number, then it automatically takes the 4096 byte size.
As you can see in Figure 5, it takes 12 minutes and 53 seconds to create databases. This speed depends upon various factors such as RAM, the model of the computer, the number of files and their sizes. The hash calculation time is directly proportional to the size of the file. The database pickle file will be created in the current running folder.
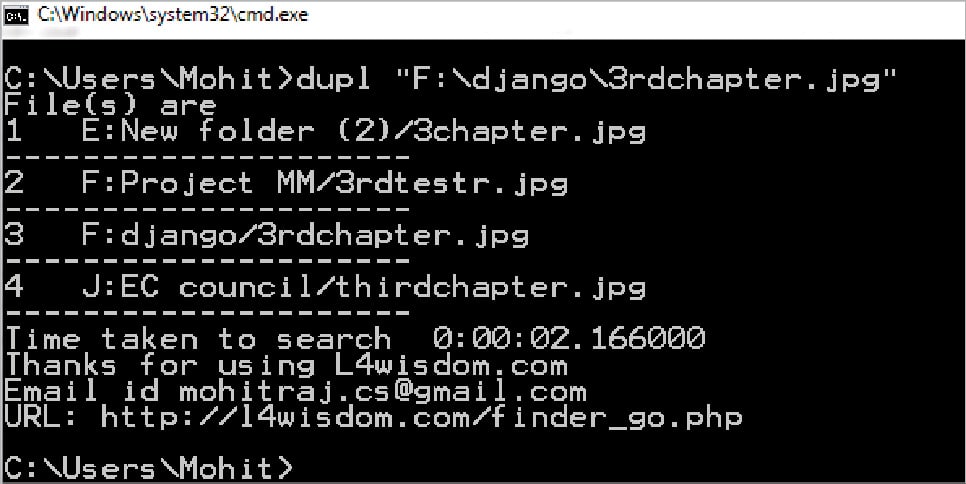
3. dupl <file-with full path>
Figure 6 shows the duplicate files based upon the hash.
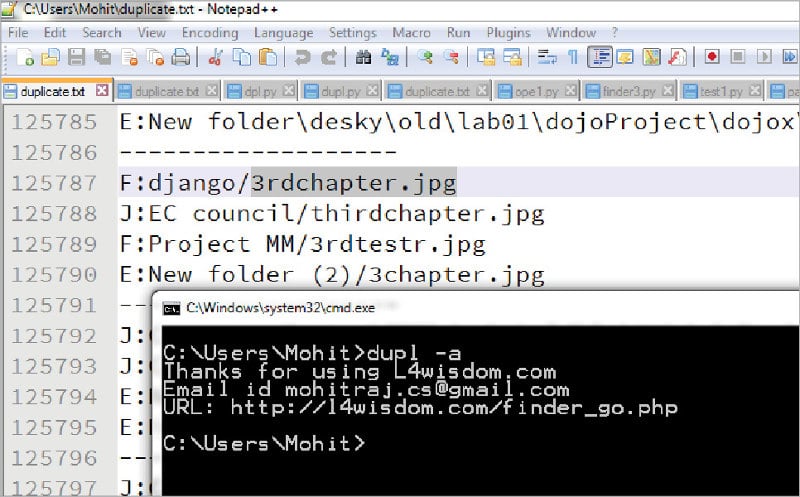
4. dupl –a
In this option, duplicate.txt has been created in the current folder, which contains all the duplicate files in pairs, as shown in Figure 7.
5. dupl –f <file with path>
This option takes a file with path and returns the MD5 hash.

















I suggest to use Duplicate Files Deleter its a helpful program.
If you want to learn Python by Mohit drop your message http://l4wisdom.com/contact.php