

This comprehensive and practical guide will help you successfully design, build, and run retrieval-augmented generation (RAG) systems that are viable in production environments.
Retrieval-augmented generation (RAG) combines information retrieval with large language model (LLM) capabilities to provide answers that are based on current, validated sources rather than only on previously accessed information. By using more contextual data added to the answer at the time of response, RAG helps produce ‘grounded’ (i.e., based on evidence), real-time, valid answers.
LLMs are incredibly useful but have many limitations, the most serious one being that they can generate answers based only on their training data. As a result, they are not suitable for providing accurate responses where the answers require current information, knowledge of a specific domain, or proprietary information.
RAG provides the solution to these problems by integrating two separate systems:
- Retriever that retrieves the relevant data from an external data source.
- Generator (LLM) that generates answers based on the data returned from the retrieved context.
Rather than asking the model to retrieve everything, RAG gives it access to retrieve information as needed while processing requests. Therefore, it is particularly useful in the following areas:
- Enterprise knowledge base
- Product documentations and APIs
- Internal tools (i.e., HR, finance, support)
- Regulated industries (i.e., healthcare, legal, finance)
Most RAG examples found online are demo-grade systems. They work well for tutorials but fail under real-world constraints.
Table 1: The difference between demo RAG and production RAG systems
| Dimension | Demo RAG | Production RAG |
| Data size | Few documents | Millions of chunks |
| Updates | Manual, static | Continuous ingestion |
| Retrieval | Simple vector search | Hybrid + re-ranking |
| Latency | Ignored | Static SLAs |
| Evaluation | Manual inspections | Automated metrics |
| Reliability | Best effort | Fault-tolerant |
RAG architecture
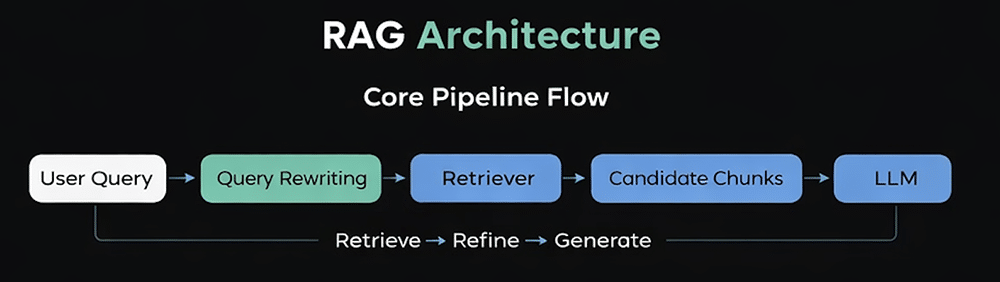
To create a production-level RAG system, we use a structured pipeline design that separates the knowledge retrieval process from the language generation process. The operating flow of the RAG system has a defined path to follow during runtime. First, the system analyses and rewrites a user query in order to improve the effectiveness of its retrieval process. Next, the system uses a ‘retriever’ to find matching vector, or hybrid, database entries for the query, returning a set of candidate text ‘chunks’ (potential pieces of text).
Finally, the retrieved chunks are refined and assembled into a bounded context which can be provided to the LLM as a basis for generating the final response. This process of retrieve-refine-generate, as shown in the architectural flow diagram (Figure 1), provides assurance that the LLM’s answer is built on externally verified source material rather than solely on its internally trained data.
There are two pipelines in RAG architecture: offline and online. Offline pipelines create knowledge before the user sends queries by reading source documents, cleaning and standardising text, cutting content into pieces with clear meanings, adding more information about the item, and creating and storing embeddings of the item in a vector database. This type of processing is done with an emphasis on the rate of processing (throughput), not the speed at which it is processed. Therefore, offline processing can happen using a batch.
Online pipelines respond to the request of an end user in real-time and have strict guidelines regarding latency. The online pipeline includes query rewriting, retrieval of related items, re-ranking the retrieved items, constructing the context, and running inference with an LLM.
By separating the offline and online pipelines, the overall system can scale without affecting the performance of real-time queries due to large and costly indexing.
How does a production-grade RAG architecture work?
Production-ready RAG architectures are heavily influenced by the latency and cost constraints presented on them. As an example, every stage of your online pipeline contributes to your overall latency budget, and LLM inference is typically the most latency- and cost-contributing stage. Given that LLM inference is often the most expensive stage in your production-ready RAG pipeline, retrieval and re-ranking must both be fast and efficient, ensuring that a limited number of high-quality chunks are fed into your model.
