





























































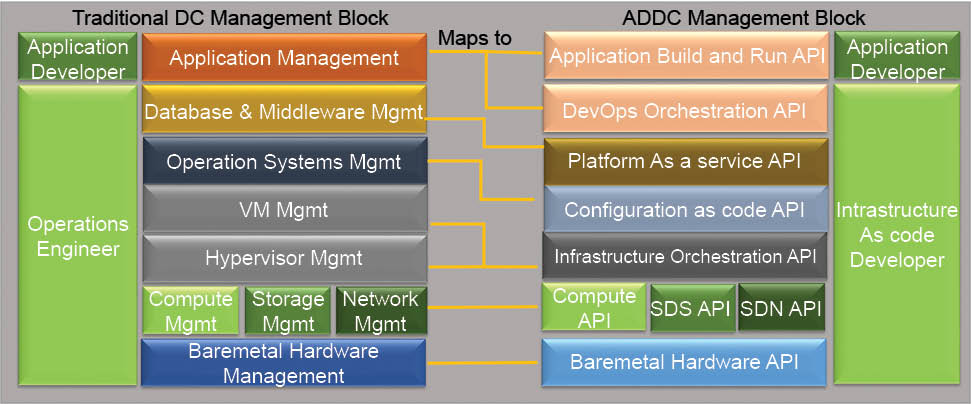
The application driven data centre (ADDC) is a design whereby all the components of the data centre can communicate directly with an application layer. As a result, applications can directly control the data centre components for better performance and availability in a cost-optimised way. ADDC redefines the roles and skillsets that are needed to manage the IT infrastructure in this digital age.
Worldwide, the IT industry is undergoing a tectonic shift. To the Indian IT service providers, this shift offers both new opportunities and challenges. For long, the Indian IT industry has enjoyed the privilege of being a supplier of an English-speaking, intelligent workforce that meets the global demand for IT professionals. Till now, India could leverage the people cost arbitrage between the developed and developing countries. The basic premise was that IT management will always require skilled professional people. Therefore, the operating model of the Indian IT industry has so far been headcount based.
Today, that fundamental premise has given way to automation and artificial intelligence (AI). This has resulted in more demand for automation solutions and a reduction in headcount—challenging the traditional operating model. The new solutions in demand require different skillsets. The Indian IT workforce is now struggling to meet this new skillset criteria.
Earlier, the industry’s dependence on people also meant time-consuming manual labour and delays caused by manual errors. The new solutions instead offer the benefits of automation, such as speeding up IT operations by replacing people. This is similar to the time when computers started replacing mathematicians.
But just as computers replaced mathematicians yet created new jobs in the IT sector, this new wave of automation is also creating jobs for a new generation with new skillsets. In today’s world, infrastructure management and process management professionals are being replaced by developers writing code for automation.
These new coding languages manage infrastructure in a radically different way. Traditionally, infrastructure was managed by the operations teams and developers never got involved. But now, the new management principles talk about managing infrastructure through automation code. This changes the role of sysadmins and developers.
The developers need to understand infrastructure operations and use these languages to control the data centre. Therefore, they can now potentially start getting into the infrastructure management space. This is a threat to the existing infrastructure operations workforce, unless they themselves skill up as infrastructure developers.
So does it mean that by learning to code, one can secure jobs in this turbulent job market? The answer is both ‘Yes’ and ‘No’. ‘Yes’, because in the coming days everyone needs to be a developer. And it’s also a ‘No’ because in order to get into the infrastructure management space, one needs to master new infrastructure coding languages even if one is an expert developer in other languages.
New trends in IT infrastructure
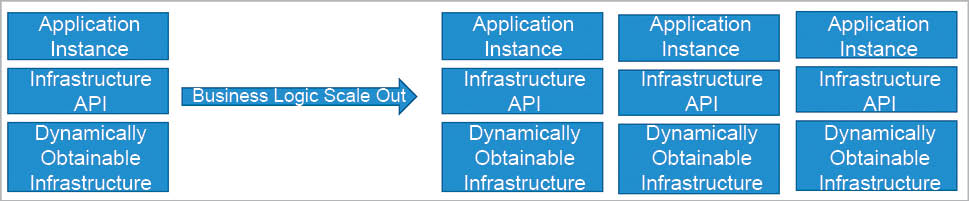
The new age infrastructure is built to be managed by code. Developers can benefit from this new architecture by controlling infrastructure from the applications layer. In this new model, an application can interact with the infrastructure and shape it the way required. It is not about designing the infrastructure with the application’s requirement as the central theme (application-centric infrastructure); rather, it is about designing the infrastructure in a way that the application can drive it (application-driven infrastructure). We are not going to build infrastructure to host a group of applications but rather, we will create applications that can control various items of the infrastructure. Some of the prominent use cases involve applications being able to automatically recover from infrastructure failures. Also, scaling to achieve the best performance-to-cost ratio is achieved by embedding business logic in the application code that drives infrastructure consumption.
