


























































Machine learning is a fascinating study. If you are a beginner or simply curious about machine learning, this article covers the basics for you.
Machine learning is a set of methods by which computers make decisions autonomously. Using certain techniques, computers make decisions by considering or detecting patterns in past records and then predicting future occurrences. Different types of predictions are possible, such as about weather conditions and house prices. Apart from predictions, machines have learnt how to recognise faces in photographs, and even filter out email spam. Google, Yahoo, etc, use machine learning to detect spam emails. Machine learning is widely implemented across all types of industries. If programming is used to achieve automation, then we can say that machine learning is used to automate the process of automation.
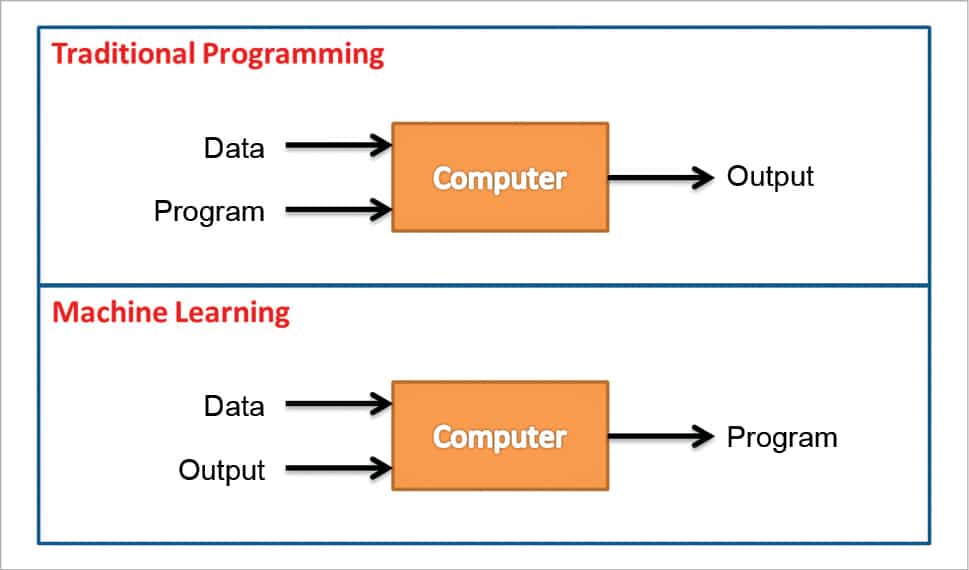
In traditional programming, we use data and programs on computers to produce the output, whereas in machine learning, data and output is run on the computer to produce a program. We can compare machine learning with farming or gardening, where seeds –> algorithms, nutrients –> data, and the gardener and plants –> programs.
We can say machine learning enables computers to learn to perform tasks even though they have not been explicitly programmed to do so. Machine learning systems crawl through the data to find the patterns and when found, adjust the program’s actions accordingly. With the help of pattern recognition and computational learning theory, one can study and develop algorithms (which can be built by learning from the sets of available data), on the basis of which the computer takes decisions. These algorithms are driven by building a model from sample records. These models are used in developing decision trees, through which the system takes all the decisions. Machine learning programs are also structured in such a way that when exposed to new data, they learn and improve over time.
Implementing machine learning
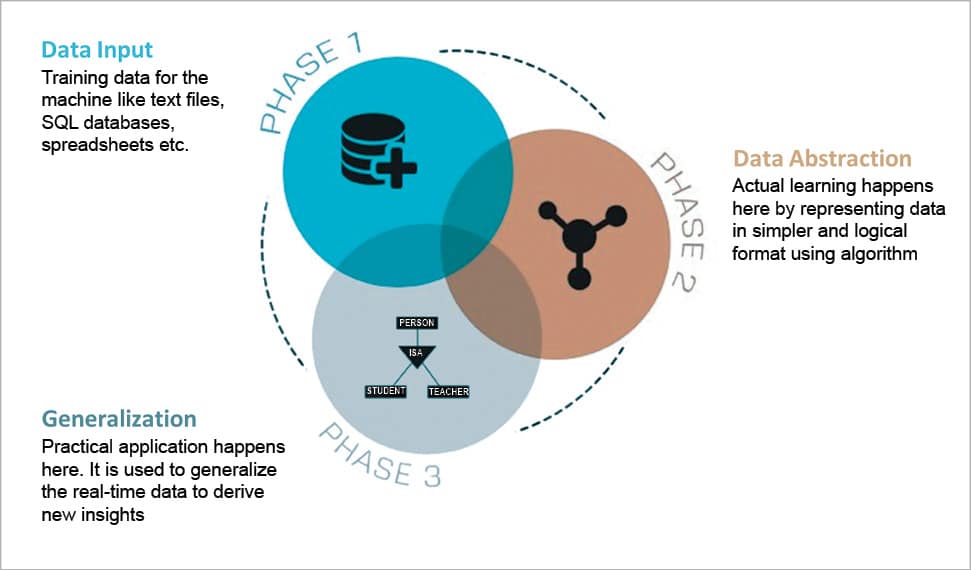
Before we understand how machine learning is implemented in real life, let’s look at how machines are taught. The process of teaching machines is divided into three steps.