In addition, from a cost perspective, architecture must be designed such that system resources are progressively used. This means that retrieval operations (which are typically low-cost) must be performed prior to higher-cost operations like re-ranking and LLM generation, in order to identify the context needed to perform them. This layer-oriented design approach ensures predictable performance, controlled token usage, and the ability to scale as both data volume and query traffic increase.
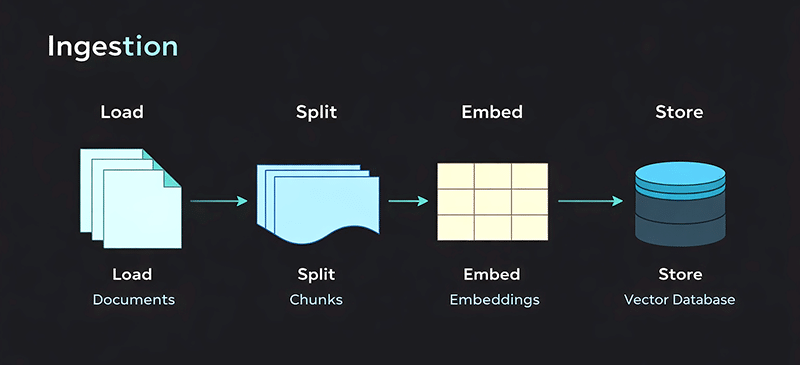
Data ingestion: Preparing knowledge for retrieval
The process of data ingestion is a crucial element of a production-ready RAG system — it changes raw enterprise data into knowledge that can be retrieved. In the production environment, ingestion is an ongoing process whereby an automated pipeline is created to maintain data quality, currency, and traceability.
Step 1. Source types (Load)
RAG systems can ingest data from several different sources (e.g., PDFs, HTML pages, Markdown files, databases, APIs, knowledge bases, and other internal systems). Each type of source requires a specific type of loader to extract the content properly and maintain the document boundaries, timestamps, and access control, all of which are necessary for secure and auditable retrieval.
Step 2. Cleaning and normalisation (Split)
Once loaded into the RAG system, documents undergo a cleaning process to remove noise such as headers, footers, navigation elements, and duplicate content. During this process, the text is normalised (ensuring that all the text uses the same encoding and formatting) and documents are split into semantically meaningful size chunks. This ensures that low-quality text is not embedded in the RAG system, which would then degrade the precision of subsequent retrievals.
Step 3. Metadata enrichment (Embed)
Each chunk of data is enriched with structured metadata (i.e., source, document type, language, version, and date of update). The metadata enables filtered, hybrid and context-enabled retrievals in production systems. The chunks of data are then processed to generate dense vector embeddings of the data. The processing of the chunks is typically performed using a batched approach, which allows for lower cost and higher throughput.
Step 4. Update handling (Store)
Storing all embeddings and their associated metadata occurs through a vector database. Incremental updates occur in production environments by only re-embedding any new or changed documents for production use and by deprecating old content with versioning and soft deletes. By using these processes for deprecation of old or outdated content, the accuracy of retrieval from the vector database will not require the entire corpus to be reprocessed.
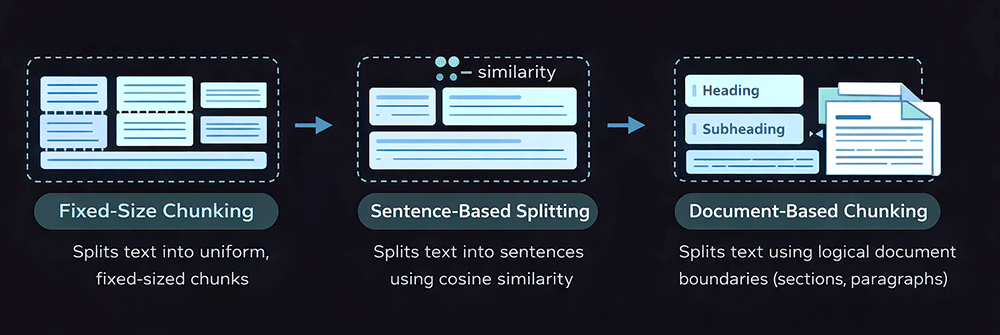
Chunking and the types of chunking strategies
The process of breaking down raw documents into smaller units of knowledge for use in embedding and retrieval processes is called chunking. The design of the chunks directly impacts the retrieval accuracy, context relevance, and ability to control hallucination in RAG systems. Poorly designed chunks may yield insufficient or noisy context sent back by the retriever (due to either the design of the chunks or poor quality of the embeddings), resulting in the LLM generating incomplete or inaccurate answers, even when it has high-quality embeddings as a source.