In today’s competitive world, these benefits can provide a winning edge to a business against its competitors. While IT leaders such as Google, Amazon, Facebook and Apple are already operating in these ways, traditional enterprises are only starting to think and move into these areas. They are embarking on a journey to reach the ADDC nirvana state by taking small steps towards it. Each of these small steps is transforming the traditional enterprise data centres, block by block, to be more compatible for an application-driven data centre design.
The building blocks of ADDC
For applications to be able to control anything, they require the data centre components to be available with an application programming interface (API). So the first thing enterprises need to do with their infrastructure is to convert every component’s control interface into an API. Also, sometimes, traditional programming languages do not have the right structural support for controlling these infrastructure components and, hence, some new programming languages need to be used that have infrastructure domain-specific structural support. These languages should be able to understand the infrastructure components such as the CPU, disk, memory, file, package, service, etc. If we are tasked with transforming a traditional data centre into an ADDC, we have to first understand the building blocks of the latter, which we have to achieve, one by one. Let’s take a look at how each traditional management building block of an enterprise data centre will map into an ADDC set-up.

1. The Bare-metal-as-a-Service API
The bare metal physical hardware has traditionally been managed by the vendor-specific firmware interfaces. Nowadays, open standard firmware interfaces have emerged, which allow one to write code in any of the application coding languages to interact through the HTTP REST API. One example of an open standard Bare-metal-as-a-Service API is Redfish. Most of the popular hardware vendors are now allowing their firmware to be controlled through Redfish API implementation. The Redfish specifications-compatible hardware can be directly controlled through a general application over HTTP, and without necessarily going through any operating system interpreted layer.
2. The software defined networking API
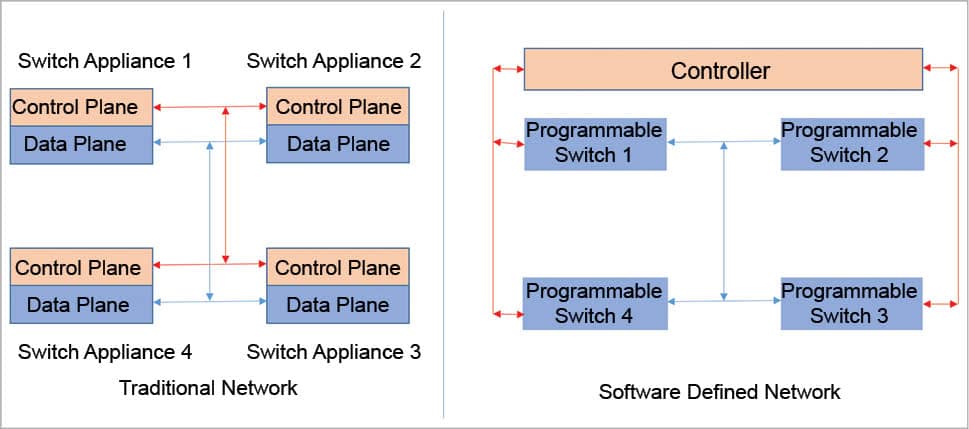
A traditional network layer uses specialised appliances such as switches, firewalls and load balancers. Such appliances have built-in control and data planes. Now, the network layer is transforming into a software defined solution, which separates the control plane from the data plane.
In software defined solutions for networking, there are mainly two approaches. The first one is called a software defined network (SDN). Here, the central software control layer installed on a computer will control several of the network’s physical hardware components to provide the specific network functionality such as routing, firewall and load balancers. The second one is the virtual network function (VNF). Here, the approach is to replace hardware components on a real network with software solutions on the virtual network. The process of creating virtual network functions is called network function virtualisation (NFV). The software control layers are exposed as APIs, which can be used by the software/application codes. This provides the ability to control networking components from the application layer.
3. The software defined storage API
Traditional storages such as SAN and NAS have now transformed into software defined storage solutions, which can offer both block and file system capabilities. These software defined storage solutions are purpose-built operating systems that can make a standard physical server exhibit the properties of a storage device. We can format a standard x86 server with these specialised operating systems, to create a storage solution out of this general-purpose server. Depending on the software, the storage solution can exhibit the behaviour of SAN block storage, NAS file storage or even object storage. Ceph, for example, can create all three types of storage out of the same server. In these cases, the disk devices attached to the servers operate as the storage blocks. The disks can be standard direct attached storage (like the one in your laptop) or a number of disks daisy-chained to your server system.
The software defined solutions can be extended and controlled through the software libraries and APIs that they expose. Typically available on a REST API and with UNIX/Linux based operating systems, these are easy to integrate with other orchestration solutions. For example, OpenStack exposes Cinder for block storage, Manila for file storage and Swift for object storage. An application can either run management commands on the natively supported CLI shell or the native/orchestration APIs.
