






























































Losing your baggage while travelling to another country can upset everything you have planned for your trip. This is where a range of open source databases can be of help. Let’s find out how.
Venkat boarded a flight at JFK airport, New York for a three-week visit to India. After a long and tiring journey, he arrived in Chennai. After clearing immigration, he walked to the baggage claim area, waited and waited, and soon realised that his baggage had not arrived in the same flight.
Venkat approached the airline’s customer service desk to report the situation. The airline representatives, although sympathetic, could provide no immediate solutions. The luggage did not arrive even on subsequent flights of the airline over the next two days. Days turned into weeks, and Venkat’s luggage remained missing. He returned to New York without his lost baggage and took the airlines to court for an inconsistent response about the whereabouts of his baggage.
Why did this happen? How could it have been avoided?
The impact of inadequate data
Airlines can face significant challenges when they lack access to adequate data or fail to effectively utilise the data they have. Here are a few ways in which this can happen.
Database problems: While inadequate data alone may not be the sole cause for the closure of an airline, it can contribute to operational challenges and financial difficulties that may eventually lead to closure.
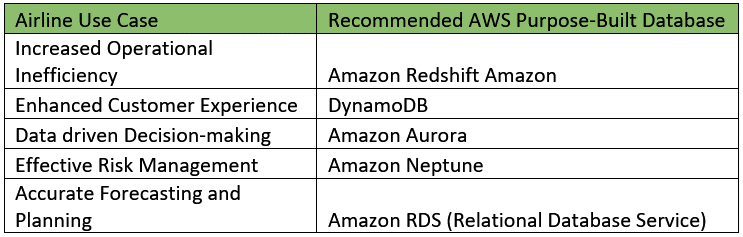
Operational inefficiency: Without comprehensive data, airlines may struggle to optimise their operations. They may face difficulties in predicting passenger demand, managing flight schedules, and allocating resources efficiently. Inadequate data can lead to inefficiencies in crew scheduling, aircraft utilisation, and maintenance planning, resulting in increased costs and decreased operational performance.
Poor customer experience: Data plays a crucial role in delivering personalised experiences to passengers. When airlines lack sufficient customer data, they may struggle to understand passenger preferences, anticipate their needs, and provide tailored services. This can result in a generic and impersonal customer experience, leading to decreased customer satisfaction and loyalty.
Inaccurate decision-making: Data-driven decision-making is critical for airlines to stay competitive. Unavailability of accurate and up-to-date data can result in suboptimal route planning, pricing strategies, and marketing campaigns, leading to missed revenue opportunities and diminished profitability.
Ineffective risk management: Inadequate data can hinder airlines’ ability to assess and mitigate risks effectively. Without comprehensive data on weather patterns, air traffic congestion, or potential disruptions, airlines may struggle to proactively manage and respond to operational challenges. This can result in flight delays, cancellations, and customer dissatisfaction.
Limited forecasting and planning: Data is essential for forecasting future trends, anticipating market changes, and planning for the long term. Without access to robust data, airlines may find it challenging to accurately predict passenger demand, adjust capacity, or respond to market fluctuations. This lack of foresight can lead to missed opportunities or inadequate preparations for changing market dynamics.
Challenges in getting accurate data
Airlines face several challenges when it comes to obtaining adequate data in a timely manner.
Data volume: Airlines receive huge volumes of data and sometimes their on-premises database systems cannot expand dynamically to a spike in data.
Data fragmentation: Airlines often have data scattered across various systems, departments, and third-party providers, making it challenging to consolidate and integrate data from multiple sources into a cohesive and unified data set. Incomplete or disconnected data can limit the ability to gain a comprehensive view of operations or customer insights.
Legacy systems and infrastructure: Many airlines still rely on legacy systems that were not designed to handle the vast amounts of data generated in today’s digital age. Outdated infrastructure and technology may lack the scalability and processing power needed to capture, store, and analyse large volumes of data in real-time. Upgrading or replacing legacy systems can be costly and time-consuming.
Data quality and standardisation: Ensuring data quality and standardisation is crucial for accurate analysis and decision-making. Airlines may encounter issues with inconsistent data formats, missing or erroneous data, and data duplication. This can lead to unreliable insights and hinder the ability to derive meaningful conclusions from the data.
