






























































Web scraping, also called Web harvesting or Web data extraction, is essentially the process of extracting copious amounts of data from websites and saving it to a local machine as a file or a database. Web scraping has become an important tool in commerce, consumer research, crime detection and prevention, sentiment mining, and even in politics.
Real-time data extraction and analytics is one of the key domains in a range of applications including sentiment data analytics, criminal data investigation, cyber patrolling, emotion mining, market research and many others. This approach is also known as Web scraping and is widely used in predictive mining and knowledge discovery in real-time, so that the actual data about the specific person or object can be recognised from social media. A similar type of implementation is done by political parties to get citizen reviews about the party, with the aim to increase the probabilities of winning the elections. Such approaches are also used by corporate giants to get feedback about their products from the general public.
Data is extracted in real-time from social media and online portals, from which user reviews are extracted to check the opinion of people about products and services. This action is slanted towards user belief mining or sentiment mining.
Key research dimensions in Web scraping
- Cyber patrol: This entails analysis of messages on social media about particular crimes, or of discussions about particular crimes.
- Cyber parenting: This is the extraction of data from Web portals that engage children or teenagers, so that their emotions and behaviour can be analysed. The cyber parenting approaches that guard children against inappropriate portals can be integrated with these implementations.
- Corporate applications: This involves fetching reviews of products and services from e-commerce portals so that the companies can improve their products as per the requirements and feedback of the users.
Prominent tools for Web scraping and real-time data extraction
There are a number of tools and libraries available for the extraction of real-time data from Web pages. Table 1 mentions the assorted tools, along with the associated URL from where these libraries can be installed.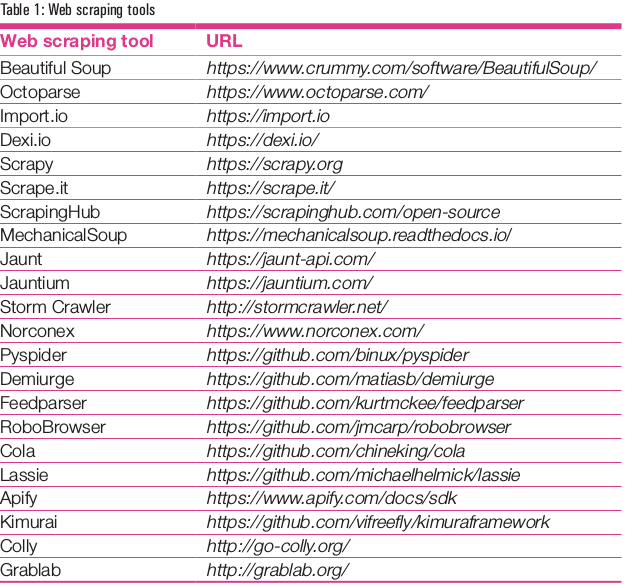
Python based tools for Web scraping
For the last few years, Python has gained much prominence as a high performance programming language for multiple applications. Python is nowadays used in cyber security, digital forensics, Web analytics, deep learning, machine learning, grid computing, parallel computing, cloud applications, Web scraping and many other areas in which a higher degree of performance and accuracy are needed, with minimal error rates.
Python has more than 200,000 packages in its repository, pypi.org, which enable programmers and researchers to work on diversified domains with immense flexibility.
For Web scraping and real-time data extraction, there are more than 10,000 projects and code libraries that can be used by developers.
 The difference between Web parsers and Web scrapers
The difference between Web parsers and Web scrapers
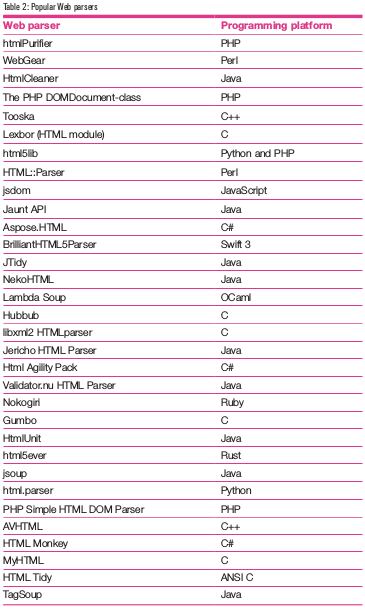
Table 2 lists popular Web parsers for Web applications, which are used to analyse the scraped data. Essentially, a Web scraper is used to extract data from Web applications, while the Web parser is used to break down and analyse the scraped data. So after Web scrapers are used, Web parsers are integrated to analyse the extracted data for knowledge discovery and storage for particular applications.
BeautifulSoup
Python integrates numerous libraries and frameworks for Web scraping and data analytics. BeautifulSoup (URL: https://www.crummy.com/software/BeautifulSoup) is one such library that is widely used for data extraction and logging of outcomes from multiple real-time channels.
