






























































In simple layman terms, machine learning helps in making machines acquire human-like behaviour, while retaining their original capabilities. Here’s a quick introduction to the subject.
Machine learning (ML) is a fascinating field in computer science wherein the emphasis is to meet the challenge of the Turing test. The Turing test is focused on providing sufficient intelligence to machines so as to make it difficult for anyone to distinguish between humans and machines. CAPTCHAs were introduced to avoid illegal intrusions into critical online systems by machines impersonating humans. With the advent of improved and more accurate learning algorithms, it seems that in the near future, machines will start outperforming human beings in intelligence.
Arthur Samuel is known as the father of ML. In the 1960s, he visualised a computer that could learn the moves of checker-board games through training, and once sufficient experience was gained it would be able to think by itself and plan the next moves accordingly, to ultimately win games against humans. He turned this thought into reality and we are today witnessing how rapidly this field is emerging. He defined ML as, “The field of study that gives computers the ability to learn without being explicitly programmed.”

The need for machine learning
Humans are naturally good at recognition. Early in life, a baby starts recognising her mother’s voice and face, while children soon start identifying various categories of animals, birds or vehicles through observations and a little experience. On the other hand, machines are very powerful in processing and in rapid computation when the input is data intensive. They can keep on doing the same task repeatedly, with the same efficiency, without getting exhausted, which is not possible in the case of humans. Human performance deteriorates over time, when working without a break. The only limitation for machines is that they have very poor recognition capabilities, so if somehow they can be trained like humans, they can start performing better over time and with experience.
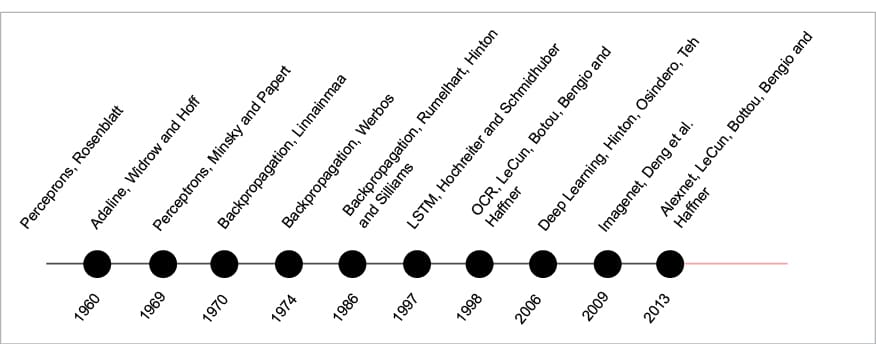
Many complex tasks that are really challenging for humans can be automated. If the merits of both humans and machines can be combined, this can result in great performance. It is impossible as of now to equip humans with machine-like capabilities, so an easier option is to make machines learn recognition and gain the other capabilities that humans have. This is how the field of machine learning has evolved (Figure 2).
In the scenario we just discussed, machines can serve humans well and reduce the effort required by us in applications such as biometric authentication, sentiment analysis, recommender systems, anomaly detection, navigation and many others.
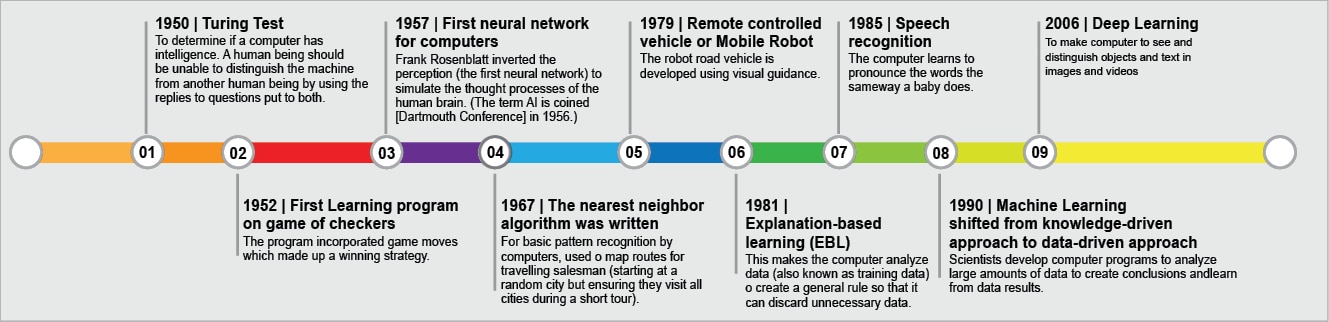
Machine learning paradigms
There are three paradigms of ML algorithms, which are discussed in the following sections.
