































































This article gives a detailed description of Solr. It is aimed at geeks who have built a Web application and want to make the search for it faster.
Solr (pronounced Solar) was created by Yonik Seeley in 2004. Apache Solr is an open source search platform based on the Apache Lucene search library. In a sense, Solr is a cover over the Apache Lucene library. It uses the Lucene class to create an inverted index. Apache Solr is built upon Java. Most search websites are today built upon Solr, of which the most popular are e-commerce sites. Solr runs on standalone full-text search servers. The Lucene Java search library is used to create an index, which is used by Solr to perform searches. Solr has an HTML/XML interface and JSON APIs on which search applications are created. In layman’s terms, Solr can be defined as follows: “Apache Solr is a search engine—you index a set of documents and then query Solr to return a set of documents that matches the user query.”
Solr gained popularity because it is fast, and can index and search multiple sites. It returns relevant content based on the search query’s taxonomy. Other important features are: faceted searching, dynamic clustering, database integration, NoSQL features, rich document handling, a comprehensive administration interface, high scalability and fault tolerance, as well as real-time indexing.
The preferred environment for the purpose of this article is Solr-5.3.0. Before you begin the Solr installation, make sure you have JDK installed and Java_Home is set appropriately.

Solr makes search easy
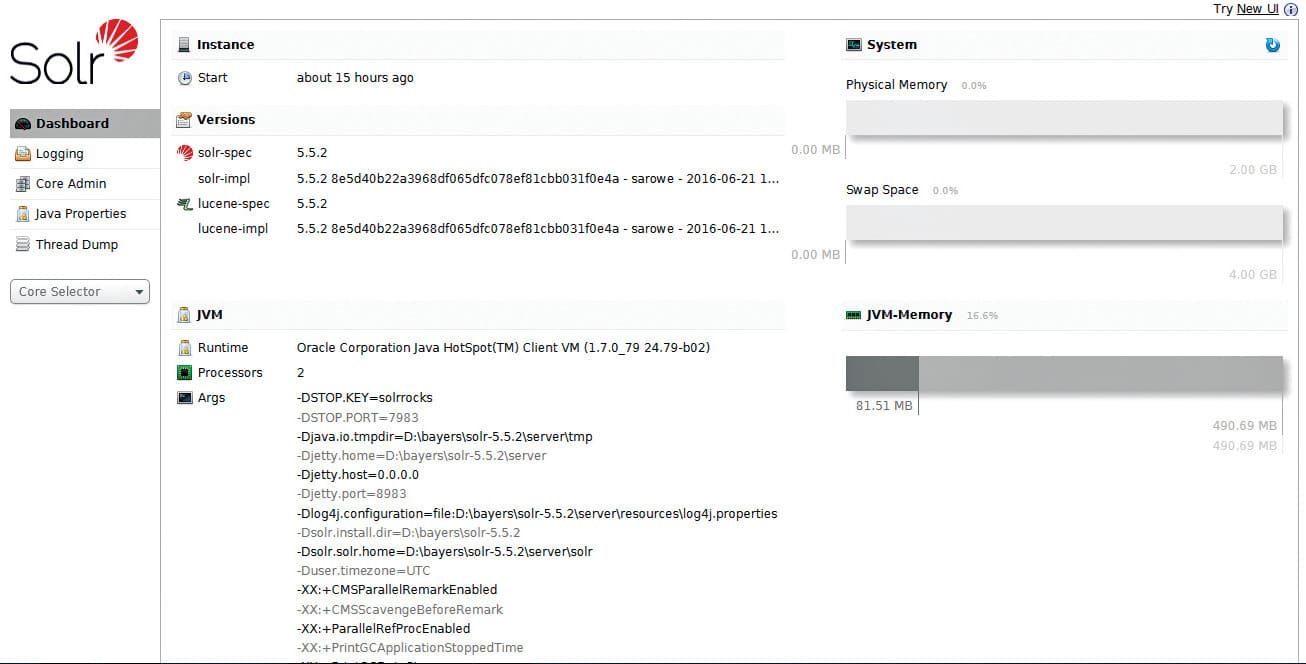
To understand how Solr makes search easy, we first have to configure it. As I am using Windows 7, I will demonstrate Solr in Windows. Solr is open source, so it can easily be downloaded from the Solr website. But remember, to run Solr, you need to have JRE installed in your system. For a Windows system, download the .zip file. To get started, all you need to do is extract the Solr distribution archive to a directory of your choosing. Once extracted, you are ready to run Solr in your system.
You can start Solr by running bin\Solr.cmd, if you are using Windows. This will start Solr on port 8983. If everything is fine, Solr will start by saying, ‘Happy Search!’. If you want to change the port number, then give the command Solr start -p port number, using cmd. You can also use the Solr -help command to know the various types of commands in Solr. When Solr starts running, it will generate a URL to see the admin console.
Now, to start the search in Solr, you first have to create the core file, by giving the command Solr create -c core_name, in cmd. The core file mainly contains configuration files in the conf folder.
Solr makes it easy to search for an application. You just have to define a schema according to your dataset in schema.xml, which is a file that defines the representation of the documents that are indexed/ingested in Solr, i.e., the set of data fields that they contain. For example, a newspaper article may contain a title, author name, body text, date, etc. You have to mention the data type of those fields in schema.xml. Figure 2 shows how to define data fields in schema.xml.
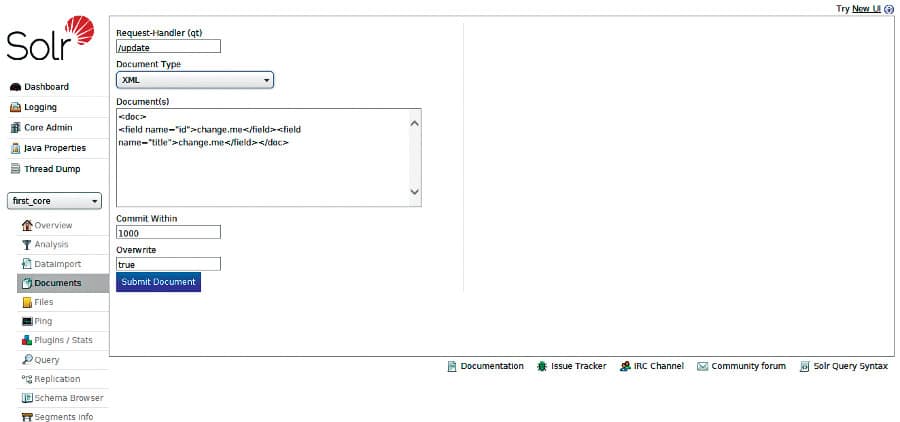
After defining Schema, deploy Solr into your data either in the database or by uploading data files. Figure 3 shows how to upload data in Solr in various formats in order to supply Solr documents for each user who searches.
As Solr is based upon open standards, it is highly extensible. Solr fires queries that are RESTful in nature, which means that the query is as simple as an HTTP request URL and the response is an ordered document – mainly, XML, CSV, JSON or some other formats.

