





























































Generative AI is making its mark in diverse fields, but it must be nurtured with care to ensure it’s free of bias and preserves human values.
Generative AI is a branch of artificial intelligence focused on producing new data that resembles its training examples. Unlike discriminative models that classify or detect patterns, generative models create original outputs such as text, images, music, or video. By learning the structure of data, these systems can produce realistic and novel content, making them influential across creative industries, research, and automation.
Recent advances in model scale and performance have accelerated interest in generative AI. Large language models can draft articles or hold conversations, image systems generate visuals from text prompts, and audio models synthesize speech or music. This progress marks a shift in AI’s role from analytical assistance to creative collaboration.
However, these capabilities also introduce risks. Deepfakes, factual inaccuracies, and biased outputs highlight the need for responsible development and oversight. Hence, understanding generative AI requires both technical knowledge and ethical awareness.
The journey so far
Research on generative models spans several decades in machine learning. Early work relied on probabilistic approaches such as Gaussian mixture models and hidden Markov models, which established the basic principles of modelling data distributions. The deep learning era introduced more powerful frameworks, most notably Generative Adversarial Networks (GANs) by Goodfellow et al and Variational Autoencoders (VAEs) by Kingma and Welling, which renewed widespread interest in generative modelling (see References at the end of this article).
Subsequent developments included flow-based models with exact likelihood training and autoregressive approaches like PixelCNN and WaveNet that generated data sequentially. In recent years, diffusion models and Transformer based architectures have achieved major breakthroughs. Diffusion methods now lead in image and audio synthesis, while Transformers originally designed for sequence tasks have become central to large scale language and multimodal generation.
The rise of large foundation models, which can be adapted to many tasks after pre-training, has further unified progress in the field. Prior surveys have compared technical trade-offs and discussed ethical implications such as deepfakes and bias. Building on this literature, our work provides an updated overview that connects recent technical advances with practical applications and ongoing challenges.
| Model type | Year | Key idea | Strengths | Challenges |
| Generative Adversarial Network (GAN) | 2014 (Goodfellow et al) | Uses two neural networks (generator and discriminator) trained in a minimax adversarial setup | Generates high-fidelity, sharp samples; very fast inference | Difficult to train due to instability; suffers from mode collapse; lacks explicit likelihood function |
| Variational Autoencoder (VAE) | 2013 (Kingma & Welling) | Learns probabilistic latent encodings using KL-divergence regularisation | Stable training process; interpretable latent space; enables likelihood estimation | Outputs can appear blurry; requires careful balance between reconstruction loss and regularisation |
| Diffusion model | 2015/2020 (Sohl-Dickstein et al; Ho et al) | Recovers data from noise by reversing a diffusion process through iterative denoising | Achieves state-of-the-art generation quality; avoids mode collapse | Sampling is slow; computationally expensive; requires many denoising steps |
