






























































With an abundance of data from different sources, data mining for various purposes is the rage these days. Weka is a collection of machine learning algorithms that can be used for data mining tasks. It is open source software and can be used via a GUI, Java API and command line interfaces, which makes it very versatile.
Waikato Environment for Knowledge Analysis (Weka) is free software licensed under the GNU General Public License. It has been developed by the Department of Computer Science, University of Waikato, New Zealand. Weka has a collection of machine learning algorithms including data preprocessing tools, classification/regression algorithms, clustering algorithms, algorithms for finding association rules, and algorithms for feature selection. It is written in Java and runs on almost any platform.
Let’s look at the various options of machine learning and data mining available in Weka and discover how the Weka GUI can be used by a newbie to learn various data mining techniques. Weka can be used in three different ways – via the GUI, a Java API and a command line interface. The GUI has three components—Explorer, Experimenter and Knowledge Flow, apart from a simple command line interface.
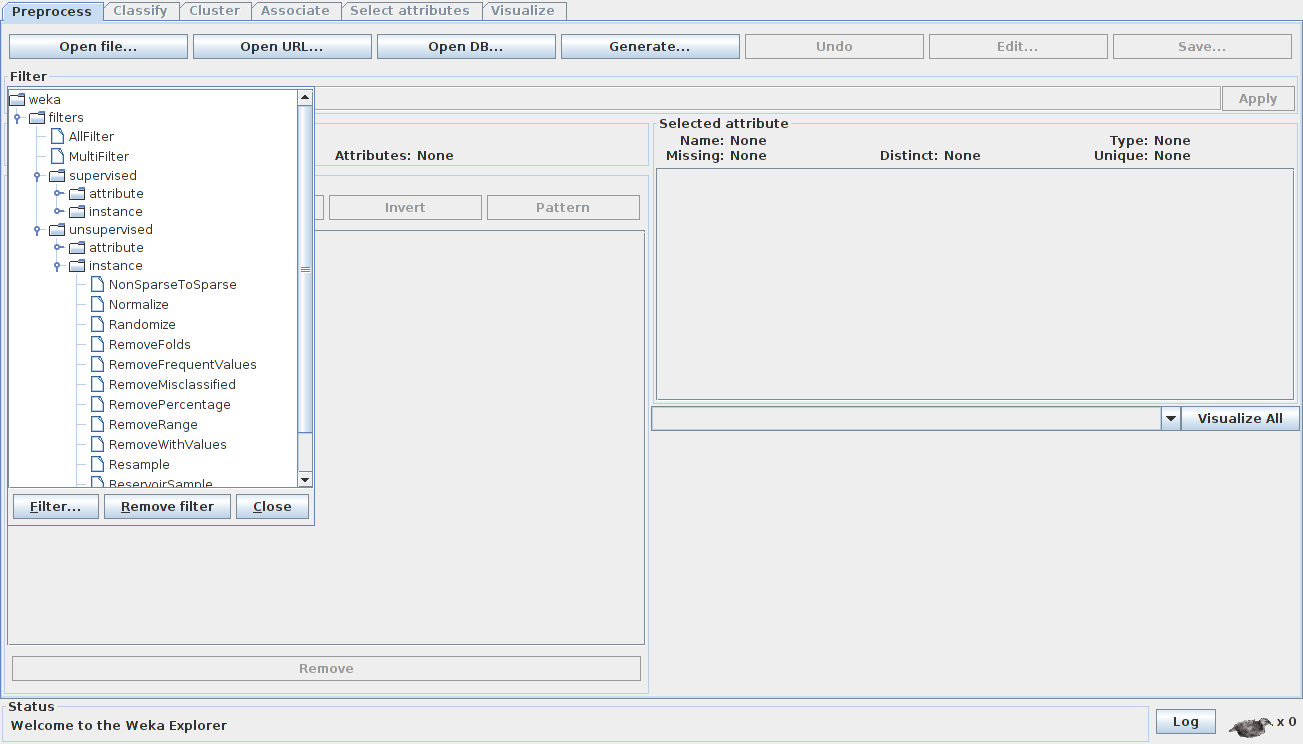
The components of Explorer
Explorer has the following components.
