

The management of Big Data is crucial if enterprises are to benefit from the huge volumes of data they generate each day. Hive is a tool built on top of Hadoop that can help to manage this data.
Hive is a data warehouse infrastructure tool to process structured data in Hadoop. It resides on top of Hadoop to summarise Big Data, and makes querying and analysing easy.
A little history about Apache Hive will help you understand why it came into existence. When Facebook started gathering data and ingesting it into Hadoop, the data was coming in at the rate of tens of GBs per day back in 2006. Then, in 2007, it grew to 1TB/day and within a few years increased to around 15TBs/day. Initially, Python scripts were written to ingest the data in Oracle databases, but with the increasing data rate and also the diversity in the sources/types of incoming data, this was becoming difficult. The Oracle instances were getting filled pretty fast and it was time to develop a new kind of system that handled large amounts of data. It was Facebook that first built Hive, so that most people who had SQL skills could use the new system with minimal changes, compared to what was required with other RDBMs.
The main features of Hive are:
- It stores schema in a database and processes data into HDFS.
- It is designed for OLAP.
- It provides an SQL-type language for querying, called HiveQL or HQL.
- It is familiar, fast, scalable and extensible.
Hive architecture is shown in Figure 1.
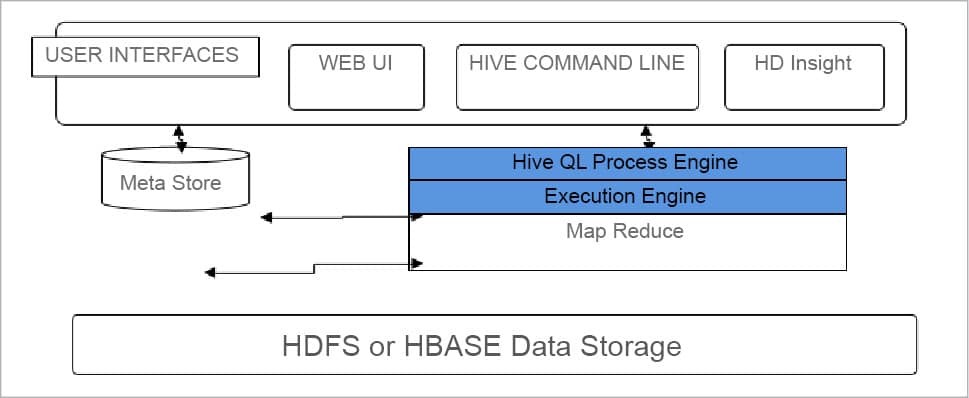
The components of Hive are listed in Table 1.
The importance of Hive in Hadoop
Apache Hive lets you work with Hadoop in a very efficient manner. It is a complete data warehouse infrastructure that is built on top of the Hadoop framework. Hive is uniquely placed to query data, and perform powerful analysis and data summarisation while working with large volumes of data. An integral part of Hive is the HiveQL query, which is an SQL-like interface that is used extensively to query what is stored in databases.
Hive has the distinct advantage of deploying high-speed data reads and writes within the data warehouses while managing large data sets that are distributed across multiple locations, all thanks to its SQL-like features. It provides a structure to the data that is already stored in the database. The users are able to connect with Hive using a command line tool and a JDBC driver.
How to implement Hive
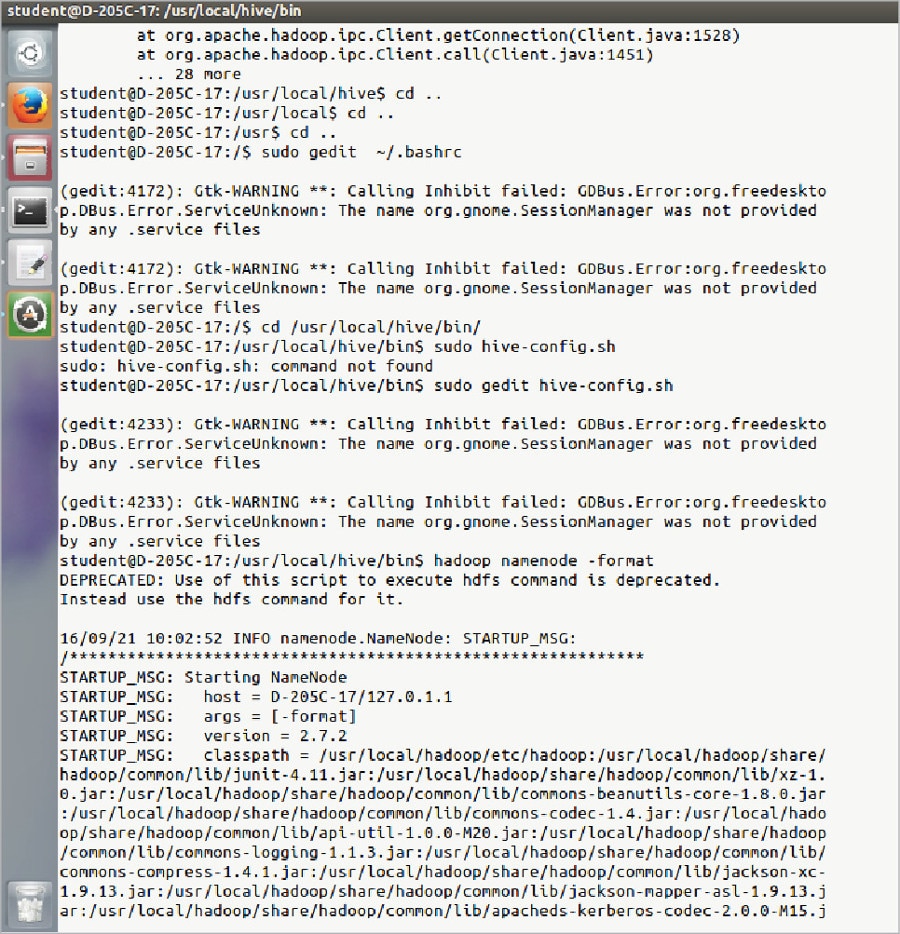
First, download Hive from http://apache.claz.org/hive/stable/. Next, download apache-hive-1.2.1-bin.tar.gz 26-Jun-2015 13:34 89M . Extract it manually and rename the folder as hive.