| Transformer-based models (e.g., GPT) | 2017/2020 (Vaswani et al; Brown et al) | Uses self-attention mechanisms to learn long-range dependencies in an autoregressive manner | Highly effective for language tasks; processes long contexts; flexible across domains | Requires significant computational resources; may hallucinate facts; interpretability remains difficult |
Technical foundations of generative AI
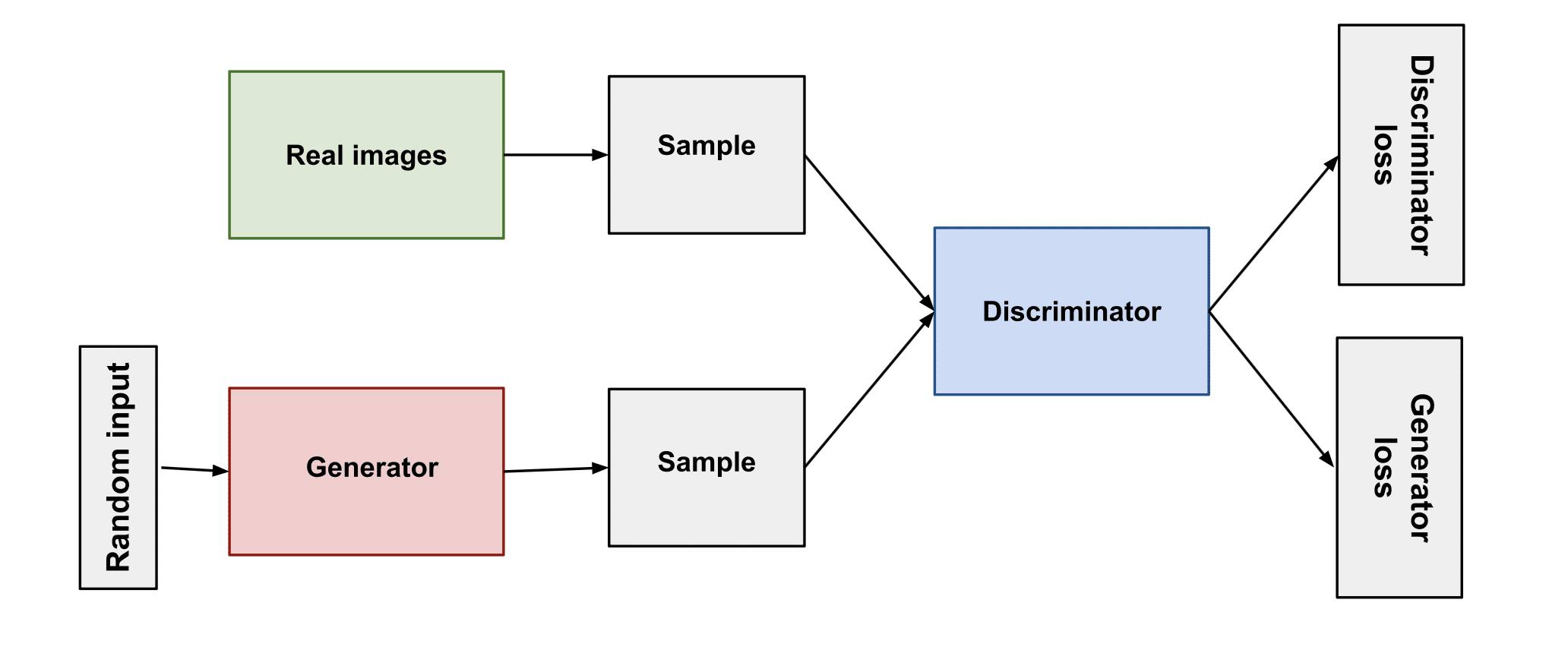
Generative AI is built on machine learning models that learn the structure of data and create new samples from it. The four major model families behind modern systems are Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), diffusion models, and Transformer-based models. We briefly describe the intuition behind each approach and highlight their main strengths and limitations. Figure 1 presents a GAN architecture, while Table 1 compares these paradigms.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) model learning as a competition between two neural networks: a generator and a discriminator. Proposed by Goodfellow et al, the generator G produces synthetic samples from random noise, while the discriminator D attempts to distinguish real data from generated outputs. Both networks are trained together in an adversarial setup, forming a minimax optimisation problem in which G tries to fool D and D learns to detect fakes.
Figure 1 illustrates this interaction, which can be viewed as a two-player game. As training progresses, the generator becomes better at producing realistic data while the discriminator sharpens its detection ability. Successful training allows GANs to approximate the true data distribution, leading to highly realistic outputs. Models such as StyleGAN demonstrated this capability through convincing face and scene synthesis.
GANs are especially known for producing sharp, detailed images, making them effective for tasks like image synthesis and super-resolution. However, they are difficult to train and prone to issues such as mode collapse or unstable convergence. They also do not provide explicit likelihood estimates. Despite these drawbacks, GANs remain widely used in computer vision due to their strong visual quality.
Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) take a probabilistic approach to generative modelling. Introduced by Kingma and Welling in 2013, VAEs extend the traditional autoencoder by representing each input as a distribution in latent space rather than a fixed vector. The encoder outputs parameters of this distribution, usually a Gaussian, while the decoder samples from it to reconstruct data. Training optimises the evidence lower bound (ELBO), balancing reconstruction accuracy with a regularisation term that shapes a smooth latent space.
VAEs are generally stable and easier to train than GANs, and they provide explicit likelihood estimates that support tasks such as interpolation and anomaly detection. Their main limitation is output sharpness: generated images often appear blurrier compared to GAN results because of the trade-off between fidelity and regularisation. Even so, VAEs remain valuable where structured latent representations or probabilistic reasoning are important, particularly in scientific and hybrid generative systems.
Diffusion models
Diffusion models generate data by gradually denoising random noise, drawing inspiration from physical diffusion processes. They use two stages: a fixed forward process that incrementally adds noise to real data, and a learned reverse process that removes this noise step by step until structure reappears.
Formally, starting from a data sample x0, the forward diffusion produces:
x1, x2, . . . , xT ,
where xT approaches a Gaussian noise distribution. A neural network is trained to reverse this corruption by predicting the clean sample from a noisy input at time step t. To synthesize new data, the model begins with:
xT ∼ N (0, I) and applies xT → xT −1 → · · · → x0.
