






























































This is the era of Big Data and these are undoubtedly revolutionary times. Massive amounts of data are being generated by the hour, from social media and from enterprises. It would be extremely foolish to waste this treasure trove by simply doing nothing about it. Enterprises have learnt to harvest Big Data to earn higher profits, offer better services and gain a deeper understanding of their target clientèle.
Big Data basically refers to the huge amounts of data, both organised and unorganised, that enterprises generate on a day-to-day basis. In this context, the volume of data is not as relevant as what organisations do with the data. Analysis of Big Data can lead to insights that improve strategic business decision-making.
The importance of Big Data
As mentioned earlier, the value of Big Data does not depend on how much information you have, but on what you are going to do with it. You can harvest data from any point and examine it to find solutions that enable the following four things:
- Price reductions
- Time reductions
- Fresh product development and modified offerings
- Making smart judgements
When you pool Big Data with high-energy analytics, the following business-related tasks are possible:
- Identifying reasons of failures, issues and flaws in real-time.
- Generating vouchers at the point-of-sale based on the customer’s purchasing history.
- Calculating the full risk of certain functions within minutes.
- Detecting deceitful behaviour before it impacts your organisation.
Examples of Big Data
The automotive industry: Ford’s modern-day hybrid Fusion model yields up to 25GB of data per hour. This data can be used to interpret driving habits and patterns in order to prevent accidents, deflect collisions, etc.
Entertainment: The video game industry is using Big Data for examining over 500GB of organised data and 4TB of functional backlogs, each day.
The social media effect: About 500TB of fresh data gets added into the databases of social media site Facebook daily.
Types of Big Data
Big Data can be classified into the following three main categories.
1. Structured: Data that can be stocked, approached and refined in the form of a fixed data format is termed as structured data. With time, computer science has been able to develop methods for running with such data and also deriving value out of it. Nevertheless, these days, we are anticipating issues related to the sheer volume of such data, which is turning into zettabytes (1 billion terabytes equals 1 zettabyte).
2. Unstructured: Data in an unmapped form is known as unstructured data. Large volumes of unstructured data pose many challenges in terms of how to derive value out of it. For example, a heterogeneous data source, incorporating a collection of simple text files, pictures, audio as well as video recordings, will be difficult to analyse. These days, organisations have an abundance of data available to them, but unfortunately they don’t know how to extract value out of it since this data is in an unprocessed form.
3. Semi-structured: This can comprise both forms of data. Also, we can consider semi-structured data as a structure in form, but in reality, the data itself is not defined, e.g., data depicted in an XML file.
The four Vs of Big Data
Some of the common characteristics of Big Data are depicted in Figure 2.
1. Volume: The volume of data is an important factor in deciding on its value. Hence, volume is one property that needs to be considered while handling Big Data.
2. Variety: This refers to assorted data sources and the nature of data, both structured and unstructured. Previously, spreadsheets and databases were the only origins of data considered in most of the practical applications. But these days, data in the form of e-mails, pictures, recordings, monitoring devices, etc, are also being considered in investigation applications.
3. Velocity: This term refers to how swiftly data is generated. How fast the data is created and refined to meet a particular need, determines its real potential. The velocity of Big Data is the rate at which data flows from sources like business procedures, application logs, websites, etc. The speed at which Big Data flows is very high and virtually non-stop.
4. Veracity: This refers to the incompatibility between the various formats that the data is being generated in, thus constraining the process of mining or managing the data profitably.

