






























































A database is an organised collection of data that is generally stored and accessed electronically from a computer system. There are numerous databases that have been developed to meet different needs. This article discusses the various aspects of the Cassandra DB — its architecture, its components, read/write operations and a few of its query language syntaxes, with explanations.
Cassandra is a free and open source distributed database that has been designed and developed to handle a large amount of structured, semi-structured and unstructured data. It is an Apache product based on the wide-column NoSQL database, and it can re-collect/recapture and store data. It supports an easy replication process. Cassandra is written in Java, and is used for time-series data such as chats, logs and so on.
Here are some key reasons for using this database:
- Simple interface without any complex joins
- Non-relational and schema-less model
- High fulfilment and fast performance
 Cassandra’s architecture and its components
Cassandra’s architecture and its components
Cassandra is based on the ring architecture. This is a collection of nodes that are interconnected with each other. All nodes are considered as equal and have a similar role. There are no slave or master nodes.
The Cassandra architecture comprises many components. These are:
- Nodes
- Data centre
- Clusters
- Commit logs
- Memtables
- SSTables
- Bloom filters
Let us explore each component to understand the architecture better.
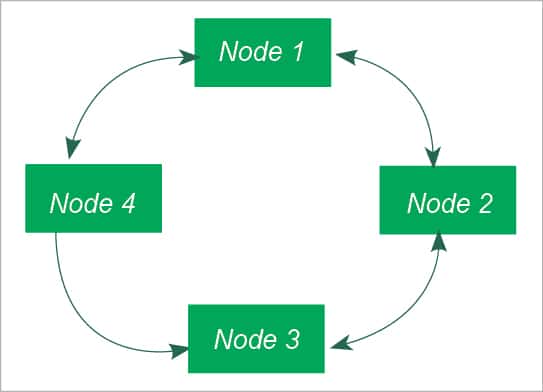
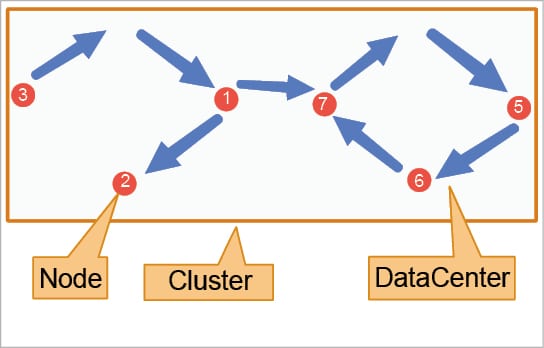
Node: A node is where data is stored. We can perform read and write operations on any node. If, at any time, a node goes down, then read and write operations or requests can be performed by other nodes without any failure.
Data centre: This is a collection of associated nodes, and consists of the same data across all nodes.
Cluster: This comprises either a single or multiple data centres.
Commit log: For durability purposes and to avoid losing data, Cassandra appends writes to the commit log.
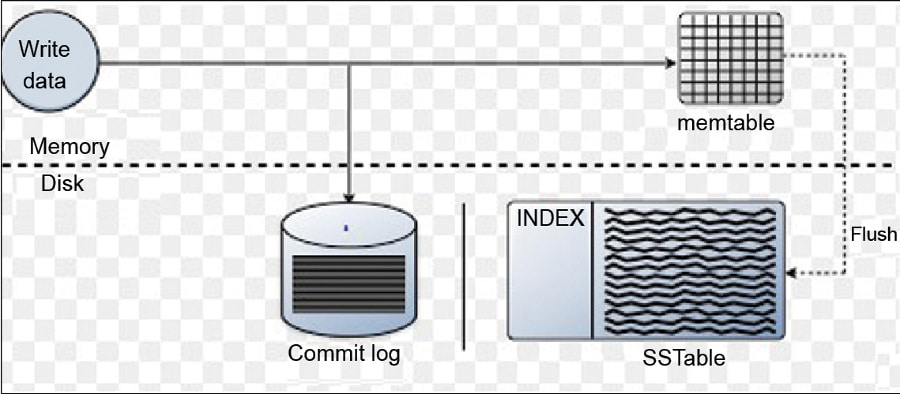
Memtable: This is an in-memory data structure that Cassandra stores the data in. After performing the commit log operation, data is written to the memtable.
SSTable: This is a disk file; once the memtable is full or exceeds the configurable threshold value (while configuring or installing Cassandra, this value is set), then data will be flushed from the memtable and stored in the SSTable.
Bloom filter: This is used to find an appropriate SSTable that holds the required data.
Read and write operations
Unlike some conventional relational databases, Cassandra can perform read and write operations to any node. Here, we will discuss the steps to perform a write and read operation.
