



























































R is a powerful statistical programming language for data science. It consists of powerful packages to deal with Big Data analytics, which is a complex process of examining large and varied data sets in order to reveal hidden, useful, novel and interesting trends and patterns. The R programming language comprises packages and environments for statistical computing with Big Data, making analytics easier.
The R programming language is the right choice for Big Data analytics as it provides capabilities such as access to parallel and distributed machine learning algorithms as well as parallel data and task execution. R programming supports both explicit and implicit parallelism to handle Big Data effortlessly. This language has a rich set of packages for Big Data analytics.
Hadoop is a well known framework for the distributed processing of large data sets. R provides the capabilities of Hadoop with its RHadoop based packages. RHadoop is a collection of five main packages related to distributed processing in R. These sets of packages handle basic connectivity to the Hadoop distributed file system (HDFS) and to the HBASE distributed database. They perform common data manipulation operations, statistical analysis using Hadoop MapReduce functionality and read-write operations on arvo files from the local and HDFS file systems.
ORCH is another vital package of R that deals with Big Data. ORCH is a collection of several packages that consist of interfaces to deal with Hive tables, the local R environment and Oracle database tables. These sets of packages are very efficient for predictive Big Data analytics.
RHIPE is another vital package of R for Big Data analytics. This package provides an integrated environment of R and Hadoop for Big Data processing. 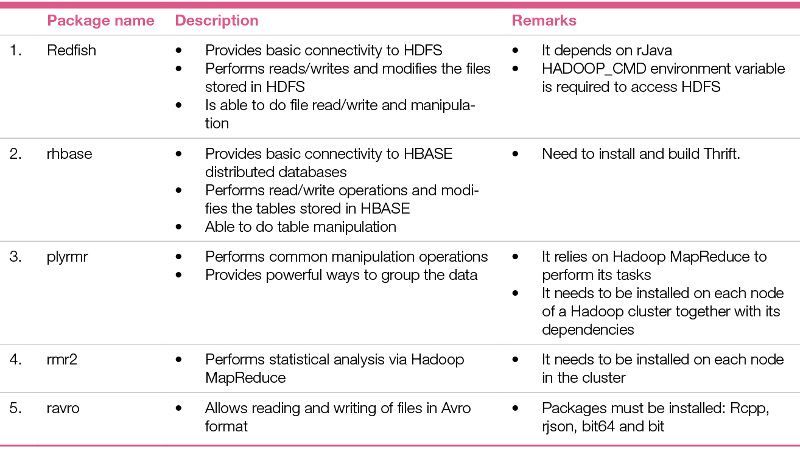 RHadoop package
RHadoop package
RHadoop is a collection of the five packages listed in Table 1.
To install RHadoop, follow the steps given below:
- Download Hortonworks Sandbox for VMware.
- Install VMware Player.
- Open VMware, navigate to Hortonworks Sandbox and import.
- Install RStudio in the sandbox.
- To log into the virtual machine, click into your virtual machine and type <Alt + F5>. Use the default user name: root and password: Hadoop
- Run the following commands:
sudo rpm -Uvh sudo yum -y install git wget R ls/etc/default sudo ln -s /etc/default/hadoop /etc/profile.d/hadoop.sh cat /etc/profile.d/hadoop.sh | sed ‘s/export //g’ > ~/.Renviron wget http://download2.rstudio.org/rstudio-server-0.97.332-x86_64.rpm sudo yum install --nogpgcheck rstudio-server-0.97.332-x86_64.rpm
vii. Install R dependencies.
viii. Download and install rmr2.
The ORCH package
ORCH stands for ‘Oracle R connector for Hadoop’. It consists of several packages that provide access to a Hadoop cluster, to achieve manipulation of HDFS resident data and the execution of MapReduce jobs. It consists of functions that access Apache Hadoop from a local R client. A data frame is the primary object type of ORCH. However, it works with vectors and matrices for the exchange of the data with HDFS.
In ORCH, input files need to satisfy several requirements in order to access HDFS files. These files must be in the comma separated value format, and an underscore as a first character is ignored. Also, all files for the MapReduce job must be stored in one directory as a part of a single logical file. ORCH also provides the preparation and analysis features of the Hive Query language. It accesses any Hive table containing the columns with string and numeric types such as integers, small integers, tiny integers, big integers, float and double.
The RHIPE package
RHIPE is another package that provides an API to use Hadoop with R for Big Data analytics. It is more integrated with plots. RHIPE has several advantages such as:
- Large data visualisation
- Handles large data sets
- Is user friendly
- Applies statistical algorithms
To install RHIPE, follow the steps given below:
- Install Hadoop on clusters.
- Install R as a shared library.
- Install Google Protocol Buffers.
- Set environment variables like Hadoop and R Paths.
- Install the RHIPE package.