Supervised learning: When data comes with labelled examples stating the class or category of each example, this is called the supervised learning approach. Machines are trained under supervision by providing sufficient examples with class label information. This is learning from examples.
- Classification is a supervised learning strategy in which a model is built by providing some training examples; then test samples are supplied to the model for evaluating its recognition capability. The following are some common examples where classification can be used.
- A marketing manager analyses the data of customers to predict if they will buy a new cell-phone.
- A bank manager classifies the loan applicants as safe or risky.
- A space scientist classifies a spatial object as a planet, satellite or asteroid.
- A medical practitioner diagnoses a disease from past records.
- Typically, in classification, the categories (class label) are represented by discrete values, where ordering among values has no meaning.
- Data classification is a two-step process. In the first step, a model is built by describing a predetermined set of data classes or concepts. In the second step, the model is used for classification and its accuracy is estimated. If the accuracy is acceptable, then the model is used to classify future data instances for which the classes are unknown.
- Some commonly used classifiers include the decision tree, artificial neural networks and support vector machines.
Unsupervised learning: In this case, the machine is equipped with examples but not classes; it is somewhat an exploratory analysis. This is learning from observation.
- Clustering is an unsupervised learning approach for organising objects into groups whose members are similar in some way.
- Objects in a cluster possess the principle of maximum intra-cluster similarity and minimum inter-cluster similarity.
- Different algorithms use different measures for similarity between objects to group them together. In clustering, learning takes place through observation rather than training.
- Some applications of clustering include anomaly or fraud detection and speaker diarisation.
Reinforcement learning: An algorithm is given a penalty or a reward for successfully completing a task or failing to do it, respectively. This can be a small task of a robot identifying a hurdle or an obstacle in front of it. This is incentive based learning.
ML based problem-solving approaches
A conventional pipeline for an ML application is depicted in Figure 4. It consists of the following four stages.
- Data preparation: Input data is usually pre-processed, and then fed into the next module for further processing.
- Feature extraction: Features are quantitative variables which best represent the input data. Several algorithms for feature extraction are available in research literature, specific to different domains.
- Classifier: A typical task of ML is classification. It goes through the data instances and classifies them into one or another class after building the classifier model using training data.
- Prediction and evaluation: A classifier predicts the class label of a given instance on an unknown sample. The prediction performance is measured for correctness, using performance metrics such as accuracy.
An illustration
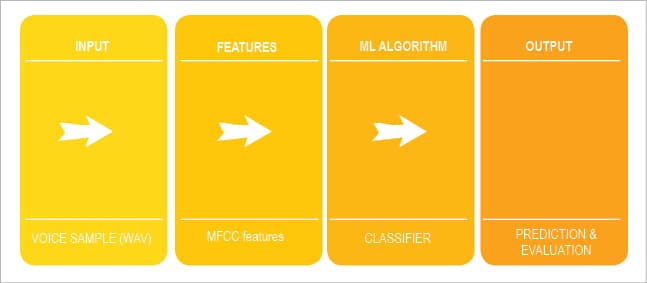
Let’s illustrate this pipeline using the specific application of speaker verification. In this system, a user wants to access an online banking system remotely using his voice as the password. During the enrolment stage, all authentic users are registered with the systems by providing their voice samples. These samples are used to build models for each user. During the authentication stage, a registered user provides his voice sample to the system, which is matched with the stored voice templates of that user. If a match is found successful, the user is accepted as genuine; else his access is rejected.
For this task, a voice sample is represented as features. Usually audio data is described using very well known mel-frequency cepstral coefficient (MFCC) features. These coefficients are real numbers which are passed to a classifier as input. The classifier builds a model using this data and uses the model to predict the class of an unknown sample.
