

The article gives an overview of two popular AI and ML tools — TensorFlow and Tesseract OCR — which have been developed by Google AI Labs for the open source community.
Google AI Labs provides many services for AI and ML. These include the use of free platforms for development activities, releasing code to the open source community, and support for AI/ML related research activities.
TensorFlow is a Google AI project and one of the most popular open source machine learning frameworks. It can be used to build and train ML models like Keras API. It builds neural networks, and enables machine translation and video processing using ML models.
Tesseract OCR is another popular open source character recognition and OCR library written in Python and C++. It was originally developed as a commercial OCR package by HP Laboratories in late 1990 to run on DOS command-line mode and later to work on the Windows OS by enhancing features using C++. In 2005, it was released by HP Laboratories as an open source framework available for community development in GitHub, and was sponsored by the Google AI project for this. It is still available under Apache License 2.0 for open source applications.
TensorFlow and its features
TensorFlow is built on neural network models and supports many popular algorithms like clustering, decision tree, neural network evaluation, linear regression, and Naïve Bayes classifier. It is very popular for large volume machine learning activities and supports both CPU and GPU based processing, which can help to optimise operational costs in building machine learning solutions.
There are many frameworks that support building a machine learning model, and their flexibility of usage varies. For example, Scikit-Learn has many inbuilt libraries for machine learning algorithms and implementation, whereas TensorFlow is more flexible as it allows development and implementation of custom ML algorithms that can integrate with other TensorFlow libraries easily.
There is now a more sophisticated solution available for such high workloads using Google’s marquee compute engine called Cloud Tensor Processing Unit (TPU), which is specifically designed for the TensorFlow kind of machine learning model building and services. It helps to train ML models and use them for real-time business solutions like data analytics and forecasting.
TPU based computing machines are specially designed for ML services like TensorFlow or PyTorch based solutions. They don’t use CPU or RAM, and have scaler unit, vector processing unit (VPU) and matrix multiplication unit (MXU) for algorithmic processing and calculation activities. They also have high-bandwidth memory (HBM) in place of RAM for memory operations.
It can be seen in Figure 1 that TensorFlow has multiple components, including core components, interfacing components and add-on libraries. Let’s understand these better.
TF servable: These are computational units used for asynchronous mode of operation, streaming results and experimental APIs to perform machine learning operations.
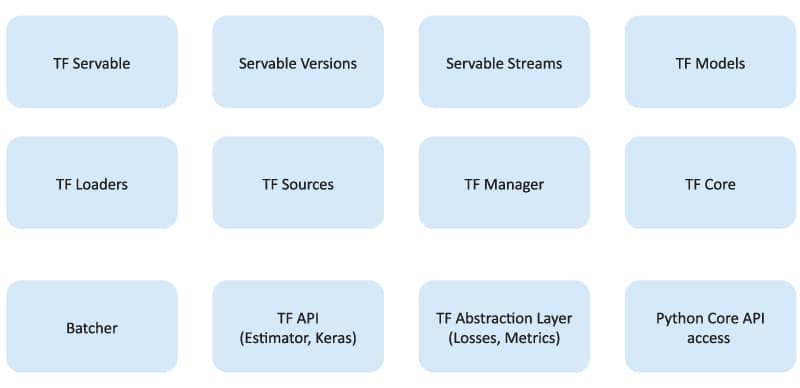
Servable versions: These are used to maintain one more version of servable units. A TensorFlow processing application can use one or more versions for various computational units, each serving different algorithms.
Servable streams: This is an artifactory that has sequentially ordered versions of servables. During bootstrap of TensorFlow loading, servable version is used to look up from this artifactory for experimental evaluation.
TF models: For a given machine learning task, a TensorFlow model will be created by looking up a specific servable unit with a suitable version. This is further used for evaluation and processing activities.
TF loaders: This is the bootstrapping component or API, which is mainly used to handle the life cycle of servables. Using its standardised loader API, loading and unloading (bootstrap and offload) can be done.
TF sources: This is a plugin module and used to find servable from servable stream, provide servable through TF models, and provide servable when requested from client.
TF manager: This is the controlling unit of the TensorFlow application. It is used to monitor the runtime performance and tune CPU/TPU/GPU configuration to cater to request handling, and manage life cycle of servable (startup, processing, shutdown) as well as other logging and auditing activities.
TF core: This handles servable and loader together for runtime execution, and also handles life cycle of metrics to collect the usage statistics.
Batcher: This is the processing unit of the TensorFlow application, which accelerates TPU/GPU for better performance and optimised cost. It is a procedure or master plane to handle multiple requests at a time and create machine learning tasks through TF loaders.
TF API: This provides peripheral functionalities like Estimator and Keras API library usage to support machine learning activities in OCR and image based character recognition. It is available as an out-of-the-box facility, which is easy to be hooked from other applications using an API interface.
TF abstraction layer: These are components to build neural network models that are developed by training the machine learning model. They are used for classification through loss functions, metrics for evaluation and benchmarking.
Python Core API access: This provides language control to use core Python functions for external applications like Java, GoLang and C/C++ to invoke TensorFlow functionalities.