1 Data input: Text files, spreadsheets or SQL databases are fed as input to machines. This is called the training data for a machine.
2 Data abstraction: Data is structured using algorithms to represent it in simpler and more logical formats. Elementary learning is performed in this phase.
3. Generalisation: An abstract of the data is used as input to develop the insights. Practical application happens at this stage.
The success of the machine depends on two things:
- How well the generalisation of abstraction data happens.
- The accuracy of machines when translating their learning into practical usage for predicting the future set of actions.
In this process, every stage helps to construct a better version of the machine.
Now let’s look at how we utilise the machine in real life. Before letting a machine perform any unsupervised task, the five steps listed below need to be followed.
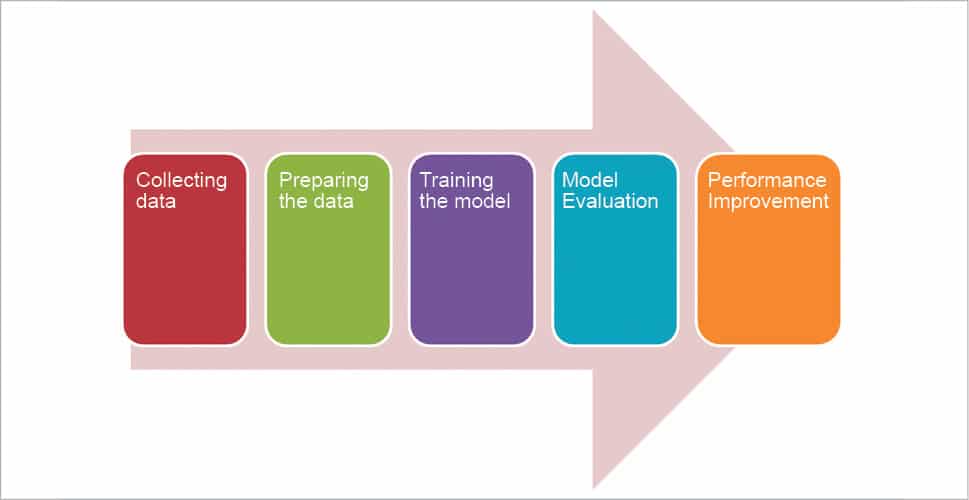
Collecting data: Data plays a vital role in the machine learning process. It can be from various sources and formats like Excel, Access, text files, etc. The higher the quality and quantity of the data, the better the machine learns. This is the base for future learning.
Preparing the data: After collecting data, its quality must be checked and unnecessary noise and disturbances that are not of interest should be eliminated from the data. We need to take steps to fix issues such as missing data and the treatment of outliers.
Training the model: The appropriate algorithm is selected in this step and the data is represented in the form of a model. The cleaned data is divided into training data and testing data. The training data is used to develop the data model, while the testing data is used as reference to ensure that the model has been trained well to produce accurate results.
Model evaluation: In this step, the accuracy and precision of the chosen algorithm is ensured based on the results obtained using the test data. This step is used to evaluate the choice of the algorithm.
Performance improvement: If the results are not satisfactory, then a different model can be chosen to implement the same or more variables are introduced to increase efficiency.
Types of machine learning algorithms
Machine learning algorithms have been classified into three major categories.
