






























































This multi-part series of articles will take you through the various components of DevOps. It will introduce you to network function virtualization and its integration with the DevOps pipeline. This second article in the series focuses on containerization.
Virtualization is today the backbone of many data centers around the globe, providing resources for modern-day applications. Containerization is a sort of virtualization, where multiple user spaces can be created over the top of the existing kernel. We can define a container as a plug-and-play box, which contains all the dependencies required for the application or service inside of it to run.
Containers are well known for less overhead and are more performant compared to hypervisor-based virtualization. When VMs are compared with containers, Docker containers have outperformed KVMs (kernel-based virtual machines) in overhead for CPU, memory performance, and I/O-intensive workload. Containers are used to ship software, applications, or services. For example, if you want to set up your web application on a web server, you can do it via a portable tool like a container. You put all the required dependencies and the application artifact in the container of a web server and run it for your application to be available to make any request. Figure 1 depicts the hypervisor and container architecture.
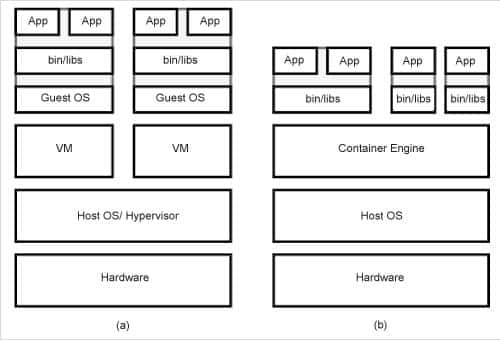
Architecture
Advances in the Linux kernel made OS virtualization possible. Now the kernel provides mechanisms such as name spaces and control groups. With these advances, one can isolate processes on the host machine. This is supported via the Linux container (LXC) project.
Let us discuss in brief the internals of the container. A set of processes is called a group. For each group, we can set process attributes and a proportionate share of system resources like CPU, memory, disk space, and network interface. The cgroup feature takes care of the allocation and control of system resources for a group. The cgroup has a resource controller that monitors as well as accounts for resource usage. It is used by many of its subsystems such as debug, devices, freezer, perf-event, CPU, cpuset, cpuacct, memory, hugetlb, blkio, net-cls, and systemd. These subsystems can be viewed in the /sys/fs/cgroup directory. The process ID inside the group is global; therefore, it is NOT isolated from the host. However, the requirement here is to isolate each group.
The name space feature helps the group to isolate its process IDs from the host system. The isolation features are implemented in the mounted file systems, UTS, IPC, PID, network, and user. This way, each group is created as an isolated environment for a user with the help of cgroup and name space.
The container runs as a user process inside the server and helps make every operation possible, as is done by a user process such as creation, deletion, monitoring, performance tuning, etc. At the same time, it is isolated from other system processes on the server. Therefore, each container works like a standalone system. The container can have its own process IDs, mounted file systems, system resources, network, and logs. A container can be executed without adding any overhead to the hypervisor, and launching a container is miraculously fast.
Figure 2 depicts how various layers are added to the top of the base image of the container, where the container is connected directly to the Linux kernel via the daemon process running over the host operating system. The top layer of the image can always be topped with another layer, where the user can add self-defined functionalities.
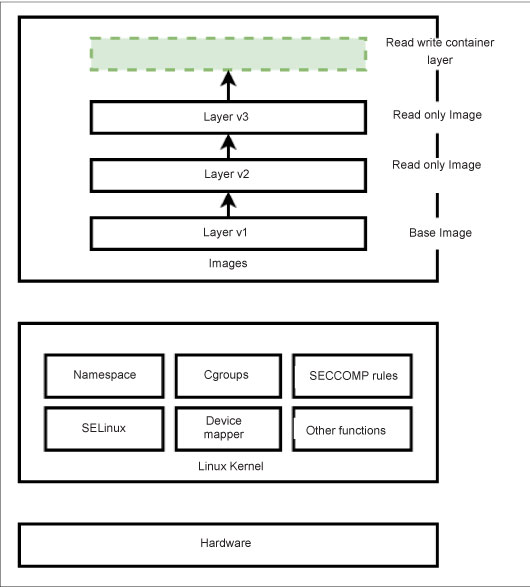
Container engine
There’s one more aspect to the container — the container engine, which accepts users’ requests related to the containers. These requests can vary from pulling a container image to running that image. When the container is started, the container engine unfolds all the required files and metadata, and hands it to the Linux kernel for further processing. The container engine makes an API call to the host machine’s Linux kernel to start the container process. The latter is just another Linux process running for the host machine. The container image is there before the inspection of the container; this image is turned into the container upon its execution by the container engine. OCI (Open Container Initiative) is a Linux Foundation project which is equipped to design open standards for operating system-level virtualizations; this includes containers. There are several container engines, and some of the popular names are Docker, OpenVZ, CoreOS, and runc.