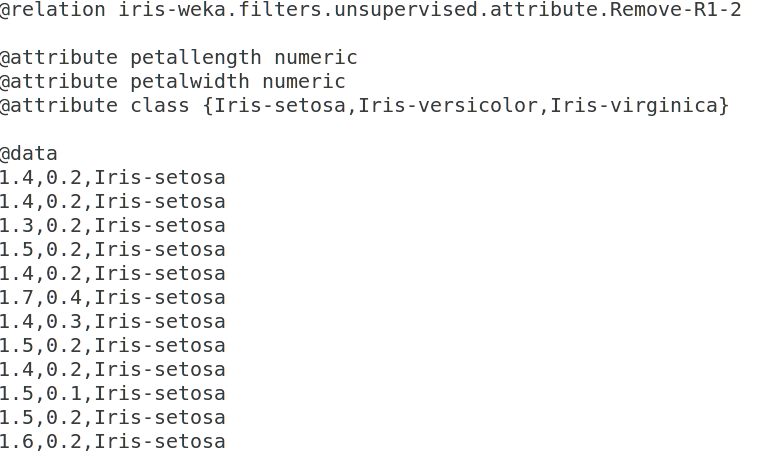
Preprocess: The first component of Explorer provides an option for data preprocessing. Various formats of data like ARFF, CSV, C4.5, binary, etc, can be imported. ARFF stands for attribute-relation file format, and it was developed for use with the Weka machine learning software. Figure 1 explains various components of the ARFF format. This is an example of the Iris data set which comes along with Weka. The first part is the relation name. The ‘attribute’ section contains the names of the attributes and their data types, as well as all the actual instances. Data can also be imported from a URL or from a SQL database (using JDBC). The Explorer component provides an option to edit the data set, if required. Weka has specific tools for data preprocessing, called filters.
The filter has two properties: supervised or unsupervised. Each supervised and unsupervised filter has two categories, attribute filters and instances filters. These filters are used to remove certain attributes or instances that meet a certain condition. They can be used for discretisation, normalisation, resampling, attribute selection, transforming and combining attributes. Data discretisation is a data reduction technique, which is used to convert a large domain of numerical values to categorical values.
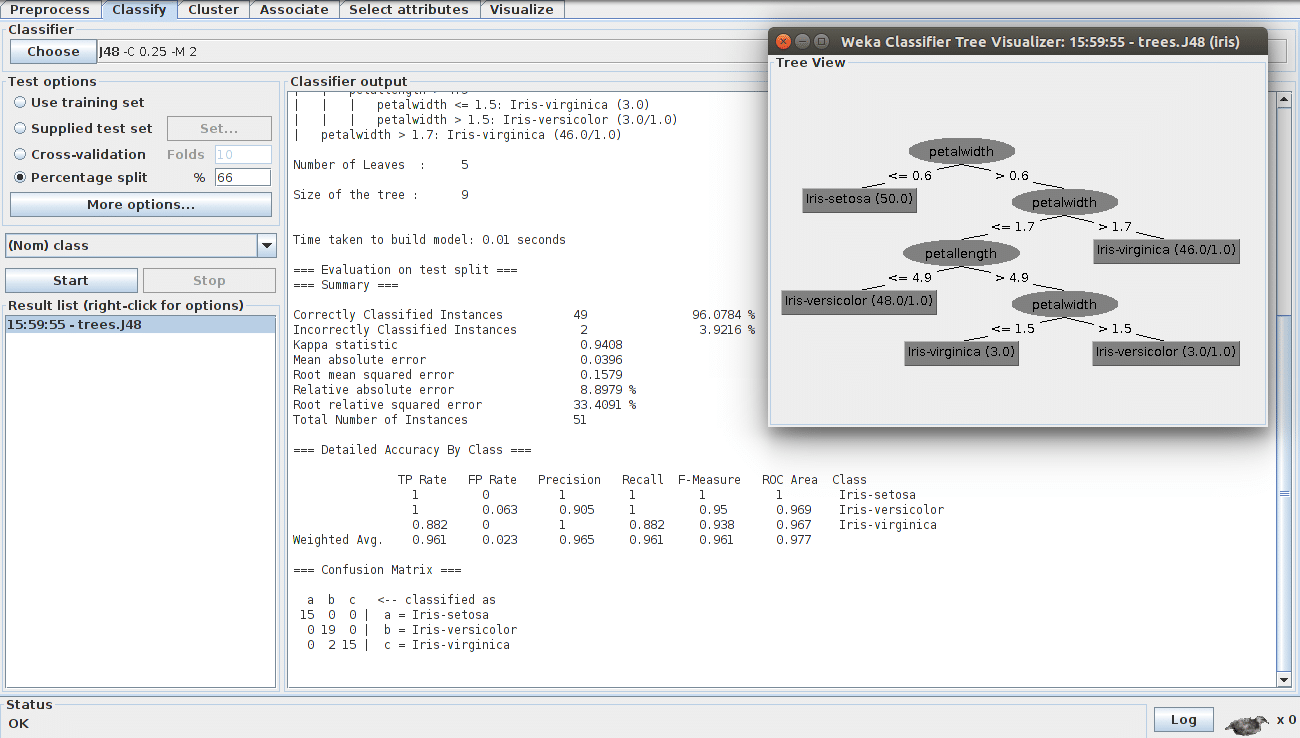
Classify: The next option in Weka Explorer is the Classifier, which is a model for predicting nominal or numeric quantities and includes various machine learning techniques like decision trees and lists, instance-based classifiers, support vector machines, multi-layer perceptrons, logistic regression, Bayes’ networks, etc. Figure 3 shows an example of a decision tree using the J4.8 algorithm to classify the IRIS data set into different types of IRIS plants, depending upon some attributes’ information like sepal length and width, petal length and width, etc. It provides