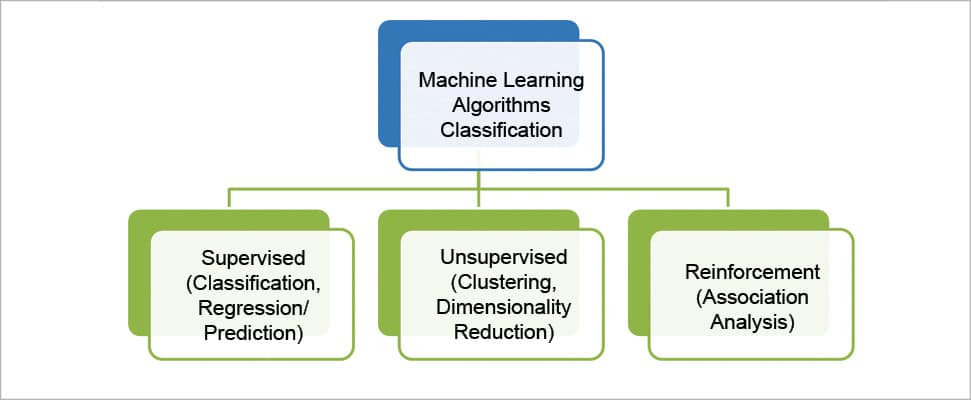
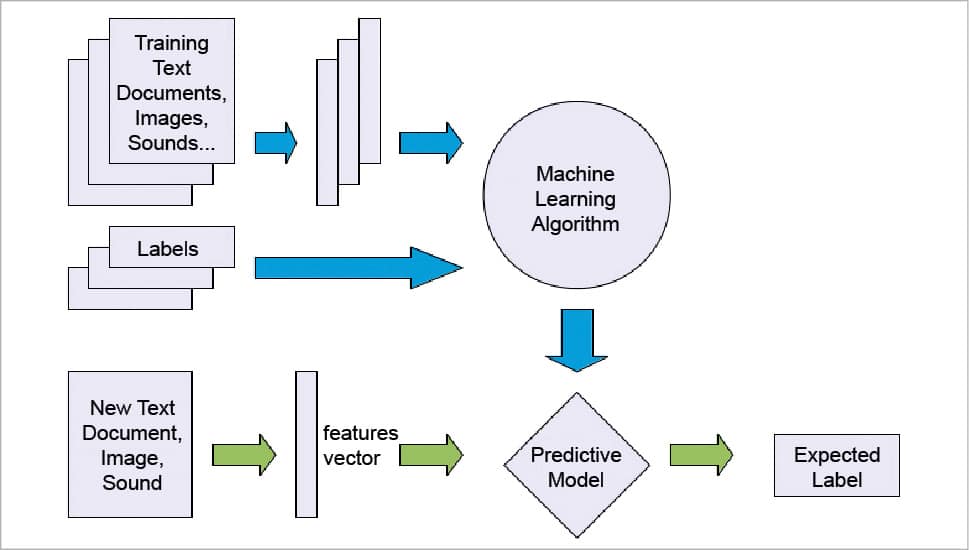
Supervised learning: Supervised learning is the most commonly used. In this type of learning, algorithms produce a function which predicts the future outcome based on the input given (historical data). The name itself suggests that it generates output in a supervised fashion. So these predictive models are given instructions on what needs to be learnt and how it is to be learnt. Until the model achieves some acceptable level of efficiency or accuracy, it iterates over the training data.
To illustrate this method, we can use the algorithm for sorting apples and mangoes from a basket full of fruits. Here we know how we can identify the fruits based on their colour, shape, size, etc.
Some of the algorithms we can use here are the neural network, nearest neighbour, Naïve Bayes, decision trees and regression.
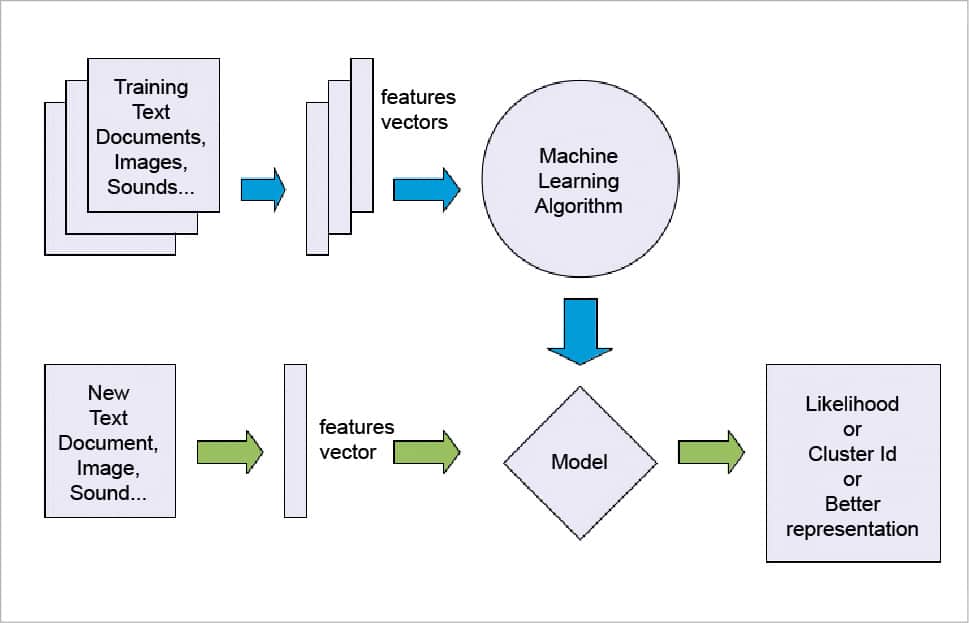
Unsupervised learning: The objective of unsupervised learning algorithms is to represent the hidden structure of the data set in order to learn more about the data. Here, we only have input data with no corresponding output variables. Unsupervised learning algorithms develop the descriptive models, which approach the problems irrespective of the knowledge of the results. So it is left to the system to find out the pattern in the available inputs, in order to discover and predict the output. From many possible hypotheses, the optimal one is used to find the output.