Chunks that are too small lose any connected semantics and relationships, which may affect performance, whereas chunks that are too large introduce irrelevant context and waste tokens. A well-designed chunking strategy will allow each chunk to be retrievable, meaningful, and self-containing.
Fixed size chunking
The document is broken up into chunks that are characterised by the presence of tokens (single units of language), for example, in fixed size chunks. The advantage of this method is speed and ease of implementation, but the disadvantage is that it often breaks apart logical boundaries in a way that creates discontinuities in the represented data.
from typing import List import re # Split the text into units (words, in this case) def word_splitter(source_text: str) -> List[str]: source_text = re.sub(“\s+”, “ “, source_text) # Replace multiple whitespces return re.split(“\s”, source_text) # Split by single whitespace def get_chunks_fixed_size_with_overlap(text: str, chunk_size: int, overlap_fraction: float = 0.2) -> List[str]: text_words = word_splitter(text) overlap_int = int(chunk_size * overlap_fraction) chunks = [] for i in range(0, len(text_words), chunk_size): chunk_words = text_words[max(i - overlap_int, 0): i + chunk_size] chunk = “ “.join(chunk_words) chunks.append(chunk) return chunks
Sentence-based chunking
The sentences in the document are used as the points at which to divide it up into chunks. The option of merging chunks into single ones based upon their similarity may be considered as well when implementing this strategy. This method provides better structural support than the previous method of chunking at fixed sizes; however, it can still be impeded by chunks created from conceptually multi-sentence pieces or lengthy explanations.
from typing import List def recursive_chunking(text: str, max_chunk_size: int = 1000) -> List[str] # Base case: if text is small enough, return as single chunk if len(text) <= max_chunk_size: return [text.strip()] if text.strip() else [] # Try separators in priority order separators = [“\n\n”, “\n”, “. “, “ “] for separator in separators: if separator in text: parts = text.split(separator) chunks = [] current_chunk = “” for part in parts: # Check if adding this part would exceed the limit test_chunk = current_chunk + separator + part if current_chunk else part if len(test_chunk) <= max_chunk_size: current_chunk = test_chunk else: # Save current chunk and start new one if current_chunk: chunks.append(current_chunk.strip()) current_chunk = part # Add the final chunk if current_chunk: chunks.append(current_chunk.strip()) # Recursively process any chunks that are still too large final_chunks = [] for chunk in chunks: if len(chunk) > max_chunk_size: final_chunks.extend(recursive_chunking(chunk, max_chunk_size)) else: final_chunks.append(chunk) return [chunk for chunk in final_chunks if chunk] # Fallback: split by character limit if no separators work return [text[i:i + max_chunk_size] for i in range(0, len(text), max_chunk_size)]
Document-based chunking
Chunks are created from chunks based upon logical document boundaries (headings, subheadings, paragraphs, and sections), allowing the content’s intended meaning as well as its structure to be retained, making this option the optimal method of chunking for any production RAG systems, particularly for technical, legal, or knowledge-based documents.
from typing import List
import re
def markdown_document_chunking(text: str) -> List[str]:
# Split by markdown headers (# ## ### etc.)
header_pattern = r’^#{1,6}\s+.+$’
lines = text.split(‘\n’)
chunks = []
current_chunk = []
for line in lines:
# Check if this line is a header
if re.match(header_pattern, line, re.MULTILINE):
# Save previous chunk if it has content
if current_chunk:
chunk_text = ‘\n’.join(current_chunk).strip()
if chunk_text:
chunks.append(chunk_text)
# Start new chunk with this header
current_chunk = [line]
else:
# Add line to current chunk
current_chunk.append(line)
# Add final chunk
if current_chunk:
chunk_text = ‘\n’.join(current_chunk).strip()
if chunk_text:
chunks.append(chunk_text)
return chunks
Embeddings and vector storage power semantic retrieval
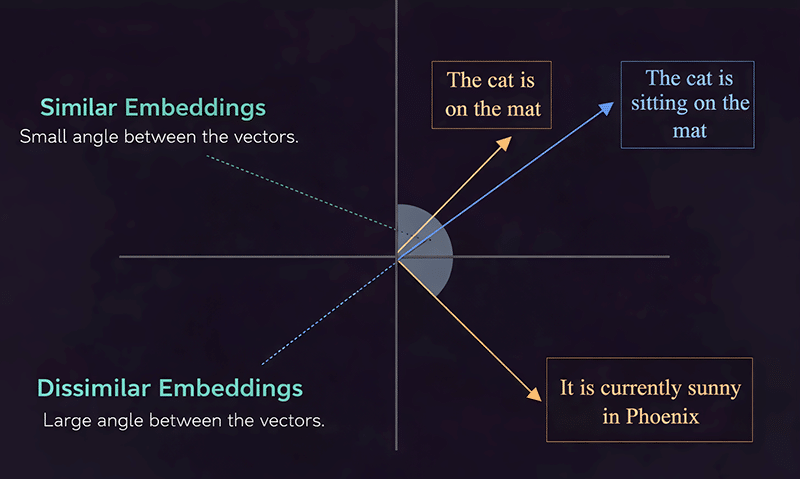
Embeddings take content (such as text and audio data) and convert it into numeric arrays that represent the meaning of the data. Figure 4 illustrates that semantically related sentences create embeddings that are closer together than disparate sentences. Once you select your embedding model, you will be balancing between quality, latency, and cost (the larger your model, the more semantic information will be created, whereas the smaller the model, the more likely that it will meet your specific case). Within a production system, embeddings should be normalised and batched together, and to further boost retrieval, an additional layer of multilingual embeddings can support cross-lingual retrieval within the same pipeline.