an option to use a training set and supplied test sets from existing files, as well as cross validate or split the data into training and testing data based on the percentage provided. The classifier output gives a detailed summary of correctly/incorrectly classified instances, mean absolute error, root mean square error, etc.
Cluster: The Cluster panel is similar to the Classify panel. Many techniques like k-Means, EM, Cobweb, X-means and Farthest First are implemented. The output in this tab contains the confusion matrix, which shows how many errors there would be if the clusters were used instead of the true class.
Associate: To find the association on the given set of input data, ‘Associate’ can be used. It contains an implementation of the Apriori algorithm for learning association rules. These algorithms can identify statistical dependencies between groups of attributes, and compute all the rules that have a given minimum support as well as exceed a given confidence level. Here, association means how one set of attributes determines another set of attributes and after defining minimum support, it shows only those rules that contain the set of items out of the total transaction. Confidence indicates the number of times the condition has been found true.
Select Attributes: This tab can be used to identify the important attributes. It has two parts — one is to select an attribute using search methods like best-first, forward selection, random, exhaustive, genetic algorithm and ranking, while the other is an evaluation method like correlation-based, wrapper, information gain, chi-squared, etc.
Visualize: This tab can be used to visualise the result. It displays a scatter plot for every attribute.
The components of Experimenter
The Experimenter option available in Weka enables the user to perform some experiments on the data set by choosing different algorithms and analysing the output. It has the following components.
