






























































Natural language processing (NLP) is the technology that enables computers to recognise human language, precisely. It is the way to program computers to process and analyse large amounts of natural language data which could be text, content or speech. NLP is a component of artificial intelligence.
Hierarchically, NLP is considered as a subset of machine learning (ML), while NLP and ML both fall under the larger category of artificial intelligence (AI).
The primary objective of NLP is to combine artificial intelligence (AI) and computational linguistics so that computers and humans can talk to each other, seamlessly. To communicate with humans, a program must apprehend syntax (grammar), semantics (phrase meaning), morphology (tense) and pragmatics (conversation). NLP enables computer programs to comprehend unstructured content by utilising AI and ML to make derivations and give context to language, similar to how human brains function.
Common everyday applications of NLP
The application of NLP was less impressive earlier. But today, it has advanced considerably to yield good outcomes for some common NLP tasks, such as named entity recognition (NER), parts of speech (PoS) tagging and sentiment analysis – all of which leverage neural network models to outperform traditional approaches. Today, NLP is everywhere even if we don’t realise it, covering everything from search and online translation to spam filters and spell checking. In this post, we look at the four areas where natural language processing is becoming a reality.
Machine translation: In the last few decades, the number of non-English speaking Internet users has drastically increased all over the world, which means a big chunk of the data feed to the Internet is non-English. To stay competitive, companies in international markets, especially in new and growing markets, have jumped to translating their texts into many more languages. Business houses have started introducing new applications and improved machine learning NLP models to automate translations.
Automatic summarisation: Information overload is a real problem when we need to access a specific, important piece of information from a huge knowledge base. Automatic summarisation is especially relevant when used to provide an overview of a news item or a set of blog posts, while avoiding redundancy from multiple sources and maximising the diversity of content obtained.
Sentiment analysis: Sentiment analysis is extremely useful in social media monitoring, as it allows us to gain an overview of the wider public opinion on certain topics. Retailers use NLP applications such as sentiment analysis to identify opinions and sentiments online, and factor these learnings into how their merchandising is designed and displayed in order to acquire customers. This technique is advantageous in the market research and customer services fields.
Speech recognition: Just a few years back, we used to type keywords into the Google search bar to get some results. In the last few years, major IT companies like Google, Apple and Amazon have already shifted to the use of NLP for voice-based search, providing customers a seamless experience. Many industries have seen massive growth in the use of natural language processing tools to enable effective speech recognition processes and enhance productivity.
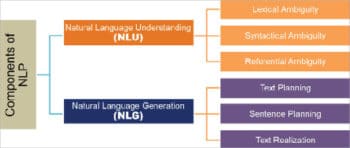
Components of NLP
NLP has two basic components:
- Natural language understanding (NLU)
- Natural language generation (NLG)
Natural language understanding
NLU is naturally harder than NLG tasks. So let’s understand the challenges a machine faces while trying to understand language. There is a lot of ambiguity while learning or trying to interpret a language. For example, consider the following sentence:
He is looking for a match.
Here, what do you understand by ‘match’? It could mean a life partner or a cricket/football match.
Lexical ambiguity can occur when a word has more than one meaning and the sentence that it is used in can be interpreted differently, depending on its correct context. Lexical ambiguity can be resolved to some extent by using parts-of-speech tagging techniques. Let us look at another example:
The chicken is ready to eat.
Is the chicken ready to eat its food or is the chicken dish ready for someone else to eat? You never know.
Syntactical ambiguity means when there is more than one meaning to a sequence of words.
It is also termed a grammatical ambiguity. Here is another example:
Feluda met Topse and LalMohan babu. They went to a restaurant.
In this case, does ‘they’ refer to Topse and LalMohan babu or to all three of them?
Referential ambiguity happens when a text mentions an entity (something/someone) and then refers to it again, possibly in a different sentence, using another word. This is the common case of pronouns causing ambiguity, when it is not clear which of the many nouns in a sentence is being referred to.
Natural language generation
This is the process of producing meaningful phrases and sentences in the form of natural language from some internal representation.
It involves:
Text planning, which includes retrieving the relevant content from the knowledge base.
Sentence planning, which includes choosing the required words, forming meaningful phrases and setting the tone of the sentence.
Text realisation, which is mapping the sentence plan into the sentence structure.