Because each denoising step is small and stable, diffusion models avoid the instability of adversarial training while producing highly detailed outputs. They currently achieve state-of-the-art results in image generation, often exceeding GANs in visual fidelity.
In practice, these models learn to transform pure noise into realistic samples, leading to strong diversity and quality, especially for images and audio. Training is typically stable but computationally intensive. Their main drawback is slow sampling, since many iterative denoising steps are required, and they do not provide a clear low-dimensional latent space. Even so, diffusion models have become a central technique in modern generative AI due to their reliability and output quality.
Figure 2 illustrates a diffusion model that generates an image through iterative denoising. Step 1 starts with a random noise image. Steps 2 and 3 are intermediate steps, where the model removes noise and begins to reveal structure (in this toy example, a simple shape).
Transformer-based generative models
The Transformer is a deep learning architecture that reshaped generative modelling, particularly in natural language processing. Originally built for sequence tasks, its defining feature is the self-attention mechanism, which allows the model to consider relationships across an entire sequence at once, improving parallelization and long-range coherence.
Transformers power large language models such as GPT-3 and later systems. These models generate text autoregressively by predicting one token at a time while referencing the full prior context, enabling fluent and consistent long-form output. Beyond text, Transformers are also used in image, music, and code generation, often combined with other techniques such as diffusion conditioning or discrete token modelling.
Transformer-based models excel at capturing global context and adapting to multiple tasks through prompting or fine tuning, exemplifying the ‘foundation model’ paradigm. However, they are resource intensive to train and run, and despite their fluency they can still produce inaccurate information. Their scale and complexity also make them difficult to interpret, which raises challenges for transparency and trust.

Applications of generative AI
Generative AI is being applied across many domains, from language and visual media to audio and video. These systems demonstrate strong potential in automating creative work, personalising digital content, and supporting business and research activities.
Text generation and language applications
Natural language generation is one of the most mature areas of generative AI. Large language models such as GPT-3, GPT-4, and Google’s LaMDA can produce coherent and context aware text from short prompts. This capability supports several practical uses:
- Content creation: Assisting with articles, marketing copy, reports, and brainstorming drafts.
- Conversational agents: Powering chatbots and virtual assistants that answer questions and hold interactive dialogues.
- Translation and summarisation: Generating translations or concise summaries of long documents within a unified framework.
- Programming assistance: Producing code snippets or auto completing functions from natural language descriptions.
These tools are increasingly used in customer service, education, and document drafting. However, human oversight remains important because generated text may occasionally be inaccurate or biased.
Image generation and creative design
Image generation has gained significant attention through models such as DALL·E, Stable Diffusion, and Midjourney, which create visuals from textual prompts. Built on GANs and diffusion techniques, these systems are widely used in:
- Art and design: Rapid concept exploration and creative experimentation.
- Image editing: Inpainting, style transfer, and super-resolution enhancement.
- Marketing and advertising: Producing customised visuals at scale without traditional photo shoots.
- Product and architectural design: Generating early-stage prototypes and design variations.
Industries such as e-commerce, gaming, and film-making increasingly adopt these tools, though professional workflows typically involve human review and refinement.
Audio and speech synthesis
Generative AI is also reshaping audio production, particularly in speech and music:
- Speech generation: Text-to-speech systems now produce natural sounding voices and enable controlled voice cloning.
- Music composition: Models can generate melodies, accompaniments, or adaptive background music.
- Sound effects: Dynamic generation of ambient noises and effects for games or virtual environments.
While these technologies enable personalisation and scalability, they also introduce ethical concerns related to voice imitation, copyright, and misuse.
Video generation and animation
Video generation is an emerging frontier for generative AI because maintaining temporal consistency across frames is difficult. Despite this challenge, steady progress is visible:
- Deepfakes (face swapping): Generative models can realistically replace faces in videos. While sometimes used for entertainment, deepfakes also enable misinformation and identity misuse, raising serious ethical concerns.
- Video prediction and generation: Recent research prototypes demonstrate short video creation from text prompts or initial frames, showing early but promising capabilities.
- Animation and gaming: AI tools assist in character animation, physics simulation, and content variation, helping reduce manual design effort in games and media production.
Although fully AI-generated films are still rare, industry use is growing in advertising variations, film restoration, frame interpolation, and virtual backgrounds in conferencing tools. Because humans are sensitive to visual artifacts and motion errors, most current applications focus on short or controlled clips, with quality expected to improve as models and hardware advance.
Ethical and societal considerations
Alongside its technical achievements, generative AI introduces significant ethical and societal challenges. Key concerns include bias, misinformation through deepfakes, hallucinated outputs, intellectual property questions, and broader social impacts. Addressing these issues is essential for responsible deployment and long-term trust.
