






























































This article explains how to use machine learning and deep learning models on handheld devices like mobile phones and Raspberry Pi. It is intended for research scholars, faculty members and students interested in using these models on handheld devices employing TensorFlow Lite.
Mobile devices are a huge part of our lives. Empowering mobile devices with machine learning (ML) models helps in building more creative and real-time applications. TensorFlow Lite is a framework developed by Google that is open source, product-ready and cross-platform. It is used to build and train ML and deep learning (DL) models on mobiles, as well as on embedded and IoT devices. This specially designed framework converts the pre-trained model, which resides within TensorFlow, to a specific format that is suitable for handheld devices by considering the speed and storage optimisation need. This format works well for mobile devices with Android or iOS, or Linux based embedded devices like microcontrollers or Raspberry Pi. Deployment of pre-trained models on mobile devices makes it convenient to use them at a certain time.
Features of ML/DL models used in mobile devices
1. Low latency: Deploying deep learning models on mobile devices makes them convenient to use irrespective of network connectivity, as the deployed model with a suitable interface eliminates a round trip to the server and helps access the functionality faster.
2. Lightweight: Mobile devices have limited memory and computation power, so DL models deployed on the mobile device have smaller binary size and are lightweight.
3. Safety: The interface made for the deployed model on the mobile device is accessible within the device only. As it shares no data outside the device or network, there is no data leak issue.
4. Limited power consumption: Connection to an external network demands maximum power on the mobile device. However, a model deployed on a handheld device does not demand a network connection; hence, the power consumed is lower.
5. Pre-trained model: A pre-trained model can be trained on high computing infrastructure, i.e., a GPU or on cloud infrastructure, for several tasks like object detection, image classification, natural language processing, etc. This pre-trained model can be converted and deployed to mobile devices across different platforms.
Figure 1 illustrates the workflow of TensorFlow Lite.
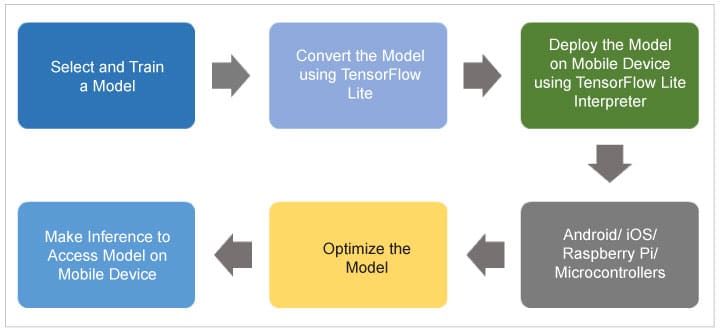
Model selection and training
Model selection and training is a crucial task for solving classification problems. There are several options available that can be used for model selection and training:
- Build and train a custom model using an application-specific data set.
- Apply a pre-trained model like ResNet, MobileNet, InceptionNet, NASNetLarge that is already trained on the ImageNet data set.
- Train the model using transfer learning for the desired classification problem.
Model conversion using TensorFlow Lite
A trained model can be converted to the TensorFlow Lite version. TensorFlow Lite is a special model format that is lightweight, accurate and suitable for mobile and embedded devices. Figure 2 depicts the process of conversion to TensorFlow Lite.
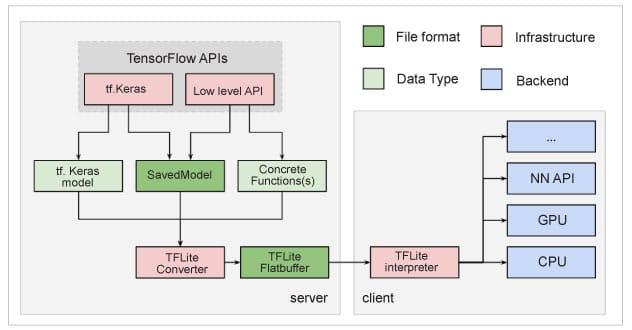
Using the TensorFlow converter, the TensorFlow model is converted to a flat buffer file that is called a .tflite file, which is deployed to mobile or embedded devices.
The trained model after the training process is required to be saved. The saved model is an architecture that stores different information in a single file. The information is related to weights, biases and training configuration. Sharing and deploying the model becomes easy with the saved model. The following code is used to convert the saved model to TensorFlow Lite:
#save the model after compiling model.save(‘test_keras_model.h5’) keras_model= tf.keras.models.load_model(‘ test_keras_model.h5’) #conver the tf.keras model to TensorFlow Lite model converter = tf.lite.TFLiteConverter.from_keras_model(keras_model) tflite_model = converter.convert()
Model optimisation
An optimised model demands less space and resources on handhelds like mobile and embedded devices. Therefore, TensorFlow Lite uses two special approaches — quantization and weight pruning — to achieve model optimisation. Quantization makes the model lightweight. It refers to the process of reducing the precision of the numbers that are used to present the different parameters of the TensorFlow model. Weight pruning is the process of trimming those parameters in the model that have less impact on the overall model performance.
Making an inference to access a model on a mobile device
As mentioned above, a TensorFlow Lite model can be deployed on many types of handheld devices. However, for that, the following steps need to be taken to create a mobile interface to access the model:
- With the model, initialise the load interpreter.
- Assign the tensors, and obtain input and output tensors.
- Read and pre-process the image by loading it into a tensor.
- Use and invoke an interpreter that makes the inference on the input tensor.
- Generate the result for the image by mapping the result from the inference.

















{kind=link}