






























































The Gluster file system is an open source distributed file, which can scale out in a ‘building block’ manner to store several petabytes of data. This article will be of interest to newbies and those who wish to know more about file systems.
A distributed file system gives us a way of storing and accessing files in a client-server architecture. We can use more than one server to store data and use multiple clients (local or remote) that can access data from these servers. A distributed file system organises and displays files and directories from multiple servers as if they were stored in your local system, thereby projecting a simple interface to the user or application. The main advantage is that it is easier to distribute documents to multiple clients and provide a centralised storage system so that client machines do not use their resources to store the data.
GlusterFS concepts
Some of the basic terminology that we need to know to understand GlusterFS is given in Table 1.
 Introducing GlusterFS
Introducing GlusterFS
GlusterFS is a distributed file system that can scale up to several petabytes and can handle thousands of clients. It clusters together storage building blocks over RDMA or TCP/IP, and aggregates disk and memory resources in order to manage data in a single global namespace. These blocks do not need any special hardware to store data and are based on a stackable user space design. GlusterFS is a user space file system and hence uses FUSE (file system in user space) to hook itself with the virtual file system (VFS) layer. FUSE is a loadable kernel module that lets non-privileged users create their own file systems without editing kernel code. Gluster uses already tried and tested disk file systems like ext3, ext4, xfs, etc, as the underlying file system to store the data.