Sorting apples and mangoes from a basket full of fruits can be done using unsupervised learning too. But this time the machine is not aware about the differentiating features of the fruits such as colour, shape, size, etc. We need to find similar features of the fruits and sort them accordingly.
Some of the algorithms we can use here are the K-means clustering algorithm and hierarchical clustering.
Reinforcement learning: In this learning method, ideas and experiences supplement each other and are also linked with each other. Here, the machine trains itself based on the experiences it has had and applies that knowledge to solving problems. This saves a lot of time, as very little human interaction is required in this type of learning. It is also called the trial-error or association analysis technique, whereby the machine learns from its past experiences and applies its best knowledge to make decisions. For example, a doctor with many years of experience links a patient’s symptoms to the illness based on that experience. So whenever a new patient comes, he uses his experience to diagnose the illness of the patient.
Some of the algorithms we can use here are the Apriori algorithm and the Markov decision process.
Machine learning applications
Machine learning has ample applications in practically every domain. Some major domains in which it plays a vital role are shown in Figure 7.
Banking and financial services: Machine learning plays an important role in identifying customers for credit card offers. It also evaluates the risks involved with those offers. And it can even predict which customers are most likely to be defaulters in repaying loans or credit card bills.
Healthcare: Machine learning is used to diagnose fatal illnesses from the symptoms of patients, by comparing them with the history of patients with a similar medical history.
Retail: Machine learning helps to spot the products that sell. It can differentiate between the fast selling products and the rest. That analysis helps retailers to increase or decrease the stocks of their products. It can also be used to recognise which product combinations can work wonders. Amazon, Flipkart and Walmart all use machine learning to generate more business.
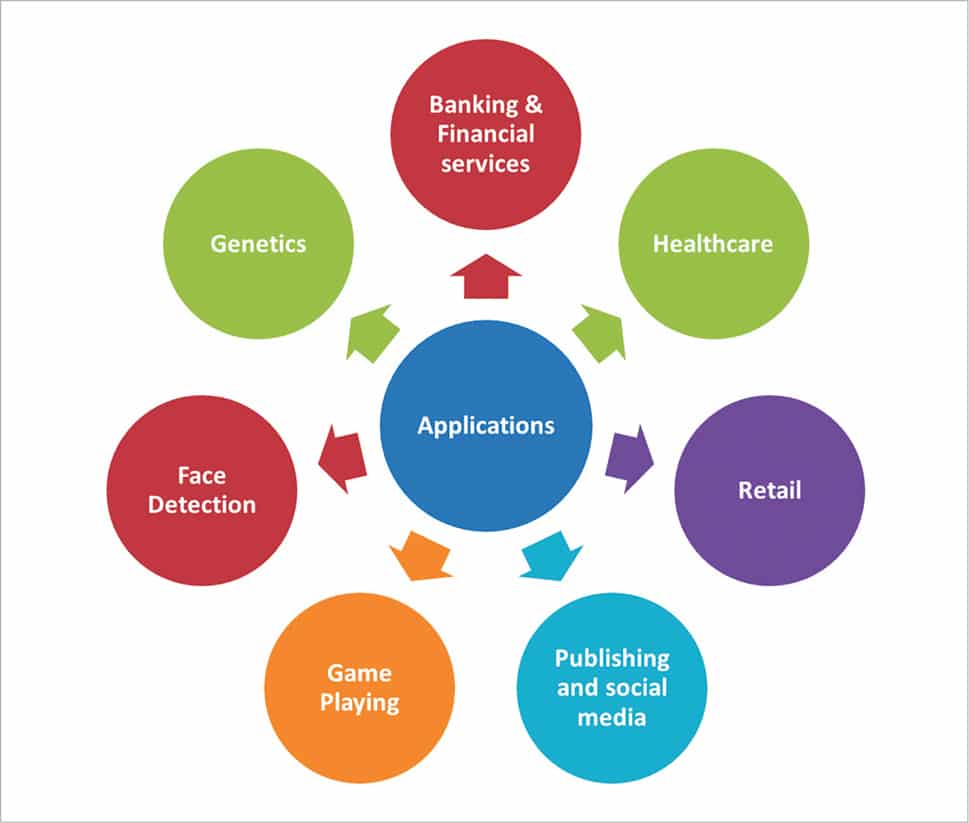
Publishing and social media: Some publishing firms use machine learning to address the queries and retrieve documents for their users based on their requirements and preferences. Machine learning is also used to narrow down the search results and news feeds. Google and Facebook are the best examples of companies that use machine learning. Facebook also uses machine learning to suggest friends.
