





























































MongoDB, HBase and Cassandra are the buzz words in the database domain. All three have their strong points and their failings. The author gives a very brief overview of each one, and prompts readers to explore these databases further.
In the autumn of 1998, Eric Brewer, a scientist at the University of California, Berkeley, presented a conjecture that fundamentally altered the perception of distributed data storage systems. Proved formally by researchers from MIT two years later, it is today known as the CAP Theorem, and is one of the factors that separates SQL from NoSQL.
So what exactly is this theorem?
We are all aware that there are fundamental principles that govern database systems, namely, the ACID properties —atomicity, consistency, isolation and durability. Brewer speculated that a distributed system can only provide two out of the three—consistency, availability and partition tolerance. Of course, this is a different ‘consistency’ from the ACID properties, in that the CAP theorem defines consistency as ‘every read receiving the most recent write’ while ACID treats it as a ‘valid state for the system to be in’.
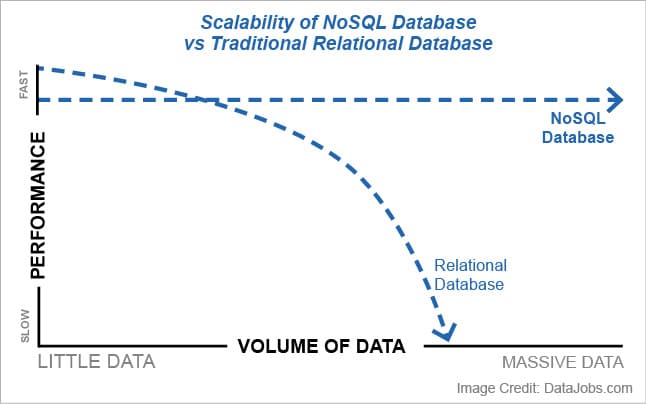
While SQL, being a relational database, deals primarily with ‘structured’ or schema-based data, NoSQL allows for the manipulation of unpredictable and ‘unstructured’ information in an attempt to fulfil the requirements of many of the Big Data models and architectures being integrated into businesses today. SQL is often criticised by many for its perceived ‘inability to scale’; while it can scale vertically, this also requires considerable hardware and, in turn, investment. Specifically, the scalability issue arises with latency and inadequate failover capabilities that are addressed often by advocating a switch to NoSQL based technologies, short for ‘Not only SQL’.
NoSQL to the rescue
Dare Obasanjo intuitively explains the difference between SQL and NoSQL in a blog post on this subject. He claims that SQL is similar to a vehicle with automatic transmission, while NoSQL falls into the manual transmission category. While automatic vehicles enforce certain integrity checks and rules that internally define the system, with manual vehicles, a lot of this responsibility falls on the users who may choose to forego some constraint checks and define their own instead, resulting in a performance improvement.
The reality, however, is that not everyone is required to use NoSQL as their de facto standard for performance because, as Obasanjo claims, even a manual car in traffic conditions is bound to perform similar to an automatic vehicle. What he means to say is that very few organisations (that handle large volumes of data like Google and Facebook) will actually be bound by the performance requirements that dictate a switch from SQL to NoSQL.
NoSQL technologies
Apache HBase
Apache HBase is an open source column-oriented NoSQL database that runs on top of HDFS, and is often used in cases where data access is required to be in real-time. Known as the ‘Hadoop Database’, it addresses problems pertaining to the manipulation of unstructured data, and offers significant functionality in areas such as scalability, failover support and sharding. The primary precondition of huge and sparse data sets (and we’re talking of millions of rows) is what usually introduces HBase into the design of a system.
HBase has a number of features with a focus on write-optimisation, although scans are also pretty fast on the system. However, it is not meant to be a replacement for the traditional relational database management system (RDBMS). One of the factors to be noted while deploying an HBase cluster is that there must be monitoring of nodes, since failure is cascading and can potentially bring down the system.
Recent updates have introduced Yarn integration within HBase, along with improved availability and support for data types. Originally designed based on Google’s BigTable to work on top of the Hadoop ecosystem, today HBase is used in production for real-time analytics at Facebook, for storage of graph data at Pinterest, and for personalisation of the content feed for users on Flipboard.
Apache Cassandra
In the conventional RDBMSs, replication and scaling were left to the users, which they discovered much to their dismay when large scale use cases came to the fore. Apache Cassandra presents a refreshing break from the configuration woes, going so far as to present its own query language, CQL, designed to be ‘exactly like SQL, except when it’s not’. Cassandra offers prebuilt support for multiple data centres, and all that the user is required to do is provide information about the other systems running it. For instance, adding a Cassandra node to a cluster can be as simple as booting a new machine, installing the software and telling it where the other nodes are.
Cassandra outdoes its competition in terms of ease of deployment, with the sole overhead being that of understanding the data model and how it will integrate with a given application. It does have the drawback of losing some of the performance on the introduction of a secondary indexing database. Offering lightning-fast write speeds and a predictable query performance makes Cassandra a great competitor in this segment.
MongoDB
The creators of MongoDB struck a compromise between its support for diverse data sets, its capacity to scale horizontally, and a functionality that is similar to that of a relational database. It is a great product to use out-of-the-box for a wide variety of applications in multiple scenarios. MongoDB is often one of the first preferences for developers due to how easy it is to understand and its gradual learning curve.
It does have its own share of issues, however, which adversely impact its suitability for reporting-style tasks in some cases, but it remains attractive for OLTP workloads. Secondary indexing, though, finds greater support in MongoDB than Cassandra, allowing for nested, complex queries to be executed. It does have a latency for failovers that is higher than Cassandra, but its ease of use outweighs this downside and makes MongoDB an extremely popular and widely employed NoSQL database.
















{kind=link}