Daemons
Before we can create a volume, we must have a trusted storage pool consisting of storage servers that provide bricks to create the volume. Every node has a daemon – glusterd – running (this is a management daemon). Each glusterd can interact with the glusterd on other nodes to add them to its trusted storage pool. This is called peer probing. A node can have multiple peers. For example, if nodes A and B are peers, and if node A adds node C as a peer, then nodes A, B and C all become peers and can participate in the creation of volumes. We can also remove nodes from the trusted storage pool. To create a volume we can use bricks from any number of nodes, provided they are in the same trusted storage pool. On one node, we can create multiple bricks and hence can host multiple volumes.
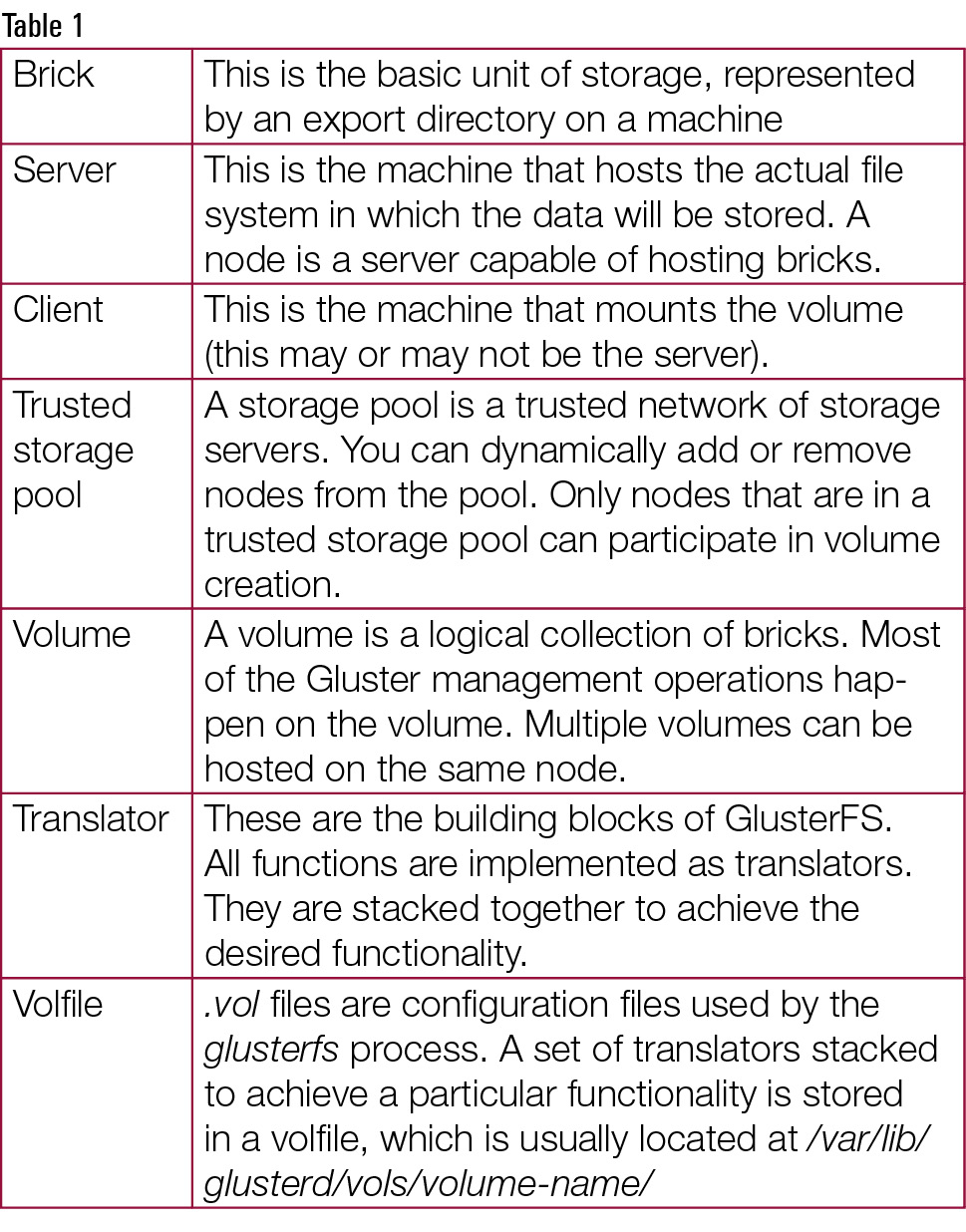
As a part of volume creation glusterd will generate client and server volfiles. A volfile is a configuration file that has a collection of translators, where each translator has a specific function to perform and together implement the desired functionality. These files are stacked in a hierarchical structure. A translator receives data from its parent translator, performs the necessary operations and then passes the data down to its child translator in the hierarchy.
Winding fop via the client-server graph
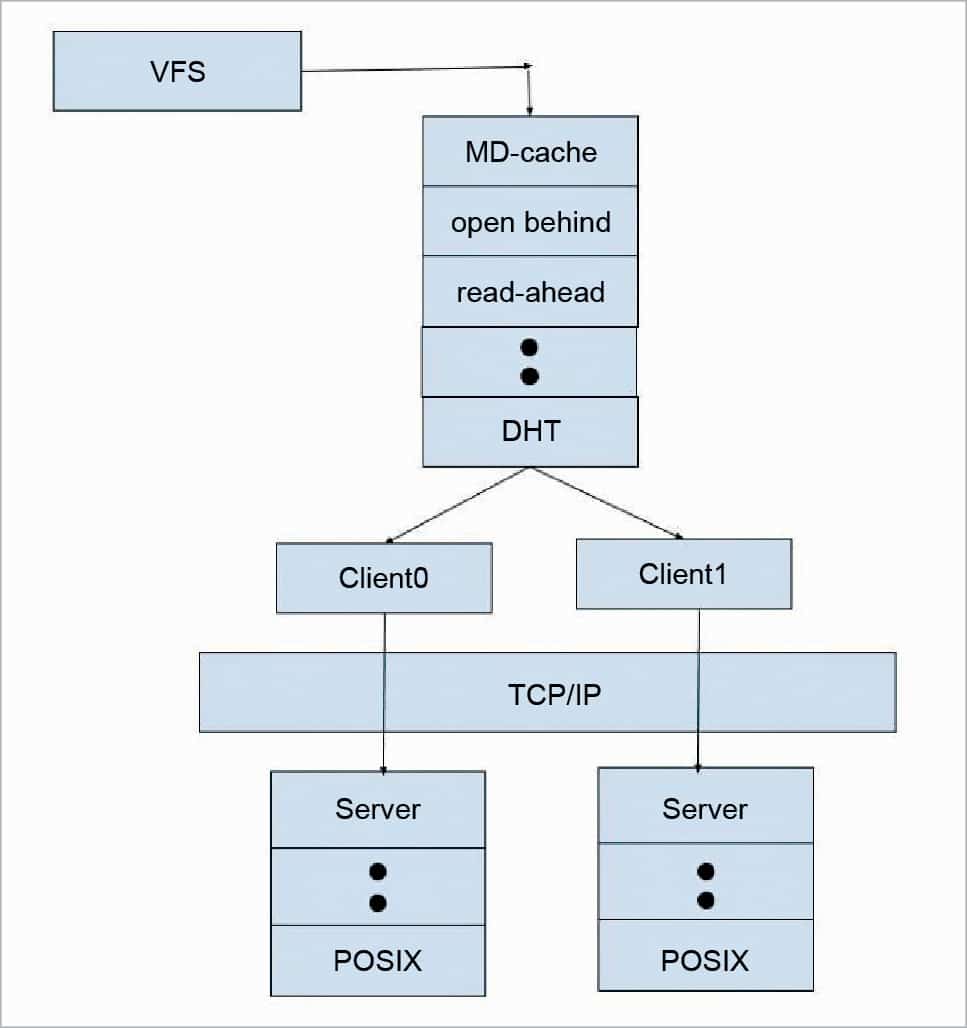
On mounting a volume on a client machine, a glusterfs client process is spawned, which interacts with the glusterd process and gets a configuration file or the client volfile. Glusterd also sends a list of ports on which the client can talk to each brick.