Basic syntax, schema.xml, with an example
Fields: You can simply define a field name or dataset in schema.xml as follows:
field name =”string” indexed=”true” stored=”true” multiValued=”true” required=”true”
Here, ‘name’ is the name of the field type. This value is used in field definitions, in the ‘type’ attribute. ‘Indexed’ default value is true—the value of the field can be used to query and to retrieve matching documents. The ‘stored’ default value is true—the actual value of the field can be retrieved by queries. ‘multiValued’ default value is false; if true, it indicates that a single document might contain multiple values. ‘required’ default value is false—it instructs Solr to reject any attempt to add a document that does not have a value for this field. Figure 2 shows how to define field type.
Dynamic fields: Solr has strong data typing for fields, yet it provides flexibility using ‘Dynamic fields’. Using the <dynamic field> tag declaration, you can create field rules that Solr will use to understand what data type should be used whenever it is given a field name that is not explicitly defined, but matches a prefix or suffix used in the dynamic field.
For example, dynamic field affirmation tells Solr that whenever it sees a name ending in ‘_i’ which is not an explicitly defined field, then it should dynamically create an integer field like what’s shown below:
<dynamicField name =”*_i” type=”integer” indexed=”true” stored=”true”/>
Copy fields: The <copyField> declaration is used to instruct Solr that you want to duplicate any data it sees in the ‘source’ field of documents that are added to the index, in the ‘destination’ field of that document. But remember that datatypes of the fields are compatible. Duplication of fields is done before any analysers are invoked. By the use of copy field, Solr will be able to search by simply giving the value and not defining the tag. For example, if there is a field like Roll number, without the use of copyField, we can search by giving the command ‘rollno:10’.
With the use of copyField, the syntax of the copy field declaration is:
<copyField source=”rollno” dest=”text”/>
Now we can search just by typing ‘10’ and Solr will give you the same result.
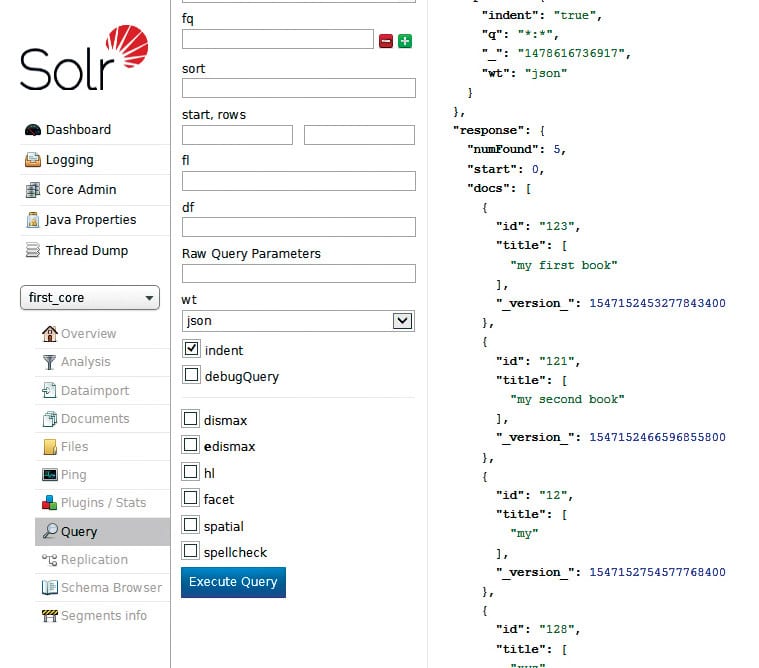
You can query by clicking on the query tab which looks like what’s shown in Figure 6.