Games: Machine learning helps to formulate strategies for a game that requires the internal decision tree style of thinking and effective situational awareness. For example, we can build intelligence bots that learn as they play computer games.
Face detection/recognition: The most common example of face detection is this feature being widely available in smartphone cameras. Facial recognition has even evolved to the extent that the camera can figure out when to click – for instance, only when there is a smile on the face being photographed. Face recognition is used in Facebook to automatically tag people in photos. It’s machine learning that has taught systems to detect a particular individual from a group photo.
Genetics: Machine learning helps to identify the genes associated with any particular disease.
Machine learning tools
There are enough open source tools or frameworks available to implement machine learning on a system. One can choose any, based on personal preferences for a specific language or environment.
Shogun: Shogun is one of the oldest machine learning libraries available in the market. It provides a wide range of efficient machine learning processes. It supports many languages such as Python, Octave, R, Java/ Scala, Lua, C#, Ruby, etc, and platforms such as Linux/UNIX, MacOS and Windows. It is easy to use, and is quite fast at compilation and execution.
Weka: Weka is data mining software that has a collection of machine learning algorithms to mine the data. These algorithms can be applied directly to the data or called from the Java code.
Weka is a collection of tools for:
- Regression
- Clustering
- Association rules
- Data pre-processing
- Classification
- Visualisation
Apache Mahout: Apache Mahout is a free and open source project. It is used to build an environment to quickly create scalable machine learning algorithms for fields such as collaborative filtering, clustering and classification. It also supports Java libraries and Java collections for various kinds of mathematical operations.
TensorFlow: TensorFlow performs numerical computations using data flow graphs. It performs optimisations very well. It supports Python or C++, is highly flexible and portable, and also has diverse language options.
CUDA-Convnet: CUDA-Convnet is a machine learning library widely used for neural network applications. It has been developed in C++ and can even be used by those who prefer Python over C++. The resulting neural nets obtained as output from this library can be saved as Python-pickled objects, and those objects can be accessed from Python.
H2O: This is an open source machine learning as well as deep learning framework. It is developed using Java, Python and R, and it is used to control training due to its powerful graphic interface. H2O’s algorithms are mainly used for business processes like fraud or trend predictions.
Languages that support machine learning
The languages given below support the implementation of the machine language:
- MATLAB
- R
- Python
- Java
But for a non-programmer, Weka is highly recommended when working with machine learning algorithms.
Advantages and challenges
The advantages of machine learning are:
- Machine learning helps the system to decode based on the training data provided in the dynamic or undermined state.
- It can handle multi-dimensional, multi-variety data, and can extract implicit relationships within large data sets in a dynamic, complex and chaotic environment.
- It saves a lot of time by tweaking, adding, or dropping different aspects of an algorithm to better structure the data.
- It also uses continuous quality improvement for any large or complex process.
- There are multiple iterations that are done to deliver the highest level of accuracy in the final model.
- Machine learning allows easy application and comfortable adjustment of parameters to improve classification performance.
The challenges of machine learning are as follows:
- A common challenge is the collection of relevant data. Once the data is available, it has to be pre-processed depending on the requirements of the specific algorithm used, which has a serious effect on the final results.
- Machine learning techniques are such that it is difficult to optimise non-differentiable, discontinuous loss functions. Discontinuous loss functions are important in cases such as sparse representations. Non-differentiable loss functions are approximated by smooth loss functions without much loss in sparsity.
- It is not guaranteed that machine learning algorithms will always work in every possible case. It requires some awareness about the problem and also some experience in choosing the right machine learning algorithm.
- Collection of such large amounts of data can sometimes be an unmanageable and unwieldy task.















This is a good article