When we issue a file operation or fop, VFS hands the request to the FUSE module which, in turn, hands the request to the GlusterFS client process. The GlusterFS client processes the request by winding the call to the first translator in the client volfile, which performs a specific operation and winds the call to the next translator. The last translator in the client volfile is the protocol client, which has the information regarding the server side bricks and is responsible for sending the request to the server (each brick) over the network. On the server stack, the first translator loaded in the protocol server is responsible for getting the package. Depending on the options set, there might be a few more translators below it. Finally, the request reaches the POSIX file system.
Types of volumes
The Gluster file system supports different types of volumes, depending on the requirements. Some volumes are good for scaling storage volumes, some for improving performance and some for both.
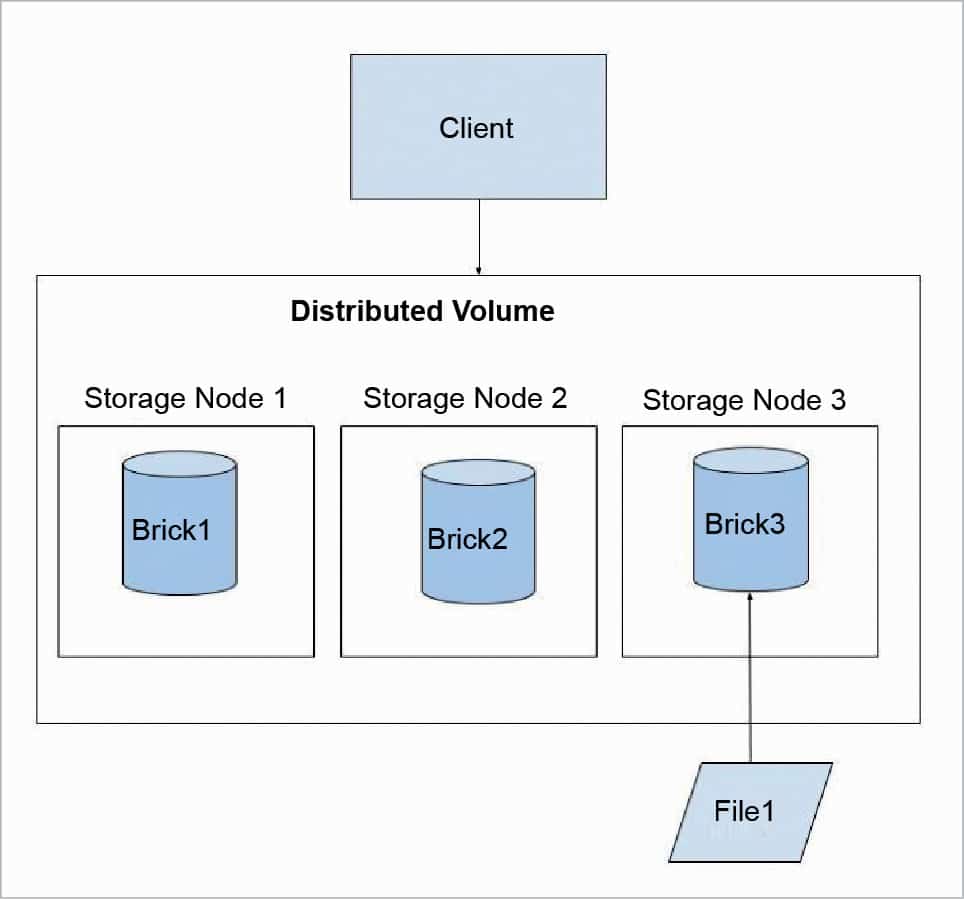
Distributed GlusterFS volume: This is the default GlusterFS volume, i.e., while creating a volume, if you do not specify the type of the volume, the default option is to create a distributed type of volume. In this volume, files are randomly stored across the bricks in the volume. There is no data redundancy. The purpose for such a storage volume is to scale easily. However, this also means that a brick failure will lead to complete loss of data and one must rely on the underlying hardware for protection from data loss.