 The write operation
The write operation
a. Each write operation of the nodes is picked up by the commit logs written in the nodes.
b. After that, this data is captured and stored in the memtable. If the memtable is full, data will be written to the SSTable data file.
c. As shown in Figure 3, once the memtable is full, the flush process comes into play. This is the process of turning the memtable into an SSTable.
d. Cassandra automatically discards unnecessary data from SSTable.
The read operation
Once the write operation is done, Cassandra gets the value from the memtable and inspects the bloom filter to find the right SSTable that holds the necessary data, which it will start to read.
Understanding basic Cassandra query language (CQL) commands
Let us now explore the basic Cassandra query language (CQL) syntax. But before that, we should understand what CQL is. Basically, Cassandra query language (CQL) is for the Cassandra (C*) database. It is very similar to the structured query language (SQL). The way to interact with Cassandra is through the CQL shell/ cqlsh. In cqlsh, we can perform many operations like create, alter and drop keyspace, as shown in the table above.
In the following section, we will go through each command with an example.
Keyspace: This is a name space in Cassandra that defines data replication on nodes. A cluster contains one keyspace per node. While creating a keyspace, we should keep in mind the points given below.
Data replication: Cassandra provides a strategy to determine the nodes where replicas (copies) are placed. So in case any node goes down, your data remains safe and available since there are copies on other nodes as well. This is the advantage of using Cassandra.
Replication factor: This is the number of replicas in the cluster that will receive copies of the same data. If the Replication_factor = 2, it means data will be replicated to two different nodes.
SimpleStrategy: This is the process by which replicas are placed in the ring. It is used when we have only one data centre. As a best practice, we should not use this strategy in a production environment.
NetworkTopologyStrategy: This strategy is used when we have multiple data centres, and can be used in a production environment.
Durable_writes: Another keyspace option is durable_writes, and by default, it is always set to‘true’. If it’s set to ‘false’, then no updates will be written to the commit log.
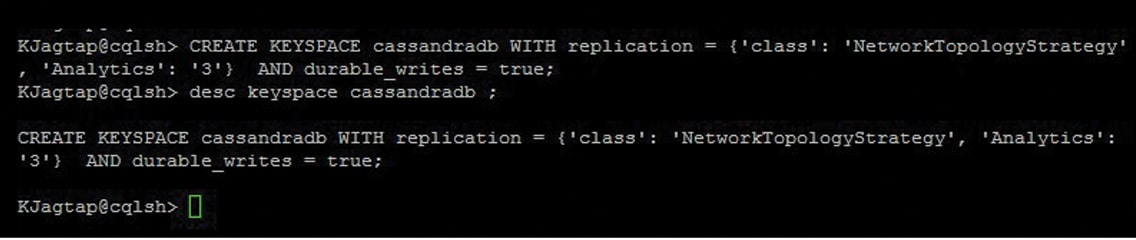
Here is an example of the ‘create keyspace’ command:
CREATE KEYSPACE Keyspace cassandradb WITH replication = {'class': NetworkTopologyStrategy, 'Analytics’: 1} And durable_writes = true;
- In Figure 4, Cassandradb is used as keyspace_name.
- NetworkTopologyStrategy is used as the replication strategy.
- Analytics is used as replication_factor name.

Now the Cassandradb keyspace is created and we can use the ‘describe keyspace’ command to see keyspace as shown in Figure 5.
Here is an example of the ‘alter keyspace’ command:
ALTER KEYSPACE cassandradb WITH replication = {‘class’: ‘SimpleStrategy’, ‘replication_factor’:2} AND durable_writes = false;
This keyspace is explained in ‘command and short description section’.
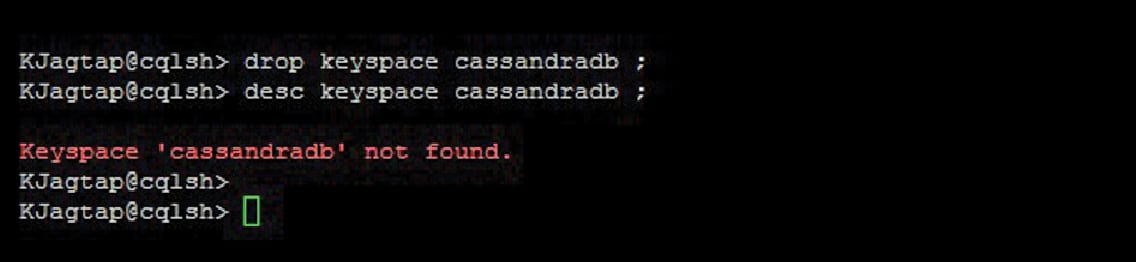
Figure 7 gives an example of the ‘drop keyspace’ command in Cassandra.
Now that you have got all the basic information on this database, you are ready to explore it further on your own. Do try it out; you will find it has a range of useful features.
