Big Data architecture
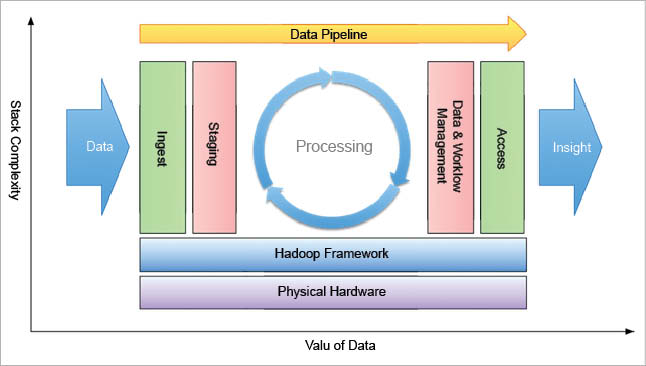
Big Data architecture comprises consistent, scalable and completely computerised data pipelines. The skillset needed to build such infrastructure requires a deep knowledge of every layer in the heap, starting with a cluster design to setting up the top chain responsible for processing the data. Figure 3 shows the complexity of the stack, along with how data pipeline engineering touches every part of it.
In this figure, the data pipelines collect raw data and transform it into something of value. Meanwhile, the Big Data engineer has to plan what happens to the data, the way it is stored in the cluster, how access is approved internally, what equipment to use for processing the data, and finally, the mode of providing access to the outside world. Those who design and implement this architecture are referred to as Big Data engineers.
Big Data technologies
As we know, the subject of Big Data is very broad and permeates many new technology developments. Here is an overview of some of the technologies that help users monetise Big Data.
1. MapReduce: This allows job implementation, with scalability crossing thousands of servers.
- Map: Input dataset transforms into a different set of values.
- Reduce: Many outputs of the Map task are united to form a reduced set of values.
2. Hadoop: This is the most admired execution of MapReduce, being a completely open source platform for handling Big Data. Hadoop is flexible enough to be able to work with many data sources, like aggregating data in order to do large scale processing, reading data from a database, etc.
3. Hive: This is an SQL-like link that allows BI applications to run queries beside a Hadoop cluster. Having been developed by Facebook, it has been made open source for a little while and is a higher-level concept of the Hadoop framework. Also, it allows everyone to make queries against data stored in a Hadoop cluster and has improved on Hadoop’s functionality, making it ideal for BI users.
Advantages of Big Data processing
The capability of processing Big Data has various benefits.
1. Businesses can make use of outside brainpower while taking decisions: The right to use social data from search engines and websites like Facebook and Twitter is enabling enterprises to improve their business strategies.
2. Enhanced customer service: Customer response systems are getting replaced by new systems intended for Big Data technologies. Within these new systems, Big Data technologies are being utilised to read and assess consumer responses.
3. Early recognition of risks for the services: Risk factors can be recognised beforehand to deliver the perfect data.
4. Improved operational competence: Big Data technologies can be utilised for building staging areas or landing zones for new data, prior to deciding what data should be moved to the data warehouse. Also, such incorporation of Big Data and data warehousing technologies helps businesses to bypass data that is not commonly accessed.
The challenges
Though it is very easy to get trapped in all the hype around Big Data, one of the reasons it is so underutilised is that there are many challenges still to be resolved in the technologies used to harness it. Some of these are:
1. Companies face problems in identifying the correct data and examining how best to utilise it. Constructing data-related business cases frequently means forming opinions out-of-the-box and looking for income models that are extremely different from the traditional business model.
2. Companies are reluctant to choose the fine talent that is capable of both working with new technologies and examining the data to find significant business insights.
3. A bulk of data points have not been linked yet, and companies frequently do not have the correct platforms to combine and manage the data across the enterprise.
4. The technology in the data world is evolving very fast. Leveraging data means functioning with well-built, pioneering technology collaborators – companies that can help create the right IT design so as to adapt to changes in the landscape in a well-organised manner.
The accessibility of Big Data, inexpensive product hardware, and new information managing and analytics software have come together to create a unique moment in the history of data analysis. We now have the capability that is necessary to examine these amazing data sets rapidly and cost-effectively, for the first time in history. This ability symbolises an authentic leap forward, and a chance to enjoy massive improvements in terms of work productivity, income and success.
