The embeddings are stored in a vector database that has been designed to operate using similarity search techniques. Because of this, there are several different index types available (some index types trade off speed for accuracy and others scale differently). Metadata filters also exist that can be used to filter through data based on the source, language, and section. Also, hybrid forms of retrieval exist that combine both the results from the similarity search and either keyword-based filtering or rule-based filtering. This will also provide a more precise and dependable answer in retrieval-augmented generators.
The way retrieval logic and context construction work
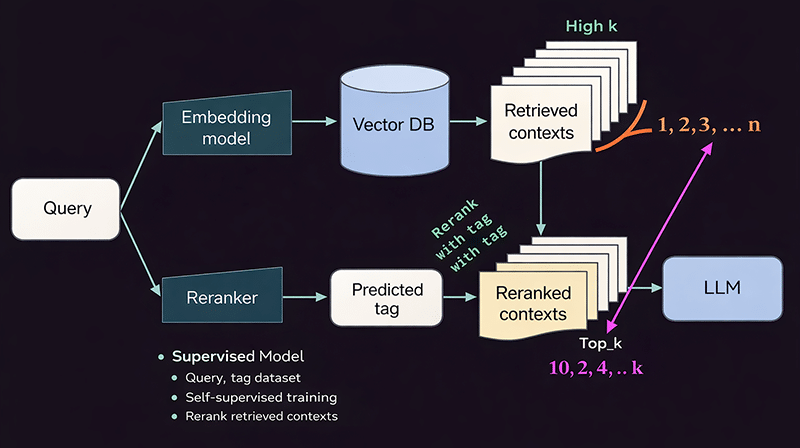
The query is embedded in a vector database for similarity-based retrieval so that there can be a large number (n = ?) of candidate chunks returned in order to maximise recall. Top-K tuning manages how many chunks are carried forward based upon the trade-offs between relevance, latency, and cost. To ensure there is no redundancy in the chunk candidates, a method called MMR Retrieval, which uses diversity to find relevant chunks, is often applied. Finally, chunks are reordered based on deeper levels of relevance through a re-ranking model (based on query–chunk or query–tag matches), so that the best chunks of context reach the LLM. Query rewriting may also be used to clarify intended meaning and to increase retrieval accuracy.
From the re-ranked results, only the top-K chunks are selected to fit within the LLM (limited tokens). The chunks will be ordered according to relevance and injected into a structured prompt so that the instruction, context, and query are clearly separated. By controlling tight context and relevance filtering, we can minimise hallucinatory data so that responses are based on retrieved data.
Why evaluation and feedback loops are essential for production RAG
RAG evaluation assesses full cycle validation between queries, context retrieved and response generated. Retrieval metrics measure how well the retrieved context matches the query intent, i.e., do the pieces of content retrieved correspond to the intended query? The answer’s quality is then measured by how well grounded the answer is, and whether it has relevance to the context from which it is being generated. These two sets of metrics ultimately contribute signals to help continuously improve query rewriting, retrieval ranking and selection of chunks.
Many pitfalls in production create direct breaks to the above-mentioned loop. For instance, over-chunking fragments the meaning and leads to reduced groundedness, whereas neglecting to use metadata results in irrelevant context returned. Sending too much context returned (retrieval inflation) wastes tokens and dilutes relevance, while failure to have fallbacks produces ungrounded answers when no high-quality context exists. To maintain RAG systems that produce reliable, hallucination-resistant outcomes, corrective measures must be taken.
You should now be able to understand the working of an end-to-end production-ready RAG system. Once you have this solid foundation, the building of RAG from the ground upwards will be methodical rather than overwhelming. Using these rules step by step will allow you to successfully transition from an experimental phase to an operationally sustainable, real-world RAG pipeline.



{kind=link}