





























































If you’ve been curious about machine learning, this article is a good place to start exploring it. Apart from introducing readers to the basics, it also encourages you to learn by pointing you in the direction of various online courses and libraries.
All of a sudden, everyone has started talking about artificial intelligence or AI. Rapid advances in this field have certainly forced people to believe that this is going to drive innovation for at least a decade.
We experience the application of AI in our daily lives in innumerable ways. This could be in the form of an advertisement of a product on a social media platform where you were planning to buy something, or it could be a recommendation of another product that pops up as you’re purchasing a product from an e-commerce website. For example, a recommendation may be made to buy a mobile cover just as you’re buying a mobile phone, because the site’s system has predicted a higher probability of being able to sell a mobile cover along with the phone. So, knowingly or unknowingly, we are already experiencing AI.
There have been some incredible developments in AI that have led many to believe it is going to be the technology that will shape our future.
1. AlphaGo beats world champion at the game Go: In March 2016, Google’s DeepMind achieved a major victory in deep learning. AlphaGo, a division of the company, mastered the ancient Chinese game Go and defeated Lee Sedol, the world champion in four out of five games. According to many, Go is considered to be the most complex professional game because of a huge number of potential moves that can be made.
2. AI predicted US election results: Many of us were surprised by the outcome of the US presidential election results, but a startup called MogIA based in Mumbai was able to predict it successfully a month before the results were declared. The company analysed social media sentiment through millions of social media data points. This was the firm’s fourth successful prediction in a row.
3. AI improves cancer diagnosis: There have been some path-breaking innovations in the field of healthcare. It is believed that the healthcare industry is going to benefit the most from AI. There are AI programs that can now predict the occurrence of cancer with 90 per cent accuracy just by analysing the symptoms of a patient, which can help a doctor to start treatment early.
Many of us often confuse the terms ‘artificial intelligence’, ‘machine learning’ and ‘deep learning’. Hence, we use the terms interchangeably. But these are not the same things.
Artificial intelligence, in broader terms, can be described as a branch of computer science that can imitate human beings. It has been demonstrated that computers can be programmed to carry out very complex tasks that were earlier only performed by humans. From self-driving cars and Amazon’s Alexa or Apple’s Siri, to a computer program playing a game of chess, all of these are applications of artificial intelligence.
Machine learning can be referred to as a subset of AI. It is considered one of the most successful approaches to AI, but is not the only approach. For example, there are many chat bots that are rule based, i.e., they can answer only certain questions, depending on the way they were programmed. But they will not be able to learn anything new from those questions. So this can be categorised as AI as the chat bots replicate human-like behaviour, but can’t be termed as machine learning. Now, the question is: can machines really ‘learn’? How is it possible for a machine to learn if it doesn’t have a brain and a complex nervous system like humans? According to Arthur Samuel, “Machine learning can be defined as a field of study that gives computers the ability to learn without being explicitly programmed.” We can also define it as the computer’s ability to learn from experience to perform a certain task, whereby the performance will improve with experience. This is akin to a computer program playing chess, which can be categorised as machine learning, if it learns from previous experiences and subsequently makes better moves to win a game.
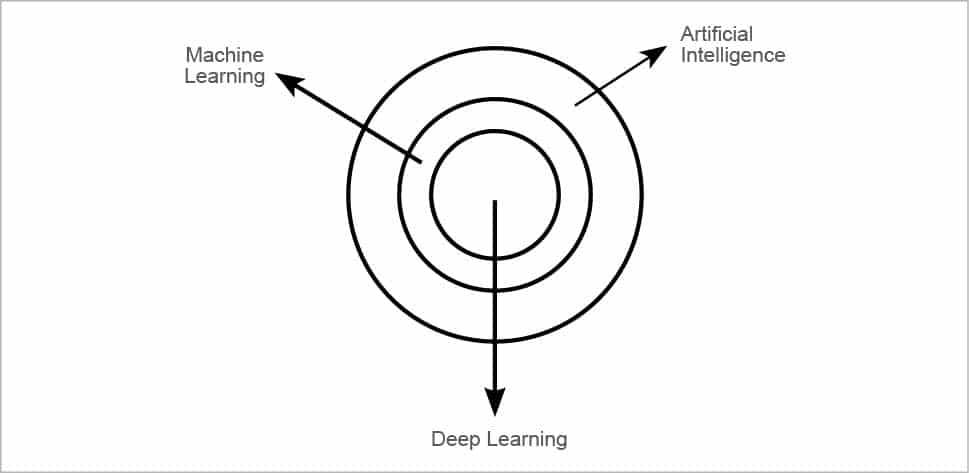
Deep learning can be categorised as a subset of machine learning. It uses neural networks to simulate human decision-making skills. A neural network consists of many neurons and hence resembles a human nervous system. Have you ever wondered how Facebook detects your face amongst many, in an image? Image detection is one of the examples of deep learning, which is much more complex as it needs lots of data to train itself. For instance, a deep learning algorithm can learn to recognise a car but will have to be trained on a huge data set which consists of cars as well as other objects. If this is not done, it might make a wrong decision like identifying a bus as a car. Hence, compared to other machine learning algorithms, a deep learning algorithm requires much more data in order to observe and understand every minute detail to make the right decisions.