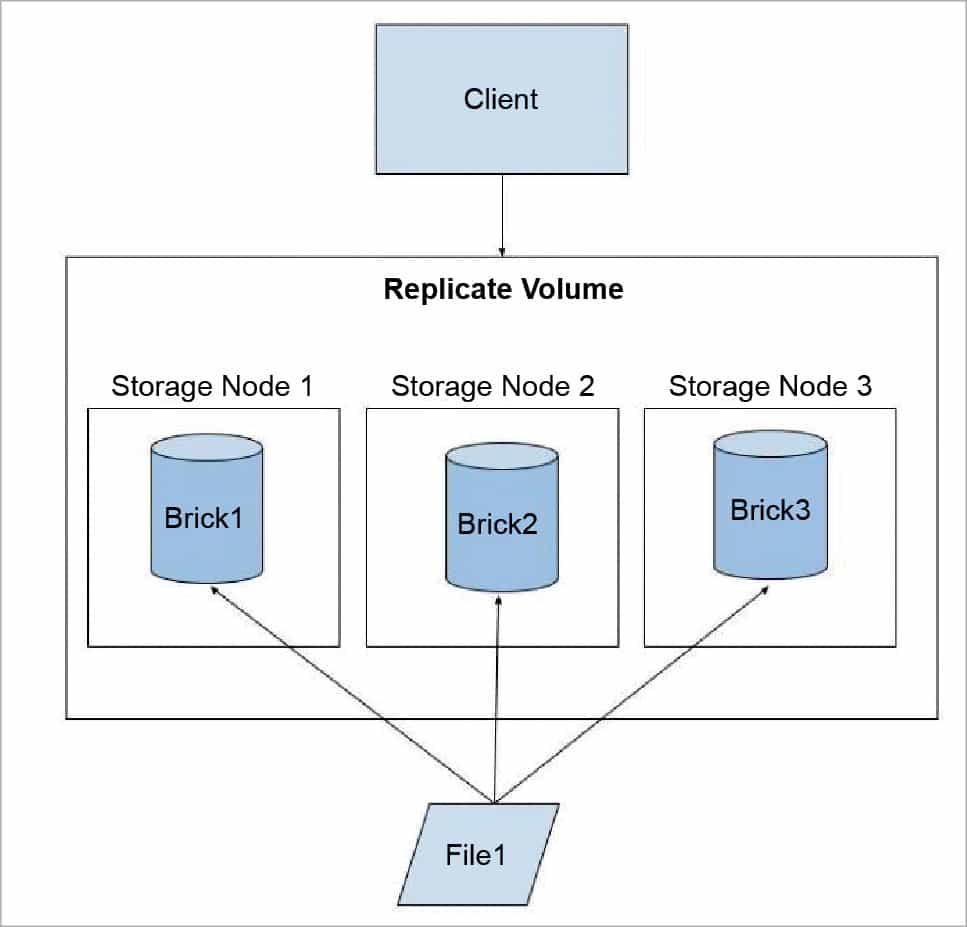
Replicated GlusterFS volume: In this volume, we overcome the data loss problem faced in the distributed volume. Here, an exact copy of the data is maintained on all the bricks. The number of replicas in the volume can be decided by the client while creating the volume. One major advantage of such a volume is that even if one brick fails, the data can still be accessed from its replica brick. Such a volume is used for better reliability and data redundancy.
