

PySpark is being widely used today for processing Big Data. This powerful and versatile tool is a boon for any organisation dealing with such data. Here’s a short tutorial on its installation and use.
PySpark is the Python library for Apache Spark, which is a comprehensive analytics engine for processing Big Data. PySpark allows Python programmers to interface with the Spark framework and write Spark programs using Python. Companies such as Amazon, eBay, Yahoo, Netflix, Google, Hitachi Solutions, TripAdvisor, Databricks, Autodesk, UC Berkeley, etc, use PySpark for Big Data processing. Figure 1 shows industrial use cases of PySpark.
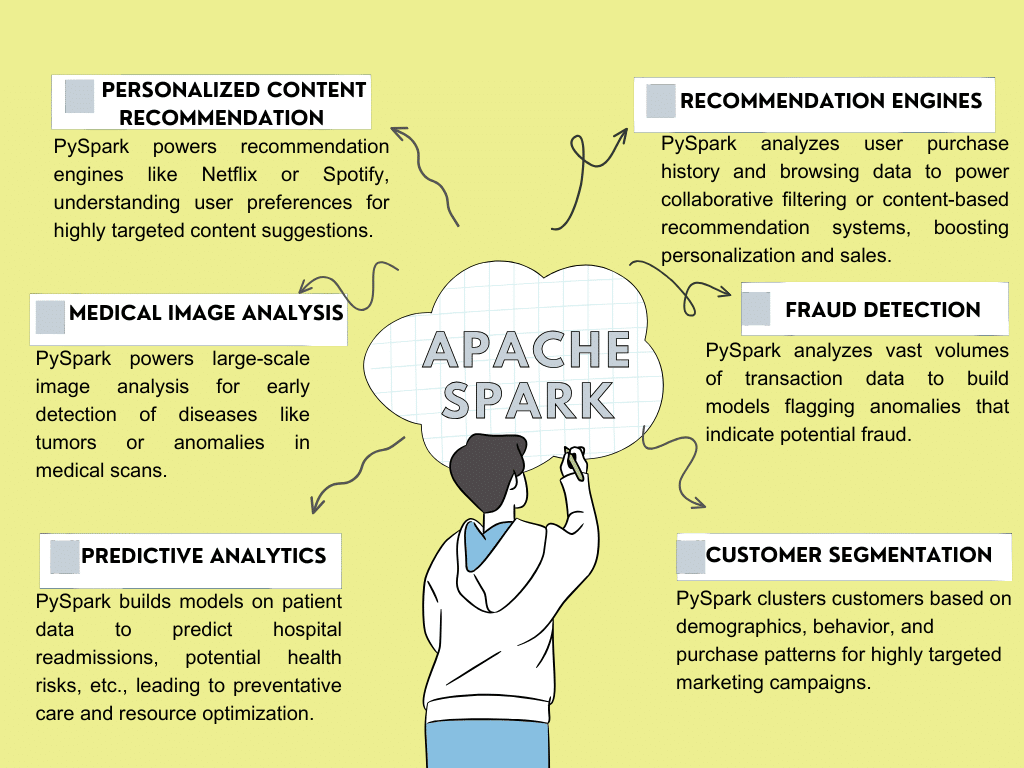
Apache Spark ecosystem
The Apache Spark ecosystem refers to the collection of tools, libraries, and components that surround the Apache Spark distributed computing framework. This ecosystem is designed to enhance the capabilities of Spark and make it more versatile and easier to use for various Big Data processing and analytics tasks. Figure 2 shows the components of the Spark ecosystem.
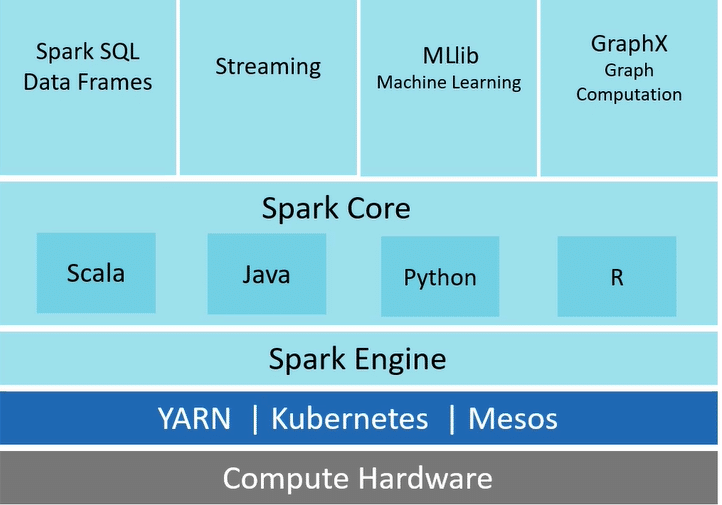
Spark Core is the fundamental component of the Big Data ecosystem that provides features like resource management, job scheduling, fault tolerance, and interface with external storage systems.
Spark SQL, Streaming, MLlib, and GraphX are built on Spark Core and provide specialised functionalities for specific data processing tasks.
Spark SQL enables working with structured data using SQL-like queries.
Spark Streaming provides stream processing functionalities for handling real-time data.
MLlib offers various machine learning algorithms for tasks like classification, regression, and clustering.
GraphX offers functionalities for graph processing tasks like creating graphs, manipulating graph data, and running graph algorithms.
Spark can be deployed on cluster managers like YARN, Mesos, and Kubernetes.
Several alternative tools and frameworks for Apache Spark are popular in the market. Some of the best ones include Hadoop MapReduce, Apache Flink, Apache Storm, SQL, and Pandas. These tools offer different features and capabilities. Table 1 compares Apache Spark with its top alternative tools.
Table 1: Comparison of Apache Spark with other popular tools
| Feature | Apache Spark | Apache Hadoop | SQL | Pandas |
| Primary use | Big Data processing, analytics, machine learning | Distributed storage and processing | Querying and managing relational databases | Data manipulation and analysis in Python |
| Programming model | Scala, Java, Python, R |
Java | Relational database management system (RDBMS) | Python |