Five common NLP terms
Tokenisation: The process of breaking down a paragraph of text into smaller chunks such as words or sentences is called tokenisation. A token is a single entity that is a building block for a sentence or a paragraph. This allows the computer to deal with words in a more manageable form.
Using Python NLTK (Natural Language Tool Kit), we can easily perform tokenisation as shown below.
from nltk.tokenize import sent_tokenize text=”Hello friends!. Good Morning! Today we will learn Natural Language Processing. It is very interesting” tokenized_text=sent_tokenize(text) print(tokenized_text) OUTPUT [‘Hello friends!.’, ‘Good Morning!’, ‘Today we will learn Natural Language Processing.’, ‘It is very interesting’] from nltk.tokenize import word_tokenize tokenized_word=word_tokenize(text) print(tokenized_word) OUTPUT [‘Hello’, ‘friends’, ‘!’, ‘.’, ‘Good’, ‘Morning’, ‘!’, ‘Today’, ‘we’, ‘will’, ‘learn’, ‘Natural’, ‘Language’, ‘Processing’, ‘.’, ‘It’, ‘is’, ‘very’, ‘interesting’]
Stopwords removal: Stopwords are considered as noise in the text. A text may contain stopwords such as is, am, are, this, a, an, the, etc. We don’t want these words to take up space in our database, or take up valuable processing time. They can be removed easily by storing a list of words that you may consider to be stopwords. NLTK has a list of stopwords stored in 16 different languages. In the following example, we can see that is and my have been removed from the sentence.
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize text = “India is my country” text_tokens = word_tokenize(text) tokens_without_sw = [word for word in text_tokens if not word in stopwords.words()] print(tokens_without_sw) OUTPUT [‘India’, ‘country’]
Stemming and lemmatisation: Lemmatisation is the process of converting a word to its base form. The difference between stemming and lemmatisation is that the latter considers the context and converts the word to its meaningful base form, whereas stemming just removes the last few characters, often leading to incorrect meanings and spelling errors.
Based on the applicability, you can choose any of the following lemmatisers:
- Wordnet Lemmatiser
- Spacy Lemmatiser
- TextBlob
- CLiPS Pattern
- Stanford CoreNLP
- Gensim Lemmatiser
- TreeTagger
However, stopword removal or stemming/lemmatisation are not required in case text mining uses complex models like neural networks. For relatively simpler model input, generally, stopwords removal or stemming/lemmatisation helps to reduce the input text size. Here is one short example using Wordnet Lemmatiser:
nltk.download(‘wordnet’)
import nltk
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
text = “Playing Plays Played “
tokenization = nltk.word_tokenize(text)
for w in tokenization:
print(“Lemma for {} is {}”.format(w, wordnet_lemmatizer.lemmatize(w)))
OUTPUT
Lemma for Playing is Playing
Lemma for Plays is Plays
Lemma for Played is Played
Parts of speech tagging: In your childhood, you would have heard the phrase ‘parts of speech’ (PoS). No doubt, it took us a lot of time to understand what adjectives and adverbs actually were, what was the difference between them, and so on. PoS tagging algorithms can predict the PoS of the given word with a higher degree of precision. You can get the PoS of individual words as a tuple.
In the following example of code, for the text content in a document, we can use the PoS to easily get only the proper nouns. Let’s say we don’t want to miss out on any country name from the text, we can do this very easily, too.
import nltk from nltk.tokenize import PunktSentenceTokenizer document = “””Domestic cricket seasons in Australia, New Zealand, South Africa, India, Pakistan, Sri Lanka,Bangladesh, Zimbabwe and the West Indies may therefore span two calendar years, A cricket season in England is described as a single year. e.g. “2009”. An international ODI series or tournament may be for a much shorter duration, and Cricinfo treats this issue by stating any series or matches. In the record tables, a two-year span generally indicates that the record was set within a domestic season in one of the above named countries.””” sentences = nltk.sent_tokenize(document) data = [] for sent in sentences: data = data + nltk.pos_tag(nltk.word_tokenize(sent)) for word in data: if ‘NNP’ in word[1]: print(word) OUTPUT (‘Australia’, ‘NNP’) (‘New’, ‘NNP’) (‘Zealand’, ‘NNP’) (‘South’, ‘NNP’) … … (‘England’, ‘NNP’) (‘ODI’, ‘NNP’) (‘Cricinfo’, ‘NNP’)
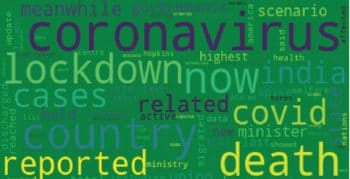
Word cloud: ‘A picture is worth a thousand words’ is a popular proverb. Sometimes, it becomes cumbersome to read and conclude what a large body of text means. Instead, if you want an impressive visualisation format to highlight important textual data points, using a word cloud can make dull data sizzle and immediately convey crucial information.
