





























































The Tensor Virtual Machine stack began as a research project at the SAMPL (System, Architecture, Machine learning and Programming Language) group of the Paul G. Allen School of Computer Science & Engineering, at the University of Washington in the US. This project is now driven by an open source community, and involves multiple industry and academic institutions.
Tensor Virtual Machine or TVM is an open deep learning compiler stack to compile various deep learning models from different frameworks to the CPU, GPU or specialised accelerators. TVM supports model compilation from a wide range of frontends like TensorFlow, Onnx, Keras, Mxnet, Darknet, CoreML and Caffe2. TVM-compiled modules can be deployed on backends like LLVM (JavaScript or WASM, AMD GPU, ARM or X86), NVidia GPU (CUDA), OpenCL and Metal. TVM also supports runtime bindings for programming languages like JavaScript, Java, Python, C++ and Golang. With a wide range of frontend, backend and runtime bindings, this deep learning compiler enables developers to integrate and deploy deep learning models from any framework to any hardware, via any programming language.
The TVM architecture
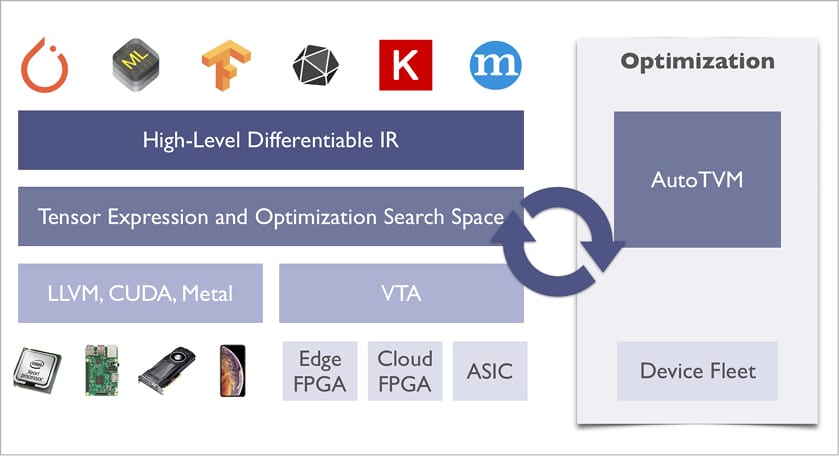
TVM provides a two-level optimisation mechanism, as shown in Figure 1. The first level of optimisation happens at the graph level after a model is imported. This optimisation provides graph level fusion, layout transformation and memory management. Later optimisation happens at the tensor level – at the code-generation layer and is based on the paper https://arxiv.org/abs/1802.04799.
The TVM stack comprises multiple layers, as shown in Figure 1. The top and user-facing layer is the framework layer. This is written in Python and contains various import modules for each framework. This layer converts the models from any framework (Tensorflow, Caffe2, etc) to a graph representation of TVM. At the computation graph optimisation layer, the graph representation is optimised by various passes like precompute prune which prunes the graph nodes that can be computed at compilation time, the layout conversion pass which adds the necessary layout conversion operations (or nodes) across layers if there is a layout mismatch between layers, and a fusion pass which joins the computation of multiple nodes into one based on certain rules. These optimisations reduce overall computation costs considerably.
The next layer in the stack is the Tensor compute description which basically generates a computation definition of each node in the graph, based on the inputs. The TOPI sub-module in the stack implements the computes for all the operators. The next layer in the stack is the schedule space and optimisations. This layer is very important in terms of low level as well as hardware-specific optimisations.
Build, integration and deployment
As shown in Figure 2, TVM provides frontends to import trained deep learning models from various frameworks. The TVM compiler outputs a library which contains the operator (layer) compute definitions, the graph represented in JSON format, and a param blob which contains all the parameters of the model. TVM also provides various programming language binding libraries or packages, which can be imported or linked against, to load the compiled artifacts. Depending on the target hardware configured, the TVM runtime can be as small as approximately 300kB.
To demonstrate the end-to-end capabilities of the TVM compiler stack here, let us look at an example of importing, compiling and running a TensorFlow vision model, MobilenetV1, on x86 and NVidia (CUDA) targets.
