






























































Some of our readers had requested us to cover robotic process automation (RPA). Hence, we are here providing a brief overview of this interesting and important trend in information technology. We will also examine how natural language processing and machine learning play a role in RPA.
What is robotic process automation?
Robotic process automation (RPA) is defined by the Institute for Robotic Process Automation (IRPA) as ‘the application of technology allowing employees in a company to configure computer software or a ‘robot’ to capture and interpret existing applications for processing a transaction, manipulating data, triggering responses and communicating with other digital systems.’ In other words, it involves automating certain tasks or processes that manipulate data. While the definition of RPA as defined by IRPA is very broad and uses the word ‘robot’, real life RPA has nothing to do with robots. Though the term ‘robotic process automation’ conjures up visions of an army of robots doing some human tasks, such as moving things or carrying out some other such physical labour, RPA does not have anything to do with robots themselves. It is a form of automation where intelligent software processes take over certain tasks that have typically been performed by human beings.
The readers may now be wondering how this is different from normal software processes involved in desktop automation, which typically do many tasks such as generating bar charts from data, or performing accounting calculations in Excel spreadsheets, typically performed by defining custom macros. Well, the difference comes from the fact that such simple automation scripts fail when there is a decision to be made and when there are a set of complicated steps to follow in order to achieve a task. Typically, desktop automation is limited to defining functions or macros that operate within an application. Let us consider an example from the financial services, namely, the accounts payable process. This is a critical function in all organisations. It includes reconciling the statements submitted by the vendors against the statements of the internal buying departments of an organisation. An organisation can buy goods and services from outside vendors. The purchase process is typically carried out by means of purchase orders. When the goods and services are received, the buying departments create the ‘received’ reports. The vendors or sellers of these goods and services then submit invoices for payment by the organisation. The reconciliation is carried out by a three-way process between the vendor invoices, received reports and the purchase orders.
While this appears to be a routine task, mismatches between these three data sources can require human intervention and decision making. A typical mismatch could be where the vendor shows the invoice as unpaid whereas the internal department system shows the invoice as paid. The accounts payable process then needs to identify the root cause of the mismatch, and so carries out one of the following three actions. If it finds that the invoice has already been paid, it needs to send the payment details to the vendor. If it has been processed and marked as not paid, it needs to provide the reasons for non-payment to the vendor. Or if the invoice has not been received, it should send a notification to the vendor to send a duplicate invoice. This is a repetitive task and needs decision-making based on the type of mismatch found. Hence, this task is typically done by humans.
Given the repetitiveness of the task and the need for decision-making, this is an ideal task for RPA. The RPA tool, when deployed, can isolate the mismatches and take the required action. Instead of having humans perform this repetitive task, using a robotic process automation tool will improve productivity by over 90 per cent, while achieving the highest accuracy. This is just one simple example of an RPA tool. Many such instances exist in the organisational workflow. Today, many of the business processes that were outsourced are getting transformed as a result of RPA. Business processes can either be front-end operations dealing with customers in call centres, or they can be back-end processes such as accounts payable, checking the derivatives trades, insurance claims processing, etc.
Automation of front-end operations typically involves chat bots or conversational agents. These automation processes usually require natural language processing or natural language understanding. Back-end operations can be either based on structured data or unstructured data. Structured data operations typically include data operations on various databases. Unstructured data operations typically include processing of documents, images and multi-modal data. Now, let us take a brief diversion to understand how natural language processing (NLP) can aid in RPA.
Natural language processing and RPA
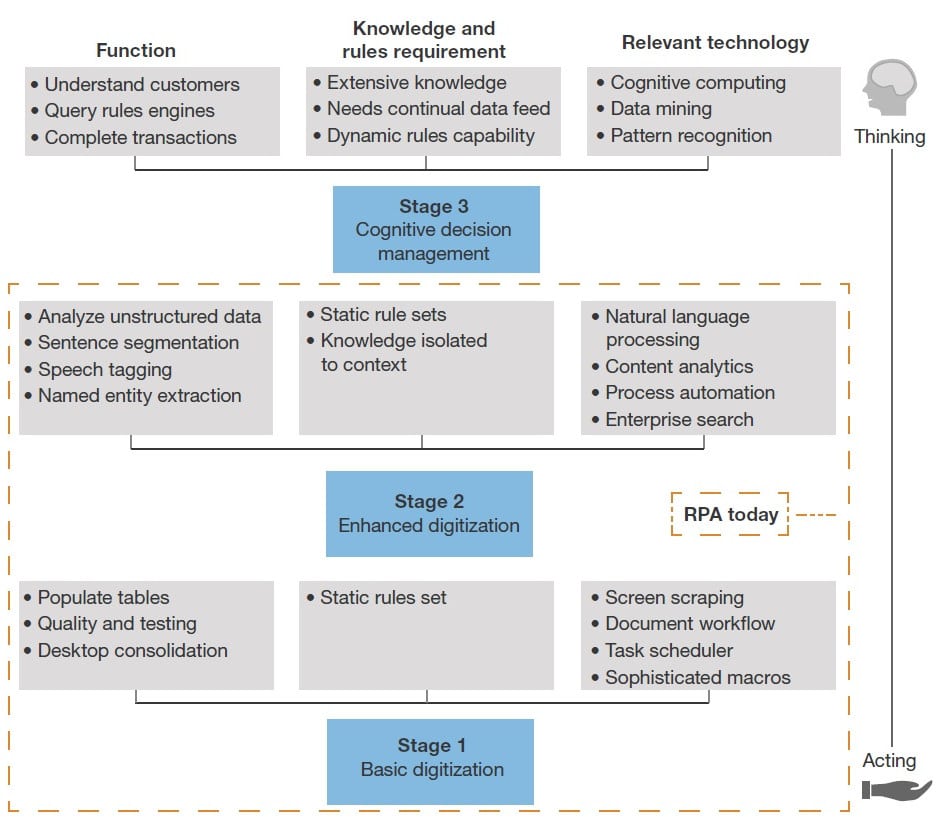
According to industry experts, RPA is likely to progress through three stages of innovation. The first stage consists of dealing with static rules and structured data, with tasks such as data entry and validation getting automated. Stage 2 of RPA consists of some form of natural language processing capabilities and performing tasks such as content analytics and process automation. Stage 3 consists of advanced natural language processing and cognitive capabilities—this deals with RPA systems capable of human-like decision-making. Figure 1 shows the evolution of RPA capabilities through these three stages*.
