

Catch up with Open Source Computer Vision (OpenCV), a computer vision and machine learning software library. As it is published under the BSD licence, you are free to develop and modify the source code.
Computer vision and digital image processing are currently being widely applied in face recognition, biometric validations, the Internet of Things (IoT), criminal investigation, signature pattern detection in banking, digital documents analysis, smart tag based vehicles for recognition at toll plazas, etc. All these applications use image and real-time video processing so that the live capture of multimedia impressions can be made for detailed analysis and predictions.
Computer vision is widely integrated in different applications including 2D and 3D image analytics, egomotion estimation, feature points detection, human-computer interaction (HCI), face recognition systems and mobile robotics. Computer vision is also applied in the fields of gesture recognition, object identification, segmentation recognition, motion understanding, stereopsis stereo vision, motion tracking, structure from motion (SFM), pattern recognition, augmented reality, decision making, scene reconstruction, etc.
The following are the key research areas in computer vision and image analytics:
- Deep neural networks for biometric evaluation
- Facial sentiment analysis and emotion recognition
- Real-time video analysis and recognition of key features
- Gesture recognition
- Visual representation learning
- Face smile detection
- Vein investigation and training for biometrics
- Multi-resolution approaches
- Radiomics analytics for medical data sets
- Forgery detection in digital images
- Content based image retrieval
- Automatic enhancement of images
- Identification and classification of objects in real-time
- Defects prediction in manufacturing lines using live images of machines
- Industrial robots with real-time vision for disaster management
- Image reconstruction and restoration
- Computational photography
- Morphological image processing
- Animate vision
- Photogrammetry
Prominent tools for computer vision and image analytics
There are a number of tools and libraries available to implement computer vision and image analytics. Table 1 lists these.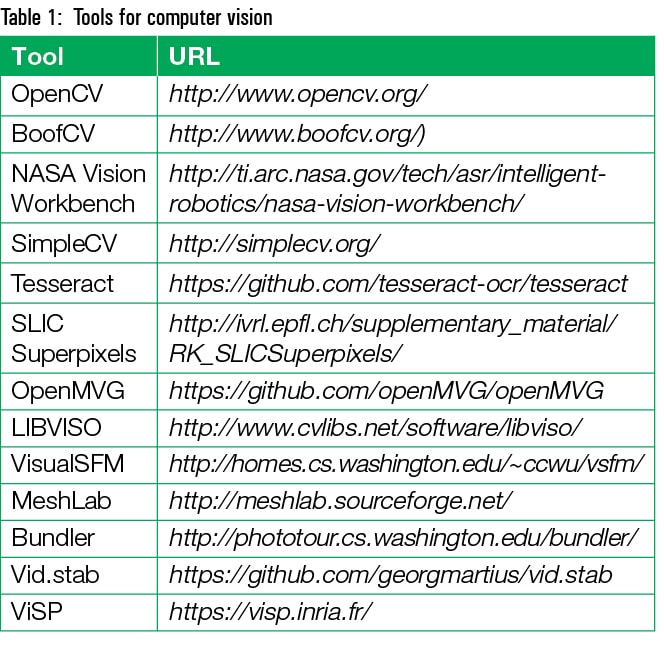 OpenCV
OpenCV
OpenCV (http://opensource.org) is a high performance library for digital image processing and computer vision, which is free and open source. It is equipped with a large set of functions and algorithms for real-time computer vision and predictive mining. OpenCV was devised and developed by Intel, and the current instances are supported by W. Garage and Itseez. It was developed so that real-time analytics of images and recognition can be done for assorted applications.
The statistical machine learning libraries used by OpenCV are:
- Deep neural networks (DNN)
- Convolutional neural networks (CNN)
- Boosting (meta-algorithm)
- Decision tree learning
- Gradient boosting trees
- Expectation-maximisation algorithm
- K-nearest neighbour algorithm
- Naive Bayes classifier
- Artificial neural networks
- Random forest
- Support vector machine (SVM)
Installation of OpenCV
The installation of OpenCV can be done for different programming languages including Python, Java, C++ and many others. OpenCV provides open connectivity with other platforms and programming languages, so that the algorithms of computer vision can be implemented without any concerns about compatibility or dependencies. It can be installed on different platforms including Android, Windows, Linux, BlackBerry, FreeBSD, OpenBSD, iOS, Maemo or OS X.
OpenCV has open connectivity for installation with different software suites. To integrate OpenCV with Scilab programming, use the following command:
--> atomsInstall(“scicv”) --> atomsInstall(“IPCV”)
…or:
--> atomsInstall(“Source Zip File”)
To install OpenCV for Python, use the following code:
$ pip install opencv-python $ pip install opencv-contrib-python