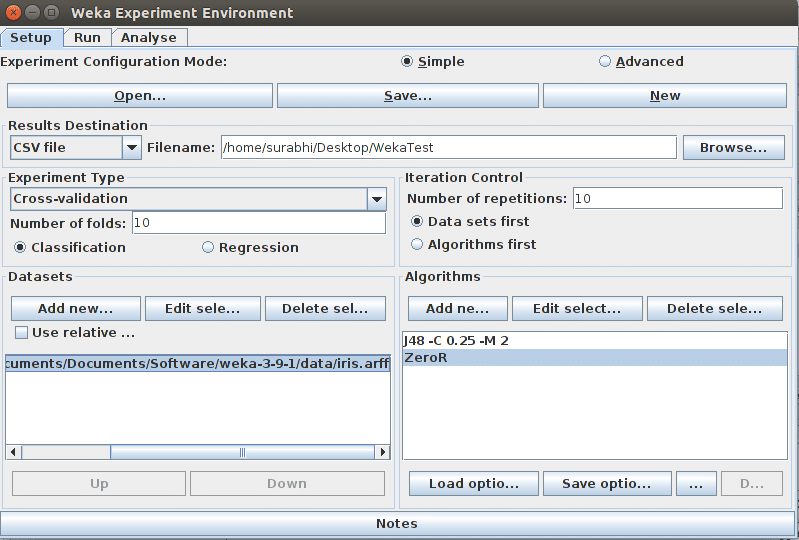
Setup: The first one is to set up the data sets, algorithms output destination, etc. Figure 4 shows an example of comparing the J4.8 decision tree with ZeroR on the IRIS data set. We can add more data sets and compare the outcome using more algorithms, if required.
Run: You can use this tab to run the experiment.
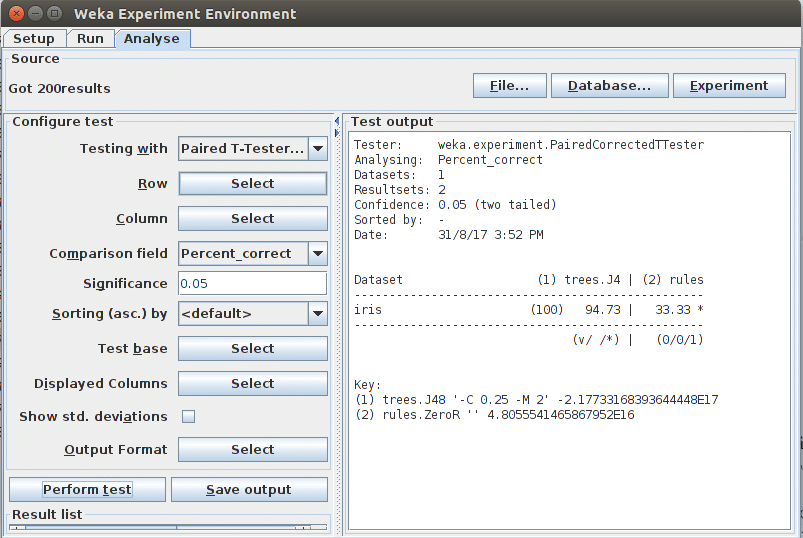
Analyse: This tab can be used to analyse the result. The output of the analysis of the previous experiment is shown in Figure 5. It shows that accuracy using J4.8 is 94.7 per cent and using Zero R is 33.33 per cent. At the bottom of the columns, there is a comparison of the number of times the second algorithm performed better than, the same as, or worse than the first algorithm. In this case, Algorithm 2 is worse than Algorithm 1, on one occasion. The output of the analyser can also be saved.
Weka can be seamlessly used with Java applications as well, just by calling the Java APIs, without writing the machine learning code. Weka for Big Data is still in the evolving phase. The latest distribution of Weka — 3.9.1 — sometimes gives a heap size error in the standard settings. That can be rectified by increasing the memory settings of Weka.
Weka provides a very interactive interface for building and testing various machine learning based models. Although there are many machine learning tools available, Weka facilitates quick learning when its powerful GUI is used. Its Experimental tab helps to choose the appropriate machine learning technique.

















{kind=link}