Data security and privacy: Airlines deal with sensitive data, including passenger information, payment details, and operational data. Ensuring data security and privacy is a significant concern. Compliance with regulations such as GDPR (general data protection regulation) and maintaining robust cyber security measures add complexity to data management. Striking a balance between data accessibility and protection is essential.
Data silos and interoperability: Different departments within an airline may operate in silos, each with its own set of data and systems. Lack of interoperability and data sharing between departments can impede the ability to gain holistic insights. Integrating data across different systems and fostering collaboration among departments is necessary for a comprehensive view of operations.
Real-time data availability: Accessing and processing data in real-time can be challenging due to various factors such as system latency, data transmission delays, and reliance on batch processing. Ensuring the availability and timeliness of real-time data can be a complex task.
Data governance and data culture: Establishing robust data governance practices and fostering a data-driven culture within an airline is vital. This includes defining data ownership, establishing data management frameworks, and ensuring data literacy among employees. Without proper governance and a culture that values data-driven decision-making, it can be difficult to prioritise data initiatives and utilise data effectively.
Getting a budget for investing in IT systems is a major challenge, which is why modern databases are sometimes not employed. Fortunately, cloud-based database systems have almost zero upfront investments.
Advantages of cloud managed databases
Small and big organisations move to the cloud for database hosting due to the scalability, cost efficiency, high availability, global accessibility, security, simplified management, and integration capabilities offered by cloud providers. These advantages allow businesses to focus on their core competencies while leveraging the benefits of cloud-based database solutions.
Cloud databases offer several advantages, including scalability without upfront investments, cost efficiency through pay-as-you-go pricing, high availability and reliability, global accessibility for remote collaboration, robust security and compliance measures, simplified management and automation, and seamless integration with other cloud services. These benefits drive businesses to adopt cloud-based solutions for their database hosting needs. Getting a buy-in from management is easy due to no prior capex budget requirements.
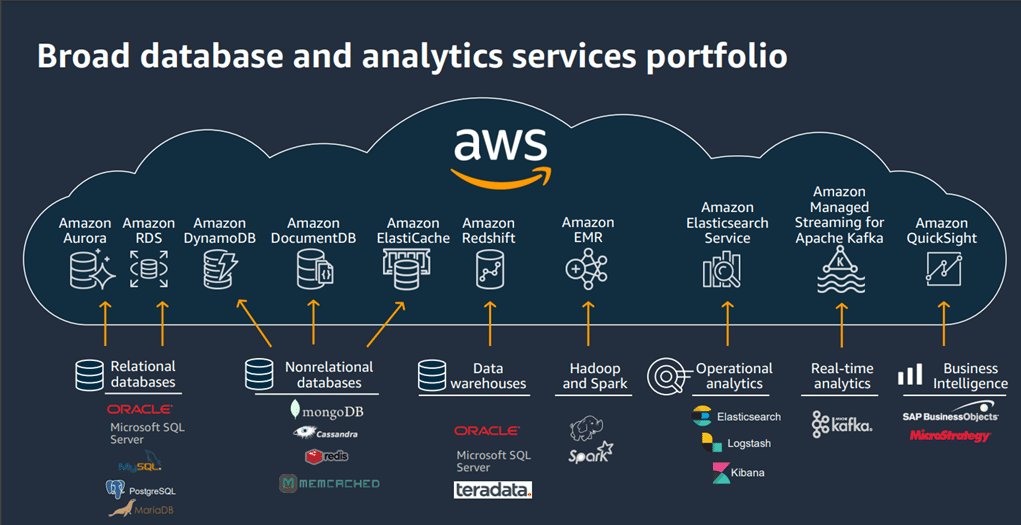
Let us see how AWS services help organisations to achieve data maturity in a cost-effective way and provide quality data on time.
Database freedom with AWS
Amazon Web Services (AWS) offers a comprehensive suite of database services that empower businesses with the freedom to design, deploy and manage databases tailored to specific needs. It offers scalable, flexible, secure and cost-effective database solutions.
With AWS, businesses can effortlessly scale the databases up or down based on fluctuating workloads. It provides managed database services like Amazon RDS (relational database service), Amazon Aurora, and Amazon DynamoDB that automatically handle tasks such as hardware provisioning, software patching, and database backups allowing organisations to focus on their core competencies.