In the command prompt, type the following commands:
sudo mv hive /usr/local/hive sudo gedit ~/.bashrc # Set HIVE_HOME export HIVE_HOME=/usr/local/hive PATH=$PATH:$HIVE_HOME/bin export PATH user@ubuntu:~$ cd /usr/local/hive user@ubuntu:~$ sudo gedit hive-config.sh
Go to the line where the following statements are written:
# Allow alternate conf dir location.
HIVE_CONF_DIR=”${HIVE_CONF_DIR:-$HIVE_HOME/conf”
export HIVE_CONF_DIR=$HIVE_CONF_DIR
export HIVE_AUX_JARS_PATH=$HIVE_AUX_JARS_PATH
Below this line, write the following code:
export HADOOP_HOME=/usr/local/hadoop (write the path where the Hadoop file is)
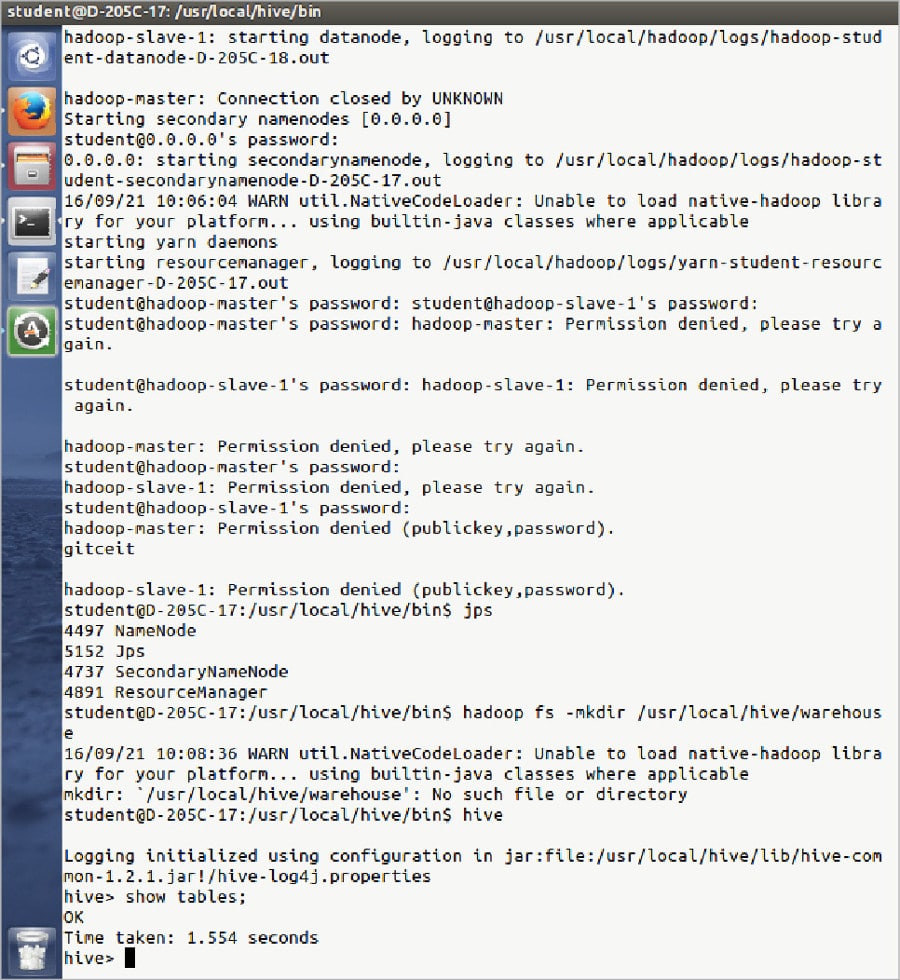
Now, start Hadoop. Type hive, and you will see the table 2.
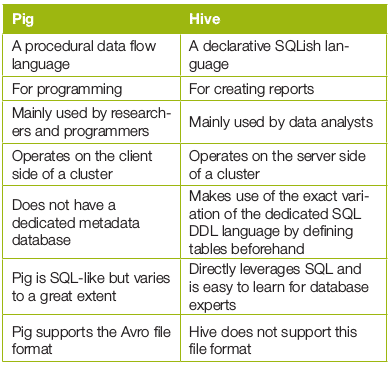 Pig vs Hive
Pig vs Hive
Table 2 illustrates the differences between pig and Hive.



{kind=link}