Solr vs Elastic Search (ES)
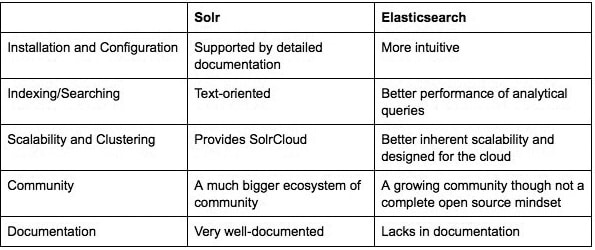
Solr and Elastic Search are competing search servers. Both are built on top of Lucene, so their core features are identical. In fact, Solr and ES are so similar that an ES plug-in allows you to use Solr client/tools with ES. For most functions, there is no genuine cause to choose Solr over ES, or vice versa. But there are some minor differences listed in the table shown in Figure 7.
Deploying Solr with Tomcat
Please note, this deployment is done in Solr 5.1. The prerequisites are listed below.
1. Install the Tomcat Servlet Container on the system as follows:
C:\Solr with Tomcat\apache-tomcat-7.0.57
(We will refer to it as TOMCAT_HOME.)
2. Download and extract the Solr package as follows:
C:\Solr-5.1.0\Solr-5.1.0
Now follow the steps given below.
1) Copy the Solr directory from the extracted package (C:\Solr-5.1.0\Solr-5.1.0\server\Solr) into the home directory of Tomcat—into TOMCAT_HOME\bin or into TOMCAT_HOME if Tomcat is to be started as a service.
2) Copy the Solr war file (C:\Solr-5.1.0\Solr-5.1.0\server\webapps\Solr.war) into the Tomcat Web apps directory, TOMCAT_HOME/webapps. Tomcat will automatically deploy it.
3) Copy all the five jar files from the Solr extracted package (C:\Solr-5.1.0\Solr-5.1.0\server\lib\ext) to the TOMCAT_HOME\lib directory.
• jul-to-slf4j-1.7.7, • jcl-over-slf4j-1.7.7, • slf4j-log4j12-1.7.7, • slf4j-api-1.7.7, • log4j-1.2.17
4) Copy the log4j.properties file from the C:\Solr-5.1.0\Solr-5.1.0\server\resources directory to the TOMCAT_HOME\lib directory.
5) After Solr.war is extracted:
a) Create the core (if not already done).
b) Copy the further needed listener-specific jars to C:\Solr with the Tomcat\apache-tomcat-7.0.57\webapps\Solr\WEB-INF\lib directory.
c) Configure the entry for listener-related jars to the scheduler in the C:\Solr With Tomcat\apache-tomcat-7.0.57\webapps\Solr\WEB-INF\web.xml file.
d) Modify the server port in the properties file of the scheduler (for example, C:\Solr with Tomcat\apache-tomcat-7.0.57\bin\Solr\conf\dataimportScheduler.properties).
e) In order to run the data-importhandler, copy the jars specific to the data-importhandler and for the custom transformer, if any, in the folder C:\Solr With Tomcat\apache-tomcat-7.0.57\bin\Solr\lib.
• Solr-dataimporthandler-5.1.0.jar • Solr-dataimporthandler-extras-5.1.0.jar • ojdbc14-10.2.0.5.jar • SqltoSolrDateTransformer.jar and change the entry in Solrconfig.xml for the same as <!-- for data import handler --> <lib dir=”../lib/” regex=”Solr-dataimporthandler-\d.*\.jar” /> <lib dir=”../lib/” regex=”ojdbc14-\d.*\.jar” /> <!-- For Custom Date Tranformer --> <lib dir=”../lib/” regex=”SqltoSolrDateTransformer.jar” />
Start the Tomcat server from TOMCAT_HOME\bin\startup.bat and locate the Web browser to http://localhost:8080/Solr (change the port if necessary).The admin page of Solr will be displayed.
What next?
Congratulations! You have understood the basics of Solr. You have learned about its syntax and different fields, how it makes search easy, the differences between Elastic Search and Solr, and how to deploy Tomcat with Solr. The next step is discovering how to connect Java (or any other language) with Solr, or, how to integrate Solr with your application.

















{kind=link}
Aimed at geeks?
FFS You should know better calling IT professionals, that.