Real-time image capturing from a Web cam using OpenCV
In traditional implementations, the feature points of the images and computer vision files are recognised on the pre-saved disk images. This approach can be further enhanced using OpenCV, when the real-time video can be marked with the feature points or key points of the image frame in a live running video. The following is the source code of OpenCV that is executed in the Python environment. It can be used to implement real-time recognition of live feature points from a video shot on a Web cam.
import numpy as mynp import cv2 cap = cv2.VideoCapture(0) while(True): ret, frame = cap.read() MyGray = cv2.cvtColor(frame, cv2.COLOR_BGR2MYGRAY) MyGray = mynp.float32(MyGray) tdst = cv2.cornerHarris(MyGray,2,3,0.04) tdst = cv2.dilate(tdst,None) frame[tdst>0.01*tdst.max()]=[0,0,255] cv2.imshow(‘tdst’,frame) if cv2.waitKey(1) & 0xFF == ord(‘q’): break cap.release() cv2.destroyAllWindows()
Identification of image forgery using OpenCV
With the emergence and implementation of digital authentication in assorted applications, the identification of original user impressions is one of the key challenges today. Nowadays, many organisations ask for documents and certificates signed and scanned by applicants for self-attestation. This also happens when applying for new mobile SIM cards. However, imposters can take scanned signatures from any other document and put them in the required document using digital image editing tools like Adobe Photoshop, PaintBrush or PhotoEditors. There are a number of image editing tools available for the transformation of an actual image into a new image. This type of implementation can be (and often is) used for creating the new forged copy of the document, without the knowledge or permission of the actual applicant.

Figures 2 and 3 depict the process of forgery detection in a new document where the signatures are copied from another source.
The following source code written in Python and OpenCV presents the implementation of Flann based evaluation of images. OpenCV has enormous algorithms for the extraction of features in the images as well as in videos. Using such approaches, the manipulation in captured files can be identified and plotted.
import numpy as mynp import cv2 from matplotlib import pyplot as plt MIN_COUNT = 10 myimage1 = cv2.imread(‘’ChequewithCopiedSignature.png’,0) myimage2 = cv2.imread(‘OriginalCheque.png’,0) sift = cv2.xfeatures2d.SIFT_create() # find the keypoints and descriptors with SIFT k1, im1 = sift.detectAndCompute(myimage1,None) k2, im2 = sift.detectAndCompute(myimage2,None) FLANN_INDEX_KDTREE = 0 index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5) search_params = dict(checks = 50) flann = cv2.FlannBasedMatcher(index_params, search_params) matches = flann.knnMatch(im1,im2,k=2) # store all the good matches as per Lowe’s ratio test. good = [] for m,n in matches: if m.distance < 0.7*n.distance: good.append(m) if len(good)>MIN_COUNT: src_pts = mynp.float32([ k1[m.queryIdx].pt for m in good ]).reshape(-1,1,2) dst_pts = mynp.float32([ k2[m.trainIdx].pt for m in good ]).reshape(-1,1,2) M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0) matchesMask = mask.ravel().tolist() h,w = myimage1.shape pts = mynp.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2) dst = cv2.perspectiveTransform(pts,M) myimage2 = cv2.polylines(myimage2,[mynp.int32(dst)],True,255,3, cv2.LINE_AA) else: print “Not enough matches are found - %d/%d” % (len(good),MIN_COUNT) matchesMask = None draw_params = dict(matchColor = (0,255,0), # draw matches in green color singlePointColor = None, matchesMask = matchesMask, # draw only inliers flags = 2) myimg9 = cv2.drawMatches(myimage1,k1,myimage2,k2,good,None,**draw_params) plt.imshow(myimg9, ‘gray’),plt.show()
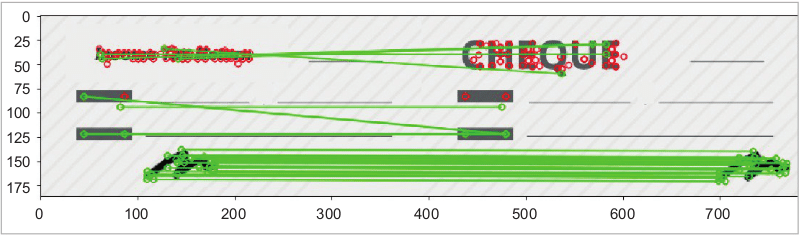
It is evident from Figure 4 that the pixels have been identified in the new image (in which the signature has been copied from another source). So the marking of pixel values can be done using machine learning and inbuilt methods for prediction in OpenCV. Even if the person makes use of highly effective tools for image editing, the pixels from where the image segment is taken can be identified.



{kind=link}