From Figure 1, you can see how all these terms are related to each other, yet are not the same.
Now that you have understood the differences between artificial intelligence, machine learning and deep learning, let’s dig deeper into machine learning.
There are three main types of machine learning algorithms.
1. Supervised learning: The data set in supervised learning consists of input data as well as the expected output. The algorithm is a function which maps this input data to the expected outcome. The algorithm will continue to learn until the model achieves a desired level of accuracy. Then this model can be applied to new sets of data, for which the expected outcome is not available but needs to be predicted from a given set of data.
For instance, let’s look at a car manufacturing company that wants to set a price for its newest model. In order to do so, it can use this supervised learning model. The company’s input data set may consist of details of previous car models — their features like the number of air bags, electronic gadgets, etc. The output (or expected outcome) would be the sale price of the car. Now an algorithm can be designed to map those input parameters (or features) to the expected outcome. Once the algorithm achieves the desired level of accuracy, this model can be applied to the firm’s new car model. This can help the company predict the car price at which it should be launched.
For better results, the company can use a data set of car models of other manufacturers and their prices. This would help the company in setting a competitive price.
In machine learning, the best results are not achieved by using a great algorithm but by using the most data.
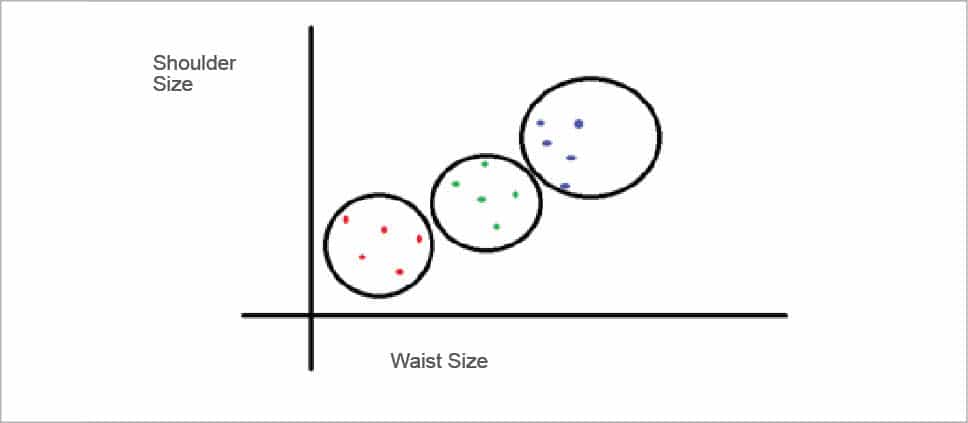
2. Unsupervised learning: The only difference between supervised and unsupervised learning is that the data set doesn’t have the expected outcome as in the supervised learning model. The data set will only have input parameters (or features) and the algorithm will have to predict the outcome. For instance, if a shirt manufacturing company is looking to manufacture three different sizes of shirts (small, medium and large), its data comprises the shoulder, waist and chest sizes of its customers. Now, depending upon this huge data set, the company needs to group the sizes into three categories so that there can be a best fit for everyone. Here, an unsupervised learning model can be used to group the different data points in three different sizes and predict an appropriate shirt size for every customer.
As per the graph given in Figure 2, let’s consider a company that has only the shoulder and waist measurements as input parameters of the data set. It will now have to categorise this data set into three groups, which can help the company predict the shirt size for every customer. This technique is known as clustering, in which the data set is clustered into the desired number of clusters. Most of the time, the data set is not like the one shown in this example. Data points that are very close to each other make it difficult to implement clustering. Also, clustering is just one of the many techniques used in unsupervised learning to predict the outcome.