TensorFlow usage
TensorFlow is a great tool with countless benefits. The following are some of its use cases.
a. Voice/sound recognition: Deep learning has contributed a lot to voice-cum-sound recognition. Neural networks with proper input data feed can understand audio signals. Voice recognition is mostly used in the Internet of Things, automotive, security and UX/UI (user experience/user interface).There are also voice-search and voice-activated assistants of smartphones such as Apple’s Siri.
b. Text based applications: Text based applications such as sentiment analysis, threat detection and fraud detection are common applications backed by TensorFlow in real time. For example, Google Translate supports over 100 languages. Another use case of deep learning is text summarization. Google found out that summarization can be done using a deep-learning technique called sequence-to-sequence (S2S) learning. Indeed, this S2S deep learning technique can be used to produce headlines for news articles. SmartReply is another Google use case, which automatically generates e-mail responses.
c. Image recognition: Image recognition is used for face recognition, image search, motion detection, machine vision, and photo clustering. It can also be used in the automotive, aviation, and healthcare industries. The advantage of using TensorFlow for object recognition algorithms is that it helps to classify and identify arbitrary objects within larger images. This is used in engineering applications to identify shapes for modelling purposes (or 3D space reconstruction from 2D images), and by Facebook for photo tagging (Facebook’s Deep Face). As an example, TensorFlow is used in deep learning for analysing thousands of photos of dogs to help identify one.
d. Video detection: Deep learning algorithms, these days, are also used for video detection like motion detection, real-time thread detection in gaming, for security at airports, and so on. For example, NASA is developing a deep learning system for orbit classification and object clustering of asteroids to classify and predict NEOs (near earth objects).
TensorFlow applications
The following are various TensorFlow applications developed by the open source community and used in diverse ways.
a. DeepSpeech: DeepSpeech is a voice-to-text command and library, making it useful for those who need to transform voice input into text and developers who want to provide voice input for their applications. It is composed of two main subsystems — an acoustic model and a decoder. The acoustic model is a deep neural network that receives audio features as inputs, and outputs character probabilities. The decoder uses a beam search algorithm to transform the character probabilities into textual transcripts that are then returned by the system.
b. RankBrain: RankBrain is a component of Google’s core algorithm based on TensorFlow, which uses machine learning to determine the most relevant results to search engine queries. Before RankBrain, Google utilised its basic algorithm to determine which results to show for a given query. Post-RankBrain, it is believed that the query now goes through an interpretation model that can apply possible factors like the location of the searcher, personalisation, and the words of the query to determine the searcher’s true intent.
c. Inception v3: Inception v3 is a pretrained convolutional neural network that is 48 layers deep, which is a version of the network already trained on more than a million images from the ImageNet database. This pretrained network can classify images into 1000 object categories, such as keyboard, mouse, pencil, and many animals. As a result, the network has learned rich feature representations for a wide range of images. The network has an image input size of 299-by-299. The model extracts general features from input images in the first part and classifies them based on those features in the second part.
In addition, TensorFlow can also be used with containerisation tools such as Docker. For instance, it can be used to deploy a sentiment analysis model that uses character level ConvNet networks for text classification. TensorRec is another cool recommendation engine framework in TensorFlow. It has an easy API for training and prediction, and resembles common machine learning tools in Python.
Tesseract OCR and its execution process
Tesseract is a neural network based OCR engine. It supports more than 100 languages to be recognised from images like png, jpg and tiff, and generates output in various formats like HTML, pdf and plain text, to name a few. It is a library that can be used with other applications, and can also be used as a standalone command-line tool with no facility as built-in GUI.
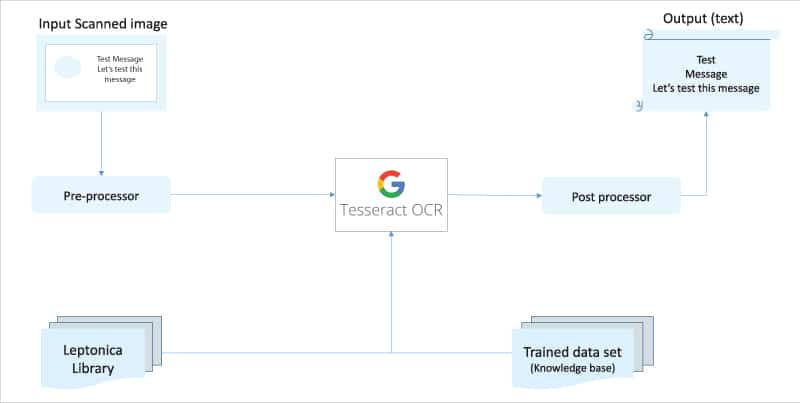
There are many third-party tools available to be used as Tesseract integrated GUI applications. Tesseract OCR uses third party Leptonica library under BSD-2 clause license to support image recognition in zlib, png and tiff formats.
Tesseract OCR takes an input image from a scanned source and gives it for pre-processing, where it is cleansed (from distortion) to make it as clear as possible using possible pixelation and anti-pixelation methods, resizing for better readability and interpretation by the algorithm, and rotation (if needed) for proper character interpretation.
Then the OCR engine uses suitable algorithms including Leptonica library to start processing the image by splitting it into logical lines of text. Each line of text is then split into words using space as a breaker, and then words are split into characters using logical shapes. This is then used to interpret the character, word and sentence. The final interpreted group of characters is given to the post processor, which will form the words and sentence as per split size of the source image.
During the entire processing activity, Tesseract OCR engine uses its trained data set which keeps on building its neural network whenever reprocessing and processing corrections are carried out. More and more usage and corrections help to build better accuracy.
Tesseract 4.0, the latest version, has improved text line recognition using line separator interpretation from line to line gaps. In general, Tesseract uses adaptive binarization for character recognition from binary format of images; for images with single character, it uses convolutional neural networks (CNN).
Tesseract was developed using C++ and if you want to integrate it with Python applications, you can use Pytesseract (Python Tesseract) which is a Python based wrapper for the Tesseract OCR library. Tesseract GitHub has an in-built facility for language detection when it gets a scanned image to load the appropriate language training set for processing. The training set for different languages is available in GitHub in the Data-Files folder as a traindata file and placed in $TESSDATA_PREFIX folder in the Tesseract installed location.
This finishes with our overview of two powerful AI tools — TensorFlow and Tesseract OCR.



{kind=link}