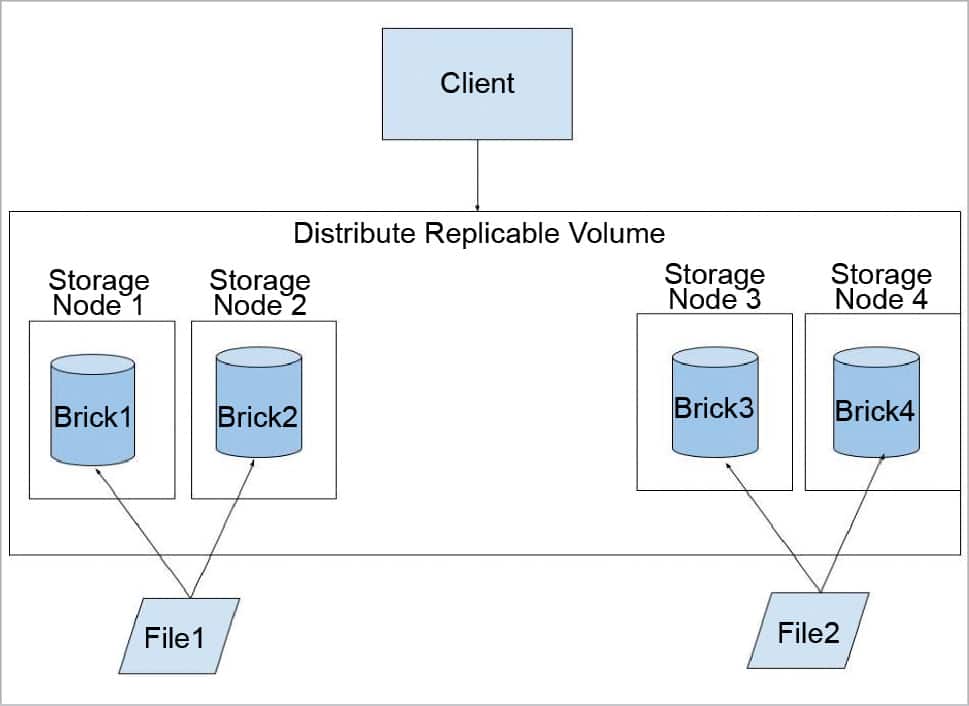
Distributed replicated GlusterFS volume: This volume combines the advantages of both a distributed and a replicated volume. In this volume, files are distributed across replicated sets of bricks. The number of bricks must be a multiple of the replica count. Also, the order in which we specify the bricks matters since adjacent bricks become replicas of each other. This type of volume is used when high availability of data due to redundancy and scaling storage is required. So, if there are eight bricks and the replica count is 2, then the first two bricks become replicas of each other; then the next two and so on. This volume is denoted as 4×2. Similarly, if there are eight bricks and the replica count is 4, then four bricks become a replica of each other and we denote this volume as 2×4.
Striped GlusterFS volume: Consider a large file being stored in a brick that is frequently accessed by many clients at the same time. This will cause too much load on a single brick and might reduce its performance. In a striped volume, the data is stored in the bricks after dividing it into different stripes. So, the large file will be divided into smaller chunks (equal to the number of bricks in the volume) and each chunk is stored in a brick. Now, the load is distributed and the file can be fetched faster but no data redundancy is provided.
Reliability
To maintain availability and ensure data safety, it is recommended that you create a distributed replicated volume. We must have the replica pairs on different nodes, so that even if a node comes down, the other replica pair can be used to access data, which is immediately replicated on all pairs. Another data safety feature in GlusterFS is geo-rep. Geo-replication provides asynchronous replication of data across geographically distinct locations. It mainly works across a WAN and is used to replicate the entire volume, unlike Automatic File Replication (AFR) which is intra-cluster replication (used for replicating data within the volume). This is mainly useful for backup of the entire data for disaster recovery.
GlusterFS performance
There are some translators that help in increasing the performance in GlusterFS. These, too, are present in the client volfile.
Readdir-ahead: Once a read request is completed, GlusterFS pre-emptively issues subsequent read requests to the server in anticipation of those requests from the user. If a sequential read request is received, the content is ready to be immediately served. If such a request is not received, the data is simply dropped.
IO-cache: This translator is used to cache the data that is read. This is useful if many applications read data multiple times and reads are more frequent than writes. The cache is maintained as an LRU list. When io-cache receives a write request, it will flush the file from the cache. It also periodically verifies the consistency of the cached files by checking the modification time on the file. The verification timeout is configurable.
Write-behind: This translator improves the latency of a write operation by relegating it to the background and returning to the application even as the write is in progress. Using the write-behind translator, successive write requests can be pipelined, which helps to reduce the network calls.
Without the write-behind translator, once an application has issued a write call, it goes to the VFS and then to FUSE, which initiates a write call that is wound till it reaches the protocol client translator, which sends it to the server. Once the client receives a reply from the server, it returns it to the FUSE. With a write-behind translator, once the application issues a write call, it reaches VFS, then FUSE and then initiates the write call which is wound only till the write-behind translator. Write-behind adds the write buffer to its internal queue and returns with success. Write-behind initiates a fresh writev() call to its child translator, whose replies will be consumed by write-behind itself. Write-behind doesn’t cache the write buffer.
Stat-prefetch: The purpose of this translator is to store the stat information. It helps to optimise operations like ls -l, where a readdir is followed by a stat on the entry. This translator needs to maintain the following fops.
1. Lookup: Checks if the entry is present, and if so, then the stat information is returned from this translator rather than winding the call till the server. If the entry is not present, then we wind the lookup call and cache the stat information.
2. Chmod/chown: If a chmod or chown is performed, then the entry must be removed, since these calls change the ctime of directories.
3. truncate/ftruncate/setxattr: The entry must be removed, since these calls change the mtime of the directories.
4. Rmdir: Deletes the entry from the cache and then proceeds to remove the entry from the back-end.