3. Reinforcement learning: In reinforcement learning, a machine or an agent trains itself when exposed to a particular environment, by a process of trial and error. Let’s consider a kid who wants to learn to ride a bicycle. First, she will try to learn from someone who already knows how to ride a bicycle. Then, she will try riding on her own and might fall down a number of times. Learning from her previous mistakes, she will try to ride without falling. And when she finally rides the bike without falling, it can be considered as a reward for her efforts. Now let’s consider this kid as a machine or an agent who is getting punished (falling) for committing a mistake and earning a reward (not falling) for not committing any mistake. A chess-playing program can be a good example of this, whereby one wrong move will penalise the agent and it may lose a game, while a combination of one or more right moves will earn it a reward by making it win.
These are the three basic learning models of machine learning. As per the need, these models can be used in combination to generate a new model. For instance, supervised learning can sometimes be used along with unsupervised learning, depending upon the data set as well as the expected outcome.
People often feel that machine learning is only for someone who is good with mathematics or statistics, and will be impossible to learn for anyone else. This is a fallacy. Machine learning is not rocket science after all. The only thing that is required to learn it is eagerness and curiosity. The number of tools and libraries available has made it even easier to learn it. Google’s TensorFlow library, which is now open source, or the numerous Python libraries like NumPy and scikit-learn, are just a few of these. Anyone can use these libraries and even contribute to them to solve problems, as they are open source. You don’t need to worry about the complexities involved in your algorithm, like complex mathematical computations (such as gradient, matrix multiplication, etc) as this task can be left for these libraries to implement. Libraries make it easier for everyone so that instead of getting involved in implementing complex computations, the user can now focus on the application of the algorithm.
There are also many APIs available that can be used to implement an AI based system. One such API is IBM’s Watson – a cognitive, computing based AI system. Cognitive computing is a mixture of different techniques such as machine learning, natural language processing, AI, etc. Watson is capable of doing many tasks like answering a user’s queries, helping doctors to spot diseases, and a lot more.
If you are excited by the prospects that machine learning offers, our digital education era has made things easier for you. There are many massive open online courses (MOOC) offered by many companies. One such course is provided by Coursera-Machine Learning. This is taught by Andrew Ng, one of the co-founders of Coursera. This course will give you a basic understanding of the algorithms that are implemented in machine learning, and it includes both supervised learning and unsupervised learning. It’s a self-paced course but designed to be completed in 12 weeks. If you want to dig deeper and study deep learning, which is a subset of machine learning, you can learn it through another course provided by fast.ai. This course is split into two parts: Practical deep learning for coders (Part 1) and Cutting edge deep learning for coders (Part 2). Both have been designed for seven weeks each and provide you a great insight into deep learning. If you further want to specialise in deep learning, you can opt for a deep learning specialisation course by Coursera and deeplearning.ai.
We all know that theory without practice is like a body without life. So, for you to practice, there are many sources that can provide you a huge data set to test your knowledge and implement what you’ve learnt. One such website is Kaggle, which provides a diverse data set and can help you overcome your major hurdle, i.e., getting data to test your learning model.
If you sometimes feel lost in this journey of learning, when your algorithm does not work as expected or when you don’t understand a complex equation, remember the famous dialogue in the movie, The Pursuit of Happyness: “Don’t ever let someone tell you that you can’t do something. Not even me. You got a dream; you gotta protect it. When people can’t do something themselves, they’re gonna tell you that you can’t do it. You want something, go get it. Period.”

















Interesting article. So far I was afraid to learn about Machine learning as I have heard it requires strong knowledge in matrices and probability. But after reading your article, I am definitely going to take up a MOOC and maybe work on some projects. Thanks man!
I completed the Andrew Ng course suggested above few months ago. It was just a breeze, and opened my mind over this field. Of course, not enough to consider myself an expert, but now I know the basics of it reasonably well. It is very good especially where it details how to ensure ML systems are working properly.
Now, I am not exactly uneducated in Mathematics, as I got a degree in Physics. Essentially, all the math used in the course was already in my toolbox. Still, I believe that the course is well within the reach of people that did math at high school. Andrew covered the arguments from the point of view of someone that never saw a matrix: I believe anyone will understand it, as he focused a lot on intuition. Think about math as a language: at first you cannot do stuff with it, but at some point you start being able to hold simple conversations. As soon as that happens, you proficiency starts flying, as experience makes you better. Mathematics is a language to talk about logic in the most convenient way, so don’t be scared by it.
I totally encourage it to try the course. I think it can be tried for free, so nothing to loose!