Step 1: The setup
TVM can be setup by building from source or using Docker. The simple steps given below can set up the environment for us. Please refer to https://docs.tvm.ai/install/index.html for other ways of setting up.
Download the source as follows:
test@test-pc:~$git clone --recursive https://github.com/dmlc/tvm
Build and run Docker using the following code:
test@test-pc:~$ cd tvm test@test-pc:~$ ./docker/bash.sh tvmai/demo-cpu
You may choose to launch Jupyter, if needed, inside Docker, as follows:
test@test-pc:~$jupyter notebook
One can verify the setup by just importing TVM as shown below, in Notebook or in a Python shell.
import tvm
Step 2: Downloading the TensorFlow MobilenetV1 model
Various TensorFlow official models can be found at https://github.com/tensorflow/models/tree/master/research/slim. Use the following link to download the MobilenetV1 official model from TensorFlow: http://download.tensorflow.org/models/mobilenet_v1_2018_02_22/mobilenet_v1_1.0_224.tgz.
Extract the downloaded archive and look for mobilenet_v2_1.0_224_frozen.pb. This is the Protobuf format for a frozen model after training. Latest version of TVM also supports importing Tensorflow saved bundle. Model-specific information like input shapes, input and output node names is needed to compile a model from TensorFlow. For TensorFlow, this information is available in the file below, from Mobilenet. The input shape for Mobilenet is (1, 244, 244, 3), which is the image resolution
cat mobilenet_v1_1.0_224_info.txt Model: mobilenet_v1_1.0_224 Input: input Output: MobilenetV1/Predictions/Reshape_1
Step 3: Importing and compiling
The latest version of TVM provides a sub-module relay (tvm.relay) which contains all the frontend import utilities. Please refer to the code snippet given below to import and build the TensorFlow model on TVM.
# import tvm and tensorflow
import tvm
import tensorflow as tf
# We want to build TVM for llvm target (x86)
target = ‘llvm’
# Import the tensorflow model.
with tf.gfile.FastGFile(os.path.join(“mobilenet_v1_1.0_224_frozen.pb”), ‘rb’) as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
graph = tf.import_graph_def(graph_def, name=’’)
# Call the utility to import the graph definition into default graph.
graph_def = tf_testing.ProcessGraphDefParam(graph_def)
# Add shapes to the graph.
# Alternatively can use “add_shapes=True” while exporting graph from Tensorflow.
with tf.Session() as sess:
graph_def = tvm.relay.testing.tf.AddShapesToGraphDef(sess, ‘MobilenetV1/Predictions/Reshape_1’)
# Set input shape for graph input.
shape_dict = {‘input’: (1, 244, 244, 3)}
# Import graph through frontend
sym, params = relay.frontend.from_tensorflow(graph_def, shape=shape_dict)
# sym : represents tvm symbol graph constructed from imported model.
# params : graph parameters imported from model.
# Compile the model on TVM.
# The target here indicates the compiler to build the output for ‘llvm’
graph, lib, params = relay.build(sym, target=target, params=params)
Step 4: Saving the compiler output
In the above step, the build process has resulted in a graph, lib and params. The graph is an object which holds the compiler graph. lib represents the library for the ‘llvm’ target and params represents the parameters for the model. Please refer to the code snippet below to save the compilation output to the disk.
# nnvm is part of TVM which is old version of compiler. # we use the save_param_dict from here. import nnvm # Save the model as a library. lib.export_library(“libmobilenet.so”) # Save the graph definition as a JSON. with open(“mobilenet.json”, “w”) as fo: fo.write(graph.json()) # Save the params. with open(“mobilenet.params”, “wb”) as fo: fo.write(nnvm.compiler.save_param_dict(params))
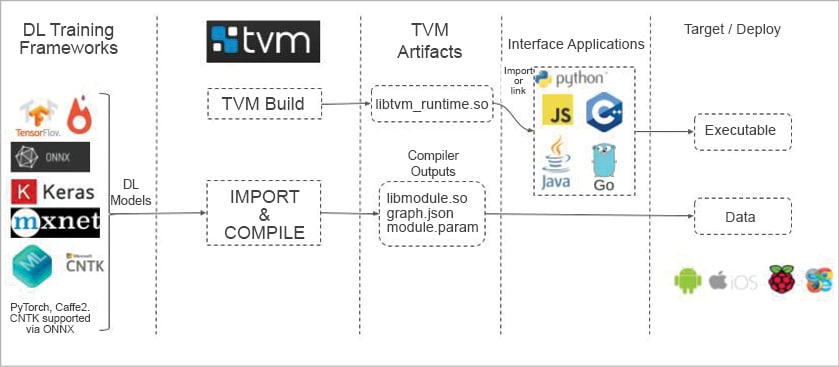
Step 5: Loading and executing
The saved outputs from the compilation process are a library, a JSON and a params binary file. We may take these executables as targets for deploying data files. Along with these, we need a target-specific application to load the compiled model on the target. In our case, the target is x86 and for the deployment explanation I am choosing Python. The code snippet which follows with inlined documentation shows a Python application to deploy and infer.