| Fault tolerance | Provides fault tolerance through lineage and RDDs | Provides fault tolerance through replication and checkpointing | Depends on the DBMS and its configuration | Limited fault tolerance mechanisms |
| Performance | In-memory processing, faster than Hadoop | Slower than Spark, disk-based processing | N/A | Fast, but limited by memory and single machine |
| Ease of use | High | Lower than Spark, complex MapReduce programming | High for querying, moderate for complex tasks | High |
| Machine learning | Built-in MLlib library | Can integrate with various machine learning tools | Limited to querying, no built-in ML capabilities | Can integrate with machine learning libraries |
PySpark installation in Colab Notebook
Setting up PySpark in Google Colab involves a few steps to ensure you have the necessary dependencies installed and configured correctly. Here’s a step-by-step guide.
Step 1. Install PySpark: Run the following code in a Colab cell to install PySpark:
! pip install pyspark
Step 2. Environment setup: Set the Spark home environment variables.
import os import sys # os.environ[“SPARK_HOME”] = “/content/spark-3.2.1-bin-hadoop3.2”
Step 3. Extract Spark: Download and extract the Spark binary. You can do this using the following code:
!wget -q https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz !tar xf spark-3.2.1-bin-hadoop3.2.tgz !pip install -q findspark !pip install pyspark !pip install py4j
Step 4. Start Spark session: Start a Spark session in your Colab notebook. This step initialises Spark and allows you to use PySpark:
import pyspark from pyspark.sql import DataFrame, SparkSession from typing import List import pyspark.sql.types as T import pyspark.sql.functions as F spark= SparkSession \ .builder \ .appName(“Our First Spark Example”) \ .getOrCreate() spark
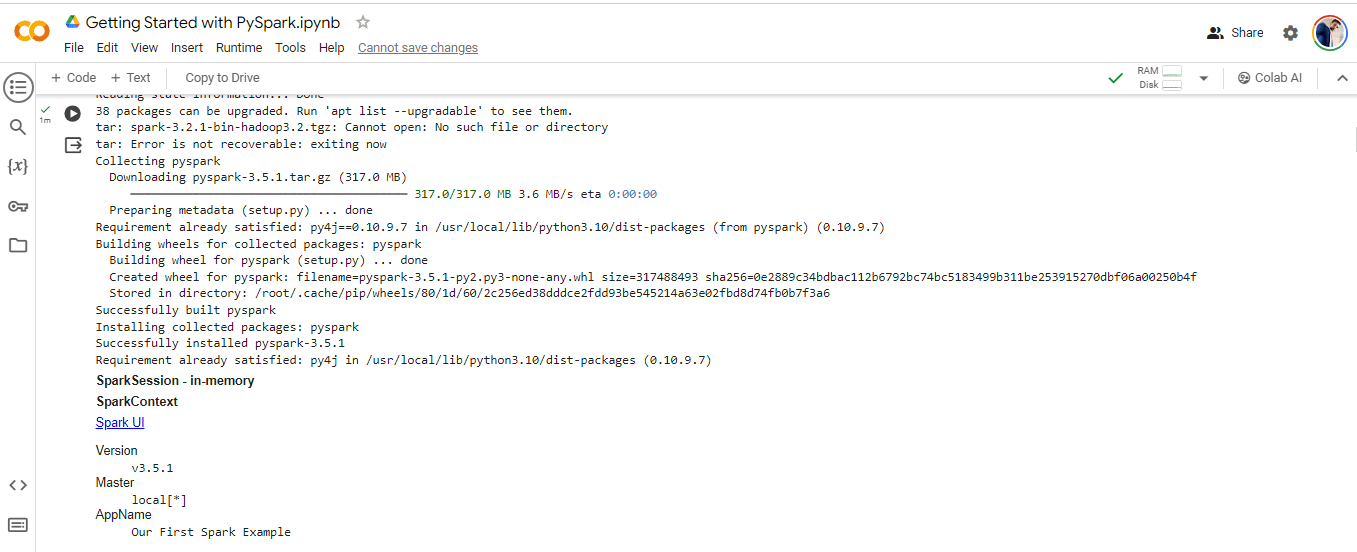
Step 5. Verify installation: Figure 3 shows the successful installation of PySpark.
Step 6. Create a test DataFrame (DF): DF is a fundamental data structure that represents a structured, immutable, and distributed collection of data. For example, you can create a PySpark DataFrame with the sample shown in Figure 4.

PySpark is a versatile and powerful tool for processing and analysing Big Data. Its distributed computing capabilities, combined with the ease of use and flexibility of the Python programming language, makes it an asset for data professionals and organisations dealing with large scale data processing tasks. In short, PySpark is a gateway to a world of possibilities where data-driven insights can transform businesses and drive success.



{kind=link}