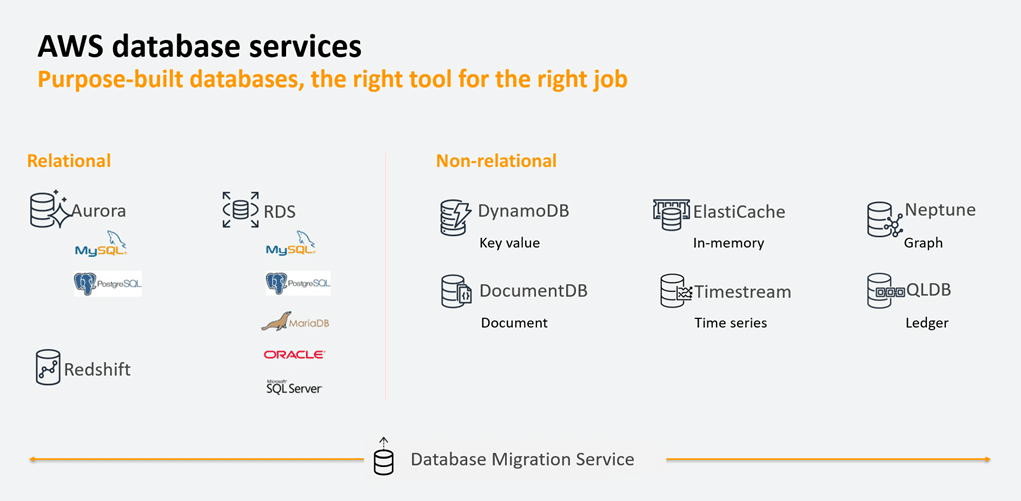
Purpose-built database services offered by AWS
AWS offers a wide range of purpose-built database services that cater to specific use cases and requirements. These services are designed to provide organisations with scalable, high-performance, secure, and cost-effective database solutions.
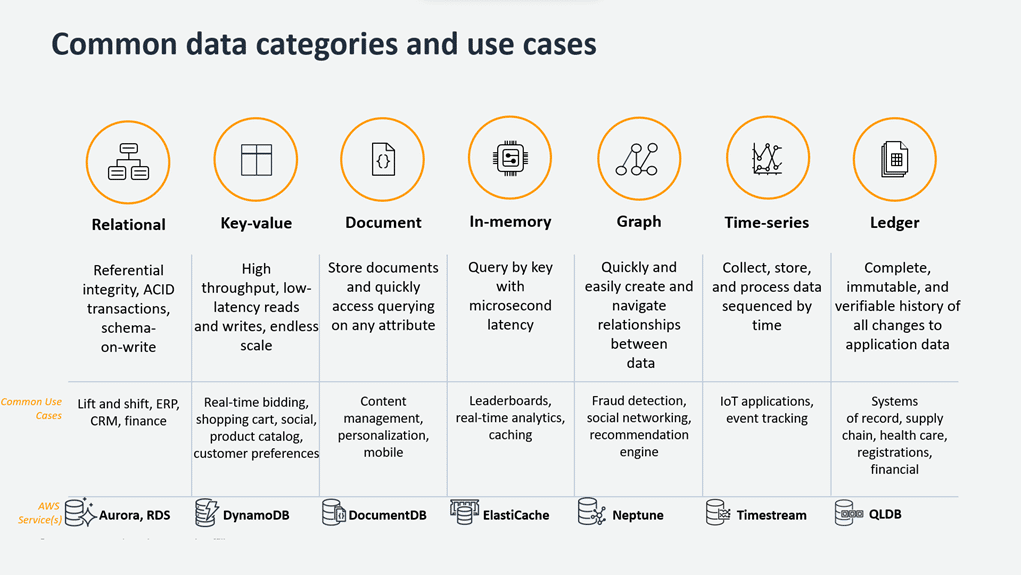
The first factor to consider when choosing a purpose-built database is the application workload, which falls into three categories: transactional (OLTP), analytical (OLAP), and caching. Transactional workloads involve high concurrency with small data operations, while analytical workloads aggregate large volumes of data for reporting. Caching workloads store frequently accessed data for faster response times. Understanding the workload helps in selecting the right database for a specific use case.
The second factor to consider when choosing a purpose-built database is the shape of data. This includes understanding the entities, relationships, access patterns, and update frequency. Common data models include relational, key-value or wide-column, document, and graph. Assessing a data’s shape helps determine the best-suited database for that application.
When choosing a purpose-built database, it’s also important to consider the performance requirements of the application. Factors to assess include data access speed, record size, and geographic considerations. For critical workloads with users expecting quick responses, an in-memory cache can help reduce latency. If the focus is on internal analytics or background data processing, handling large data volumes becomes a priority. Some databases offer data replication across multiple regions, minimising response times by keeping data closer to users. Taking these performance factors into account ensures the selected database aligns with the application’s specific needs.