The key benefits of BeautifulSoup include the following:
- Compatible with Python 2 as well as Python 3
- Fast and high-performance library
- Dynamic parsing and extraction of Web pages
- Deep searching, navigation and parsing of content on Web pages
- Real-time extraction of data without delay
- Dynamic storage of Web data using HTTP requests to the Web URL
- Data extraction and transformation into multiple formats including JSON, XML, CSV, TXT, XLS, XLSX, and many others
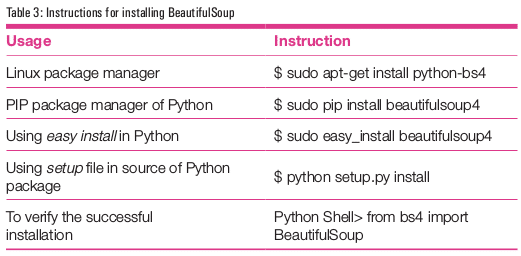
Table 3 presents the many instructions to install BeautifulSoup.
 BeautifulSoup is one of the very powerful libraries of Python that are used to extract real-time data for market research, predictive analytics, and knowledge discovery, including user sentiments about products and their features, as well as reviews on new consumer products.
BeautifulSoup is one of the very powerful libraries of Python that are used to extract real-time data for market research, predictive analytics, and knowledge discovery, including user sentiments about products and their features, as well as reviews on new consumer products.
Scraping messages and user timelines from Twitter and other social media
We often need to analyse the user feedback and reviews from social media about particular products or services. Generally, people share their views and feedback about products on Twitter, Facebook, Instagram and other similar social platforms. Web scraping can be done to extract these messages from timelines so that the users’ sentiments can be evaluated in order to improve services or product features.
Scraping images and timelines on Instagram
Instagram is a very popular platform for sharing multimedia content using a mobile based platform. The content that users broadcast on Instagram can be fetched using the BeautifulSoup library. One of the key applications of this implementation can be to evaluate the current status of a particular user so that his or her behaviour and interests can be identified.
The following code snippet can be used to extract images and content associated with the specific hashtag of Instagram. These can be beneficial for researchers working on specific news coverage linked with the particular hashtag. In addition, crime investigation authorities can extract all the messages or files linked with the specific hashtag from the timeline of users.
html = urllib.request.urlopen(url, context=self.ctx).read() soup = BeautifulSoup(html, ‘html.parser’) myscript = soup.find(‘myscript’, text=lambda t: \ t.startswith(‘window._sharedData’)) page_json = myscript.text.split(‘ = ‘, 1)[1].rstrip(‘;’) data = json.loads(page_json) for instapost in data[‘entry_data’][‘TagPage’][0][‘graphql’ ][‘ihashtag’][‘edge_ihashtag_to_media’][‘edges’]: image_src = instapost[‘node’][‘thumbnail_resources’][1][‘src’] myhs = open(ihashtag + ‘.txt’, ‘a’) myhs.write(image_src + ‘\n’) myhs.close() def main(self): self.ctx = ssl.create_default_context() self.ctx.check_hostname = False self.ctx.verify_mode = ssl.CERT_NONE with open(‘ihashtagdata.txt’) as f: self.content = f.readlines() self.content = [x.strip() for x in self.content] for ihashtag in self.content: self.getlinks(ihashtag, ‘https://www.instagram.com/explore/tags/’+ ihashtag + ‘/’)
In addition, Twitter also provides a specific library called Tweepy for Web scraping, with the focus on R&D. Using this package, all the tweets can be extracted from social media about a particular search keyword mentioned in the code.
The following code snippet can extract all the tweets about specific search keywords from Twitter using the Tweepy package.
twitterconsumer_key = ************************* twitterconsumer_secret = ************************* twitteraccess_token = *************************-************************* twitteraccess_secret = ************************* class TweetListener(StreamListener): def on_currentdata(self, currentdata): print currentdata return True def on_error(self, status): print status oauth = OAuthHandler(twitterconsumer_key, twitterconsumer_secret) oauth.set_access_token(twitteraccess_token, twitteraccess_secret) mystream = Stream(auth, TweetListener()) mystream.filter(track=[‘Search Keywords’])
These types of scripts can be used to identify discussions around a particular keyword on social media. The police investigation teams and cyber forensic departments can analyse the tweets and messages which are related to a particular crime, so that deeper analysis of the persons involved can be done. These tweets are extracted in JavaScript Object Notation (JSON) format, which is further transformed to Comma Separated Value (CSV) or any other format, so that deep evaluation can be done.
Scope for R&D
Real-time Web data extraction is required for many applications including crime data analysis, market research, citizen feedback, consumer reviews, etc. Market research experts and practitioners can extract data about particular themes or products from multiple portals for user sentiment/behavioural analysis. Many corporate organisations collect such data sets from online portals so that they can improve their services and product features.

















{kind=link}