# Load the module loaded_lib = tvm.module.load(“libmobilenet.so”) # Read graph and params. loaded_json = open(“mobilenet.json”).read() loaded_params = bytearray(open(“mobilenet.params”, “rb”).read()) # graph runtime initializes runtime from loaded module, # graph and on given context. In this case the context is CPU. from tvm.contrib import graph_runtime module = graph_runtime.create(loaded_json, loaded_lib, tvm.cpu(0)) # Initialize the parameters. params = nnvm.compiler.load_param_dict(loaded_params) module.load_params(loaded_params) # Initialize some random data for model input. input_data = np.random.uniform(size=(1, 244, 244, 3)).astype(‘float32’) # Set model input module.set_input(x=input_data) # Execute the Model module.run() # Get the first output out = module.get_output(0) # out is an NDArray type and out.asnumpy() can # return an numpy array for the same.
The example given above explains the import, compilation and execution on target for a TensorFlow model on a x86 target using a Python runtime interface. Given below are a few choices for the usage of other options for frontends, hardware targets and programming languages.
We can compile various different target devices by changing target=‘llvm’ in Step 3 above. TVM supports a wide range of targets like ‘llvm’, ‘cuda’, ‘opencl’, ‘metal’, ‘rocm’, ‘vulkan’, ‘nvptx’, ‘llvm-device=arm_cpu’, ‘opencl-device=mali’ and ‘aocl_sw_emu’. We may also need to specify target_host while using accelerators from Linux hosts like CUDA, OpenCL, etc. We may need to pass target_host=’llvm’. Cross-compilation is also possible, bypassing additional options to LLVM. For example, we may pass target_host=’llvm -target=aarch64-linux-gnu’ for an Android platform.
Apart from Python, TVM supports various programming languages while deploying a compiled module. Please refer to https://docs.tvm.ai/deploy/index.html for other programming languages.
Cross-compilation and RPC
To be developer friendly, TVM supports RPC to cross-compile the model, and to deploy and test it. RPC enables faster development by remote-loading compiler output on target, and by setting input and getting the output from a target to the host seamlessly. If you are interested, refer to https://docs.tvm.ai/tutorials/cross_compilation_and_rpc.html#.
For Android developers, TVM provides an RPC application as a quick-start to compile a model, deploy it remotely via RPC and test it (https://github.com/dmlc/tvm/blob/master/apps/android_deploy/README.md#build-and-installation).
AutoTVM
Apart from the standard compilation process, TVM also provides a framework to infer the best hardware parameters customised for the real underlying hardware. The tvm.autotvm sub-module provides various APIs for this. Refer to https://docs.tvm.ai/api/python/autotvm.html?highlight=autotvm#module-tvm.autotvm to know more about AutoTVM.
Versatile Tensor Accelerator (VTA)
VTA is an open, generic and customisable deep learning accelerator with a complete TVM based compiler stack. It was designed to expose the most salient and common characteristics of mainstream deep learning accelerators. Together, TVM and VTA form an end-to-end hardware-software deep learning system stack that includes hardware design, drivers, a JIT runtime, and an optimising compiler stack based on TVM. Do refer to https://docs.tvm.ai/vta/index.html to know more about VTA.
Benchmark
Benchmark information for various models like densenet, mobilenet, resnet, squeezenet, etc, on different platforms like ARM CPU, ARM GPU, Nvidia GPU and AMD GPU is available at https://github.com/dmlc/tvm/wiki/Benchmark.
