Finally, when choosing a purpose-built database, consider the operations burden. AWS purpose-built databases handle many operations automatically, including instance failures, backups, and upgrades. With fully managed databases from AWS, you can focus on developing features and innovating for the users while leaving the operational aspects to AWS.
Development teams can select the most suitable database for their specific application needs, rather than relying on multi-purpose databases. This shift allows better alignment between application requirements and database capabilities.
Open source databases supported by Amazon RDS
Amazon RDS is a managed service provided by AWS for launching and managing relational databases designed for online transaction processing (OLTP) and serves as a drop-in replacement for on-premises database instances. Key features include automated backups, patching, scaling and redundancy.
Amazon RDS supports various open source database engines such as MySQL, PostgreSQL, and MariaDB. The service provides security, easy scaling for storage and compute, multi-AZ deployments for high availability, automatic failover, and read replicas for read-heavy workloads.
A DB instance in Amazon RDS represents a database environment in the cloud with specified compute and storage resources. Database instances are accessed via endpoints, which can be obtained through various methods. Customers can have up to 40 RDS DB instances by default for all three open source databases specified. Maintenance windows can be configured for modifications, and customers can define their preferred window or AWS can schedule a 30-minute window.
Open source NoSQL databases provided by Amazon EMR
Amazon EMR (Elastic MapReduce), a managed service for processing and analysing large amounts of data, supports more than thirty plus open source Big Data frameworks including Apache Hadoop, HBase and Apache Spark. It simplifies the deployment and management of these frameworks, allowing users to focus on data processing tasks without worrying about infrastructure. EMR seamlessly integrates with Amazon S3, enabling easy data ingestion and storage. Users can read data from S3 directly into EMR, process it, and write the results back to S3, which makes EMR and S3 a powerful combination for building data lakes. Running clusters can be reconfigured.
Amazon EMR platform service allows users to provision and manage clusters of virtual servers (EC2 instances) on which the Big Data processing frameworks run. Users can define the cluster size, instance types, and other configurations to meet their specific requirements.
Amazon EMR Serverless is an extension of Amazon EMR that offers a serverless Big Data processing option. It allows Apache Spark, Apache Hive, and HBase to run on-demand without the need to provision or manage clusters manually. It automatically scales resources based on the workload and charges only for the actual usage.
EMR on EKS (Elastic Kubernetes Service) is a relatively new offering that helps to run Apache Spark on Amazon EKS, a managed Kubernetes service. With EMR on EKS, scalability and flexibility of Kubernetes to manage and scale Spark workloads is leveraged, integrating with other AWS services.

Apache HBase on Amazon EMR
Two storage modes (S3 and HDFS) are available for EMR managed HBase. We will discuss only the S3 storage mode.
By leveraging Apache HBase on Amazon EMR, you can benefit from simplified administration, flexible deployment, unlimited scalability, seamless integration with other AWS services, and reliable built-in backup functionality.
Apache HBase follows a ‘bytes-in/bytes-out’ interface, which means that any data that can be converted into an array of bytes can be stored as a value in HBase. This allows for flexibility in storing various data types, such as strings, numbers, complex objects, or even images.
Apache HBase reads and writes are highly consistent. In this service, the basic unit is a column. One or more columns form a row. Each row is addressed uniquely by a primary key referred to as a row key. A row in Apache HBase can have millions of columns. Each column can have multiple versions with each distinct value contained in a separate cell.
A column family is a container for grouping sets of related data together within one table, as shown in Figure 6.

Column families allow you to fetch only those columns that are required by a query. All members of a column family are physically stored together on a disk. This means that optimisation features, such as performance tunings, compression encodings, and so on, can be scoped at the column family level.
A row key can consist of multiple parts concatenated to provide an immutable way of referring to entities. Row keys are always unique and act as the primary index in Apache HBase. Secondary indexes are not supported in HBase and can be created by periodically updating a secondary table or using the co-processor framework. In Figure 6, Baggage_id is the row key, Details and Tracking are column families, while passenger_id, flight_number, etc, are all columns.
Columns are addressed as a combination of the column family name and the column qualifier is expressed as family:qualifier. All members of a column family have the same prefix. In the preceding example, the passenger_id and flight_number column qualifiers can be referenced as Details: passenger_id and Details: flight_number, etc.