4. The Compute-as-a-Service API
Compute-as-a-Service is the ability to serve the bare metal, the virtual machine or the containers in an on-demand basis over API endpoints or through self-service portals. It is built mostly on top of virtualisation or containerisation platforms. A Compute-as-a-Service model may or may not be a cloud solution. Hypervisors that can be managed through a self-service portal and API endpoint can be considered as Compute-as-a-Service. For example, a VMware vSphere implementation with a self-service portal and API endpoint is such a solution. Similarly, on the containerisation front, the container orchestration tools like Kubernetes are not a cloud solution but a good example of Compute-as-a-Service with an API and self-service GUI. Typical cloud solutions that allow one to provision virtual machines (like AWS EC2), containers (like AWS ECS) and in some cases even physical machines (like Softlayer), are examples of compute power provided as a service.
5. The infrastructure orchestration API
Infrastructure orchestration is the Infrastructure-as-a-Service cloud solution that can offer infrastructure components on demand, as a service, over an API. In case of infrastructure orchestration, it is not only about VM provisioning. It is about orchestrating various infrastructure components in storage, networking and compute, in an optimised manner. This helps provisioning and de-provisioning of components as per the demands of business. The cloud solutions typically offer control over such orchestration through some programming language to configure orchestration logics. For example, AWS provides cloud formation and OpenStack provides the Heat language for this. However, nowadays, in a multi-cloud strategy, new languages have come up for hybrid cloud orchestration. Terraform and Cloudify are two prime examples.
6. Configuration management as code and API
In IT, change and configuration management are the traditional ITIL processes that track every change in the configuration of systems. Typically, the process is reactive, whereby change is performed on the systems and then recorded in a central configuration management database.
However, currently, changes are first recorded in a database as per the need. Then these changes are applied to systems using automation tools to bring them to the desired state, as recorded in the database. This new-age model is known as the desired state of configuration management. cfEngine, Puppet, Chef, etc, are well known configuration management tools in the market.
These tools configure the target systems as per the desired configuration mentioned in the files. Since this is done by writing text files with a syntax and some logical constructs, these files are known to be infrastructure configuration codes. Using such code to manage infrastructure is known as ‘configuration management as code’ or ‘infrastructure as code’. These tools typically expose an API endpoint to create the desired configuration on target servers.
7. The Platform-as-a-Service API
Platform-as-a-Service (PaaS) solutions provide the platform components such as application, middleware or database, on demand. These solutions hide the complexity of the infrastructure at the backend. At the frontend, they expose a simple GUI or API to provision, de-provision or scale platforms for the application to run.
So instead of saying, “I need a Linux server for installing MySQL,” the developer will just have to say, “I need a MySQL instance.” In a PaaS solution, deploying a database means it will deploy a new VM, install the required software, open up firewall ports and also provision the other dependencies needed to access the database. It does all of this at the backend, abstracting the complexities from the developers, who only need to ask for the database instance, to get the details. Hence developers can focus on building applications without worrying about the underlying complexities.
The APIs of a PaaS solution can be used by the application to scale itself. Most of the PaaS solutions are based on containers which can run on any VM, be it within the data centre or in the public cloud. So the PaaS solutions can stretch across private and public cloud environments. Therefore, in the case of PaaS, cloudbursting is much easier than in IaaS. (Cloudbursting is the process of scaling out from private cloud to public cloud resources as per the load/demand on the application.)
8. DevOps orchestration and the API
DevOps can be defined in two ways:
1. It is a new name for automating the release management process that makes developers and the operations team work together.
2. The operations team manages operations by writing code, just like developers.
In DevOps, the application release management and application’s resource demand management is of primary importance.
The traditional workflow tools like Jenkins have a new role of becoming orchestrators of all data centre components in an automated workflow. In this age of DevOps and ADDC, every product vendor releases the Jenkins plugins for their products as soon as it releases the product or its updates. This enables all of these ADDC components and the API endpoints to be orchestrated through a tool like Jenkins.
Apart from Jenkins, open source configuration management automation tools like Puppet and Chef can also easily integrate with other layers of ADDC to create a set of programmatic orchestration jobs exposed over API calls to run these jobs. These jobs can be run from API invocation, to orchestrate the data centre through the orchestration of all other API layers.
ADDC is therefore an approach to combining various independent technology solutions to create API endpoints for everything in a data centre. The benefit is the programmability of the entire data centre. Theoretically, a program can be written to do all the jobs that are done by people in a traditional data centre. That is the automation nirvana which will be absolutely free of human errors and the most optimised process, because it will remove human elements from the data centre management completely. However, such a holistic app has not arrived yet. Various new age tools are coming up every day to take advantage of these APIs for specific use cases. So, once the data centre has been converted into an ADDC, it is only left to the developers’ imagination as to how much can be automated – there is nothing that cannot be done.
Coming back to what we started with – the move towards architectures like ADDC is surely going to impact jobs as humans will be replaced by automation. However, there is the opportunity to become automation experts instead of sticking to manual labour profiles. Hence, in order to combat the new automation job role demands in the market, one needs to specialise in one or some of these ADDC building blocks to stay relevant in this transforming market. Hopefully, this article will help you build a mind map of all the domains you can try to skill up for.
















{kind=link}