Networking
Networking within containers has always been an integral part of virtualization. This is one of the reasons why containers were so openly accepted by the software development community. A similar service is provided by Docker. With Docker networking, you can connect either multiple containers to one another or non-Docker workloads to Docker container workloads. Docker manipulates iptables rules on Linux to provide container network isolation.
Network drivers in Docker are responsible for managing the network and providing core network functionalities. There are six network drivers associated with Docker: none, bridge, host, ipvlan, macvlan, and overlay.
None: This disables all the networking within the Docker container.
Bridge: This is the default networking driver provided by Docker to the running containers. With bridged networking, the Docker container can communicate with other running containers connected to the same software bridge.
Host: Containers using host network drivers can use the Docker host networking directly. With this driver, the isolation between the container and the Docker host is removed.
Ipvlan: With Ipvlan, the user gets total control over both IPv4 and IPv6 addressing. It removes the software bridge that traditionally resided between the Docker host NIC and the container interface; instead, the container interface is directly attached to the Docker host interface.
Macvlan: This allows users to set up a MAC address in a container. The container can then appear as a physical device over the network.
Overlay: This allows multiple Docker daemons running over separate host machines to be connected. With the overlay network, users can allow communication between swarm service and standalone containers, or between standalone containers running over different Docker daemons.
Container runtime
Container runtime is another piece of software responsible for running and managing the component that is required to run containers. It can be categorised into two sets — low-level container runtimes and high-level container runtimes.
Low-level container runtime is responsible for just running the containers. This is done by setting up name spaces and cgroups for containers, and there isn’t a wide spectrum of features.
High-level container runtime supports more high-level features such as image management, sharing, unpacking, and web APIs or remote procedure calls.
Container runtime also supports the following:
- The image registry is set in the configuration file. From this, the provided registry images are pulled if they are not available locally.
- Images are created as an overlay of various layers. Each layer adds value to the previous existent layer, and together they create a merged file system.
- A container mount point is prepared.
- Metadata is retrieved and applied from the container image. Various settings are configured such as CMD, and ENTRYPOINT.
- The kernel is notified to allocate isolation for processes, networking, and file system to the applicable container (name spaces).
- The kernel is also notified to keep a check on various resource limits like CPU or memory limits to this container (cgroups).
- A system call (syscall) is passed to the kernel to start the container.
- SELinux/AppArmor is set up.
Orchestration
It’s easy to manage, say, 10 containers that are running the microservices of an application. You can manually handle the life cycle of these containers. But the task becomes complicated and tedious when we talk about thousands or even hundreds of containers. The manual process of deploying and managing these containers becomes cumbersome. To handle this life cycle of containers and to automate them we use orchestration.
Container orchestration’s primary role is to handle containerized applications’ deployment, management, scaling, networking, and availability. With container orchestration, enterprises can handle hundreds or even thousands of containers with ease. It can help in managing and automating tasks such as:
- Deployment and provisioning of the network and storage resources
- Container availability
- Automated rollouts and rollbacks
- Load balancing and traffic routing
- Upscaling and downscaling containers across the infrastructure
- Provisioning security and configuration management
Many tools help with the above-mentioned tasks of container orchestration. They manage users’ containers and provide them with resources. Some of the popular container orchestration tools are Kubernetes, Docker Swarm, and Apache Mesos. In the third article in the series, we will dig deeper into one such orchestration tool. We will look into Kubernetes architecture and its various components. Kubernetes will be installed via minikube and also over KVM nodes with some common container runtimes such as CRI-O, Docker Engine, and Containerd.




















{kind=link}