A word cloud is a data visualisation technique used for representing text data, in which the size of each word indicates its frequency or importance. Significant textual data points can be highlighted using a word cloud. These are widely used for analysing data from social network websites. Word clouds are not just for researchers; marketers use them to convey customer sentiments.
Think about a huge body of text (like an extract from a news article in The Financial Express dated May 30, 2020) that’s shown below. We need to know what it is about, so we create a word cloud of it using the code below. In a second, it is clear that the text is about the spread of coronavirus and the lockdown.
“The highest spike of 7,466 new COVID-19 cases and 175 deaths in the last 24 hours has been reported in the country. The total number of corona virus infected in the country now stands at 165,799 including 89,987 active cases, 71,105 cured/discharged/migrated. …
…Meanwhile, a sharp rise in coronavirus has been reported in Mumbai, Maharashtra, Delhi, West Bengal and Ahmedabad. Haryana has ordered sealing of its borders with the national capital.”
import matplotlib.pyplot as pPlot from wordcloud import WordCloud, STOPWORDS import numpy as npy from PIL import Image text = “””Highest spike of 7,466 new COVID-19 cases and 175 deaths in the last 24 hours has been reported in the country. Total number of coronavirus infected in the country now stands at 1,65,799 including 89,987 active cases, 71,105 cured/discharged/migrated. Meanwhile, a sharp rise in coronavirus has been reported in Mumbai, Maharashtra, Delhi, West Bengal, Ahmedabad. Haryana has ordered sealing of its borders with the national capital.””” cloud = WordCloud(background_color = “green”, max_words = 100, stopwords = set(STOPWORDS)) cloud.generate(text.lower()) cloud.to_file(“Fig3.png”)
OUTPUT
The future of NLP
NLP provides a wide range of tools and techniques that can be applied to all areas of life. By learning them and using them in our day to day dealings, the quality of life can greatly improve. Companies from high tech startups to multinationals see the use of NLP as a key competitive advantage in an increasingly competitive and technology-driven market.
AI virtual assistants can be made smarter, thereby extending NLP experiences. An AI medical assistant will understand conversations using NLU models enabled with medical terminology. Trained in medical terminology and data, it would be able to listen and interpret conversations between a doctor and a patient to record and subsequently recap the conversation as notes. The frequent exposure of healthcare staff to dangerously infected patients can be avoided.
Today we see the novel coronavirus spreading across the globe, threatening the lives of healthcare staff. Using NLP trained virtual assistants, we can reduce these risks and control the pandemic. Treatment becomes convenient and faster. Lower use of medical kits (like masks, gloves, etc) will in turn be cost-effective and environment-friendly.
As the NLP technology evolves, computer systems will increase their current capabilities from processing to figuring out human language in a holistic way. Until now, NLP has only been able to infer a limited variety of human emotions like joy or anger. Eventually, it will be programmed to recognise more complicated aspects of human language, which includes humour, parody, sarcasm, satire, irony and cynicism
Natural language processing is set to be integrated in almost every aspect of life, so the sky is the limit. The future is going to see some massive changes as the technology becomes more mainstream and advanced. Another major consequence of artificial intelligence and natural language processing will be the invasion of robots in the workplace; so industries everywhere have to start preparing for this.
Some of us remember ‘Wall-E’, the well-known sci-fi film that was released in 2008 in which a solitary trash compactor robot spends his days changing garbage into string blocks and building structures with them. One day, a giant spaceship arrives and drops a new robot named Eve on Earth. Eve has been despatched to our planet to determine whether life exists here! Eve focuses on finding the existence of life, ignoring Wall-E entirely as he is a non-living thing. However, Wall-E rescues Eve from a dust storm and provides her with shelter, where he shows her the last living plant. By this stage in the movie, Wall-E has developed a personality, is lonely, and falls in love with Eve.
Could this become a reality in the near future? Are we heading in the direction of giving birth to fully conscious machines?
With Cortana, Alexa and Siri, the next-gen NLP journey has begun.



















{kind=link}