While existing RPA solutions work on the ‘click and automate’ mode when dealing with structured data, with regard to unstructured text data, RPA has not been exploited fully for intelligent automation. Existing RPA solutions are ‘action based’ – they understand the actions being performed on the GUI or on the back-end enterprise systems, be it data entered in a specific field in a form or a table retrieved from a back-end database. Existing RPA scripts do not interpret the content of the textual data that arises in the workflow. Knowledge from contextual text artefacts is not used either in process discovery or in exception management.
Moving RPA systems from the ‘Repetitive Do’ cycle to a ‘Think – Judgement-based on context’ cycle requires incorporating content analytics of textual artefacts that are present in the business process workflow. For instance, the ‘Repetitive Do’ cycle automation that handles structured data and static rules is better suited for automating tasks such as claim processing, account data reconciliation or data consolidation and validation. However, in scenarios where contextual knowledge and judgement are required, such as in service desk incident resolution, complaint resolution and management, eligibility processing—all of which involve unstructured text and considerable exceptions—existing RPA solutions do not fare well, due to lack of intelligent text processing.
Let us illustrate this with a simple use-case—the business workflow for a customer service desk ticket resolution system for an ecommerce retailer back-end. The system’s tickets can be raised through customer chats/emails and can either be responded to in real-time by agents via chat, or offline over emails. For each problem reported, the information is hidden in unstructured text. Each complaint needs to be identified for its respective category – such as missing item, delayed delivery, cancelling of purchase, change of address of the customer, etc. For each specific problem, there is a sequence of actions involved. All problem tickets have the initial sequence steps of:
a. Authenticating the customer.
b. Processing order details and retrieving them.
c. Verifying the customer address, which is part of the back-end compliance mechanism.
After these steps, the problem resolution consists of a sequence of actions that can be different for different problems.
d. Identify the problem category.
e. Find the appropriate resolution.
f. Identify the action sequence to resolve the problem.
g. Record the action sequence for resolution.
While steps (a) to (c) are ideal for traditional RPA since they typically deal with structured data entered through forms, steps (d) to (g) require dealing with unstructured textual content, understanding contextual knowledge, as well as content analytics and judgement. NLP modules aid in problem categorisation based on unstructured text, knowledge mining of back-office problem manuals to identify the resolution, parsing previous interactions to mine the action sequence in terms of extracting the verbs/subject/object from the text, and outputting the necessary action sequence. Existing RPA solutions can help automate steps (a) to (c), but typically fail when automating steps (d) to (e). However, by employing natural language processing techniques, RPA tool suites can be enhanced to automate steps (d) to (e).
A similar problem emerges in insurance claim validation. Typically, insurance claims contain unstructured data like supporting documents that need to be analysed in case of any potential violations. Data also needs to be extracted from multiple systems and validated against each other. Given that it is possible to synthesise a set of rules to cover the validation process, this is a good candidate for RPA.
So far, we have been talking about existing RPA capabilities in terms of being able to handle static rule-based tasks which are repetitive and whose decision-making can be condensed into a form of if-then statements. How can RPA deal with more complex decision-making scenarios? How can it learn to handle exceptions in a workflow like humans do? Who are the leading vendors in RPA? We will cover these topics in next month’s column.
If you have any favourite programming questions/software topics that you would like to discuss on this forum, please send them to me, along with your solutions and feedback, at sandyasm_AT_yahoo_DOT_com.

















Hi Sandya, I really like how you explain the difference between the “basic” and advanced RPA functionality. There are only too many scenarios and capabilities of Robotic Process Automation, especially when coupled with other technologies to form new ways of processes execution – and even design to begin with. I am working with Softomotive – one of the RPA software providers – and I am experiencing different, real-world scenarios of RPA adoption and usage from our clients everyday. The discussion about where this technology “trend” is heading admittedly is very exciting!
[…] in which the world interacts with individuals. The world of robotic technology is, therefore, making great advancements that have led to the development of unimaginable items such as self-driven cars, drones and other […]
Hi Sandhya, Who can learn This Robotics Process Automation Course
which programming language that we use for rpa?
Thank you for great information.
To learn robotic process automation online,visit:http://www.itorigins.com
CALL:+91-9640407407, MAIL: info@itorigins.com
Very detailed information, I’m trying to explore more on the tools here: http://www.askeygeek.com/robotic-process-automation-rpa-what-why-how-all-you-need-to-know/
check this blog to learn RPA anupamsharma.co
Informative read.. gives insights on the why and what of Robotic Process Automation (RPA)