In Apache HBase, all rows are always sorted lexicographically by row key. The sort is byte-ordered and each row key is compared at a binary level, byte by byte, from left to right.
Open table format
Table formats organise data files aiming to incorporate database-like functionalities into data lakes. Apache Hive is a pioneering and widely adopted table format. However, it has certain drawbacks, including:
- Outdated table statistics related to partition life cycle.
- The requirement for users to possess knowledge about the physical data layout.
- Absence of lineage and historical tracking.
- Lack of support for schema evolution.
- Inefficient for small updates; rewrites entire partitions for even very small updates.
- Lacks ACID compliance.
- Has row level upserts.
These drawbacks can be overcome by using open source Apache Iceberg combined with HBase and Apache Spark, which are all available out-of-the-box on AWS EMR.
The five key features of Apache Iceberg that help to combine with HBase, RDS and Spark queries are expressive SQL queries, hidden partitioning, schema evolution, time travel, and data compaction. These enable a comprehensive and efficient data management solution for data lake tables. They address common challenges in data lake environments and perform complex operations while maintaining data integrity and query performance.
We can use JDBC catalog, HBase catalog, S3 catalog and Spark catalog, and leverage Iceberg’s catalogue switching facility.
The solution
Efficient baggage management is a critical aspect of the aviation industry. As the baggage journey involves multiple airlines and airports, it necessitates robust data management systems that can handle vast amounts of data while ensuring accuracy, reliability, and real-time access. Let us create an innovative airline baggage management system capable of handling the baggage journey life cycle. We will follow the IATA provided BIX messaging standard for our baggage information and streamlining operations while providing real-time insights.
Our modern BMS architecture will centre around data lakehouses, powered by a synergistic combination of AWS supported open source services like EMR HBase, RDS PostgreSQL, S3, EMR Apache Spark, Apache Iceberg, along with the usage of its catalogs (JDBC, Spark, and HBase).
Lakehouse architecture: The lakehouse architecture combines the best aspects of data warehouses and data lakes, enabling efficient storage, processing, and analysis of data. It leverages the strengths of S3 as a scalable and durable storage system while incorporating features such as data versioning, schema evolution, and ACID-compliant transactions.
Apache Iceberg is integrated into the lakehouse architecture to provide data versioning, schema evolution, and table management capabilities. It ensures consistent and reliable snapshots of the ‘baggage_tracking’ table in the EMR HBase, facilitating analysis and enabling rollback to previous data versions if required.
S3 serves as a reliable and scalable storage system within the lakehouse architecture. It acts as a central data repository, enabling seamless integration with other systems involved in the baggage journey life cycle. S3 allows archival storage of raw BIX data, backups, and large media files associated with baggage events.
Data ingestion: Baggage data, following the IATA BIX format, is collected from various sources such as check-in systems, scanning devices, and baggage handling systems. The data is ingested into the system and stored in an S3 bucket as raw files, maintaining the original BIX format. Each bag event or BIX message is stored as a separate file with a unique identifier.
RDS PostgreSQL – metadata and passenger information: Passenger information, including flight details, passenger names, and baggage configuration, are stored in RDS PostgreSQL. The ‘passenger_info’ table serves as a centralised repository for passenger-related data. It updates the baggage tracker table on the open table in real-time using Iceberg’s JDBC catalog.
EMR HBase – baggage events and tracking: Baggage tracking information extracted from the BIX data, such as bag tag ID, airport codes, time stamps, and status updates, is stored in EMR HBase. Although a lot of tables are created for BMS, we will focus on two key tables due to their enormous volume. Bagevent table will have 30 row entries per bag minimum and the ‘baggage_tracking’ table created and frequently updated using the HBase catalog. Partitioning and queries on the lakehouse can be made using Iceberg’s HBase catalog.
EMR Apache Spark – real-time query: EMR Apache Spark processes the BIX data in real-time, leveraging the Spark catalog for seamless access to data sources. Spark jobs execute on the EMR cluster, enabling advanced analytics, real-time alerts, and visualisation of baggage tracking data. The integration with the lakehouse architecture allows Spark to efficiently query and analyse data from both HBase and PostgreSQL.
The volume of airlines baggage data is really huge. The beauty of today’s complex systems is that there is space for every technology. Adopting a lakehouse architecture that combines modern cloud supported open source databases, Big Data and analytics features not only empowers the airline baggage management system to optimise baggage operations and improve the passenger experience, but also creates new opportunities for ground operations, efficient load planning, etc.


















{kind=link}