Tools for building machine learning applications
This is the era of ML, so plenty of tools are available for it and are also being developed frequently. In Table 1, some tools and software packages prominent in this field have been summarised. Apart from these, there are many dedicated options available for certain domains.

The big question: Can machines outperform humans?
The Hollywood movie, 2001: A Space Odyssey, which was released in the 1960s, predicted that there would be a time when machines would not only outperform humans but also take charge and start treating humans as their slaves. In the movie, there is a scene in which the machine refuses to execute commands given by a human operator, and instead operates by itself. Similar concepts are also seen in movies like Wall E and the Terminator series. Recently, Facebook also observed a self-programming phenomenon and suspended its further use. As of now, many tasks cannot be accomplished properly without human intervention. However, the days are not far when machines will be self-sustaining.
Potential applications of machine learning
Machine learning is a multi-disciplinary field, which encompasses several domains including cloud computing, artificial intelligence, probability and statistics, high performance computing, Big Data, genetic algorithms, etc.
The following are some typical applications of ML:
- Speech processing – A speech signal can be analysed to recognise people, messages, gender, emotions, language, etc.
- Music information retrieval – A song can be processed to identify instruments, singers, composers, the raag, genre, etc.
- Computer vision – A machine can be used to recognise different objects that are part of the queried image. It can also be used for image tagging automatically. Further, it can be used to predict the gender, age and mood of the person. Pictures similar to the query image can also be obtained.
- Video processing – Analysis of a video may lead to successfully tracking some suspicious event that occurred during a certain time frame, or to detect the presence of a specific person in a video clip.
- Sentiment analysis – Movie or product reviews by users can be analysed to find out their sentiments, which can be used to recommend the product or movie to other users with similar interests. It is known that politicians also have started using the results of such analysis to track the mood of their voters and change the strategy for their election campaign.
- Recommender systems – Systems can understand the preferences of the customers by observing browsing patterns or purchase history and can recommend relevant items to simplify the searching process.
- Anomaly detection – Fraudulent transactions can be revealed with the help of such outlier analysis.
- Document classification – Several Web documents can be classified based on certain terms (keywords).
- Cognitive radio – Intelligent spectrum sensing can be achieved by identifying idle spectrum bands for the optimal use of the spectrum.
- Robotics – Robots can be trained to navigate accurately and then used in space or to perform surgeries.
Many giant companies have set up research labs for machine learning. These include Google, Amazon, Microsoft, Facebook, Yahoo, Samsung, Xerox, NVIDIA and Baidu, to name a few. The growth of ML can be assessed from the fact that several courses on it are being offered by reputed universities on MOOC platforms and job offerings in this field are on the rise. The technologies being developed, including the hardware (such as NVIDIA GPU cards), have also arrived in the market.
Deep learning: A brief overview
Deep learning is a recent development in the field of ML. It has enabled researchers to design algorithms that can run in parallel on GPUs and achieve quick results on huge amounts of training data. Currently, the world is populated with data everywhere—in different formats such as text, audio, image, and video—which includes spatial data, e-commerce data, surveillance data, social network data and so on. Handling such large volumes of data was not possible some years ago, since the systems in those days were ‘data rich, but information poor’. GPUs have solved this issue, and mammoth sized computations can now be carried out in a limited amount of time. Li Deng mentions [see Reference 2 at the end of the article] that deep learning has become enormously popular nowadays due to the availability of great processing power (GPUs), low cost hardware, and advances in the ML and signal processing domains. All the giant companies worldwide have moved towards deep learning based solutions. And many innovative, small startups (such as Nuance, Clarifai, etc) are following suit.
Applications of deep learning
Listed below are some of the interesting applications of deep learning:
- Skype Language Translator can translate one language into another, in real-time.
- Google Deep Mind has recently defeated the human champion of the Go game.
- Facebook face recognition can recognise the same individual in different photos with almost 97 per cent accuracy.

















{kind=link}
Really machine learning helps in influencing machines to secure human-like conduct, while holding their unique abilities. Here’s a snappy prologue to the subject. Thank you for your information