Bias and fairness
Generative models learn from real-world data that may contain social or cultural biases, which can appear in generated text or images. Such outputs risk reinforcing stereotypes or unequal representation when used at scale. Mitigation requires better dataset curation, bias detection methods, and targeted fine tuning. Ensuring fairness remains an active research and industry priority, particularly in sensitive domains such as recruitment or public services.
Misinformation and deepfakes
Generative AI can produce highly realistic fake media, including images, audio, and video that may be used to mislead or manipulate audiences. This threatens public trust by making it harder to distinguish authentic evidence from fabricated content. In response, researchers are developing detection tools and provenance tracking, while policymakers explore legal safeguards. The dynamics between generation and detection continue to evolve as both technologies improve.
Hallucinations and reliability
Language and multimodal models sometimes produce confident but incorrect information, a phenomenon known as hallucination. This occurs because models predict patterns rather than verify factual truth. In high stakes settings such as healthcare or law, such errors can be harmful. Current mitigation strategies include retrieval augmented generation, grounding outputs in trusted data sources, and human oversight. Improving reliability and explainability is therefore central to building trustworthy generative AI systems.
Intellectual property and ownership
Generative AI complicates traditional ideas of authorship and copyright. When a model trained on large collections of artwork produces a new image, it is unclear who owns the result—the user, the model provider, or the original artists whose styles influenced the output. This uncertainty has already led to legal disputes and ongoing policy debates. While some users view AI outputs as original creations, others argue they may be derivative of training data. Companies are beginning to clarify usage rights, but the legal landscape remains unsettled. Beyond copyright, ethical concerns arise when AI imitates the style or voice of living artists without consent or compensation.
Societal and economic impact
Generative AI’s ability to automate creative tasks raises questions about employment and content quality. Professions such as design, writing, and media production may experience disruption, although new roles centered on supervising or collaborating with AI are also emerging. Education and professional training will likely need to adapt as these tools become common in workflows. Another concern is information overload: when content can be generated at scale, distinguishing reliable and high-quality material becomes more difficult, increasing the risk of spam and misinformation.
In summary, generative AI offers remarkable opportunities but challenges existing norms of creativity, truth, and ownership. Responsible development requires guidelines for fairness, transparency, and accountability. Technical safeguards such as bias auditing and content filtering, along with collaboration between technologists, policymakers, and social scientists, are essential to balance innovation with societal well-being.
Challenges and future directions
Despite rapid progress, generative AI faces several technical and ethical challenges.
Alignment with human values
Ensuring that generative systems behave in ways consistent with human intentions and social norms is a central concern. Techniques such as reinforcement learning from human feedback (RLHF) and content moderation help reduce harmful outputs, but long-term alignment remains an open research problem. Future approaches may involve richer feedback loops, multi-agent critique systems, and broader stakeholder participation in defining acceptable behaviour.
Generalisation and robustness
Generative models often perform well within their training distribution but struggle with unfamiliar scenarios. Improving generalisation may involve combining neural approaches with reasoning modules or enabling rapid adaptation through fewshot learning. Robustness testing, including adversarial evaluation, is increasingly important to ensure reliability across varied inputs and conditions.
Explainability and interpretability
Large generative networks typically function as black boxes, making it difficult to understand why a particular output was produced. This lack of transparency is problematic in sensitive domains. Ongoing research explores attention visualisation, probing techniques, and modular system designs to provide clearer rationales and increase user trust.
Efficiency and scalability
Modern generative models demand significant computational resources for both training and inference. Improving efficiency through model compression, quantization, and more optimised architectures is a key direction. Reducing energy consumption and hardware dependence will be crucial for broader accessibility and sustainability.
Multimodal and general-purpose AI
A clear trend is the development of models capable of handling multiple data types: text, images, audio, and video within unified systems. Such multimodal assistants could coordinate diverse generative tasks, but they also introduce new challenges in training complexity, evaluation, and alignment across domains.
Governance and regulation
As generative AI becomes widespread, governance and policy frameworks will play a larger role. Industry standards for transparency, certification mechanisms, and regulatory safeguards for high-risk applications are likely to emerge. Technical safety measures, combined with interdisciplinary collaboration, will help ensure responsible deployment.
In summary, the future of generative AI is promising but demands careful management of risks and limitations. Progress in alignment, efficiency, and transparency alongside thoughtful governance will determine how effectively these systems augment human creativity and problem solving.
Generative AI has moved in a short time from being a specialised research topic to a major force in modern artificial intelligence. It marks a shift from computers that only analyse information to systems that can actively create it. If developed thoughtfully, it can support human creativity, speed up innovation, and provide personalised solutions on a large scale. The future of generative AI will depend not only on technical breakthroughs, but also on how carefully and responsibly we choose to guide its growth.

















{kind=link}