






























































This article gives a quick overview of Darknet and the way it works.
Artificial Neural Networks (ANNs) are a key area of research and application in the field of artificial intelligence. ANNs simulate the algorithms, techniques and strategies adopted by the human brain to process data and information. Robotics, self-driving vehicles, speech recognition, medical image analytics, bioinformatics, natural language processing (NLP), real-time image processing and many other applications make use of such algorithms.
Nowadays, deep learning is widely used for advanced applications of image and video processing with high performance levels. Deep learning neural networks make use of the higher levels of accuracy in prediction and dynamic data analysis, and are now being widely used as an implementation of ANNs.
Free and open source libraries for deep neural networks
Table 1 lists the key libraries and frameworks for implementing deep learning and advanced neural networks.
| Library | URL |
| Darknet | pjreddie.com/darknet/ |
| TensorFlow | tensorflow.org |
| Keras | keras.io |
| Caffe | caffe.berkeleyvision.org/ |
| PyTorch | pytorch.org |
| MXNet | mxnet.apache.org |
| CNTK | cntk.ai/ |
| Fast.ai | fast.ai/ |
| Deeplearning4j | deeplearning4j.org/ |
| Theano | github.com/Theano/Theano |
| PaddlePaddle | github.com/PaddlePaddle/Paddle |
| Sonnet | github.com/deepmind/sonnet |
| Dlib | dlib.net |
| Chainer | chainer.org |
| BigDL | bigdl-project.github.io/ |
| Dynet | dynet.io/ |
Table 1
Darknet: An open source platform for neural networks in C
Darknet is a high performance open source framework for the implementation of neural networks. Written in C and CUDA, it can be integrated with CPUs and GPUs.
Advanced implementations of deep neural networks can be done using Darknet. These implementations include You Only Look Once (YOLO) for real-time object detection, ImageNet classification, recurrent neural networks (RNNs), and many others.

Installation and working with Darknet
Darknet can be installed directly with easy to use instructions. It needs two dependencies, both of which are optional based on the implementation scenario.
Dependency 1: OpenCV for multiple types of images
Dependency 2: CUDA for GPU based computation
The base environment of Darknet can be installed using the following instructions:
Clone: git clone https://github.com/pjreddie/darknet.git Move to Directory: cd darknet make Instruction: make
Once all the instructions are executed successfully, you can run the environment using the following command:
./darknet
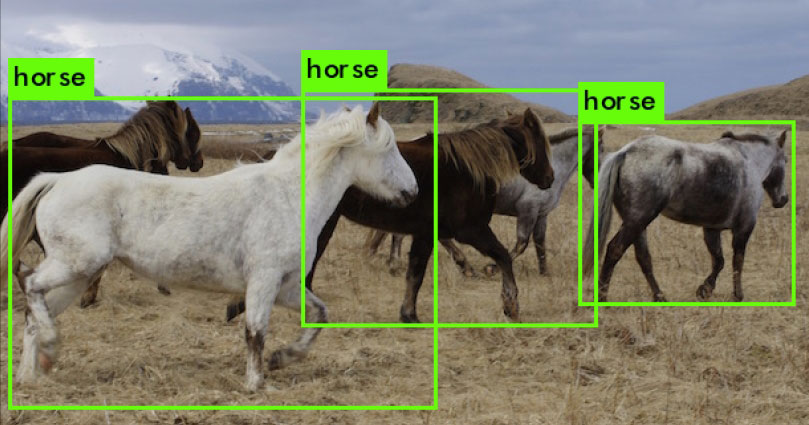
Real-time object detection using a pre-trained model
YOLO is one of the powerful methods of real-time object detection with integration of advanced deep learning. It makes use of convolutional neural networks (CNN) for the prediction of objects by using advanced mathematical formulations of image processing.
To work with real-time object detection, the data set in which the weights of pre-trained models are available is imported first. This is done so that the images of all real world objects can be mapped with the implementation for prediction. The weights of pre-trained models are downloaded as follows:
wget https://pjreddie.com/media/files/yolov3.weights
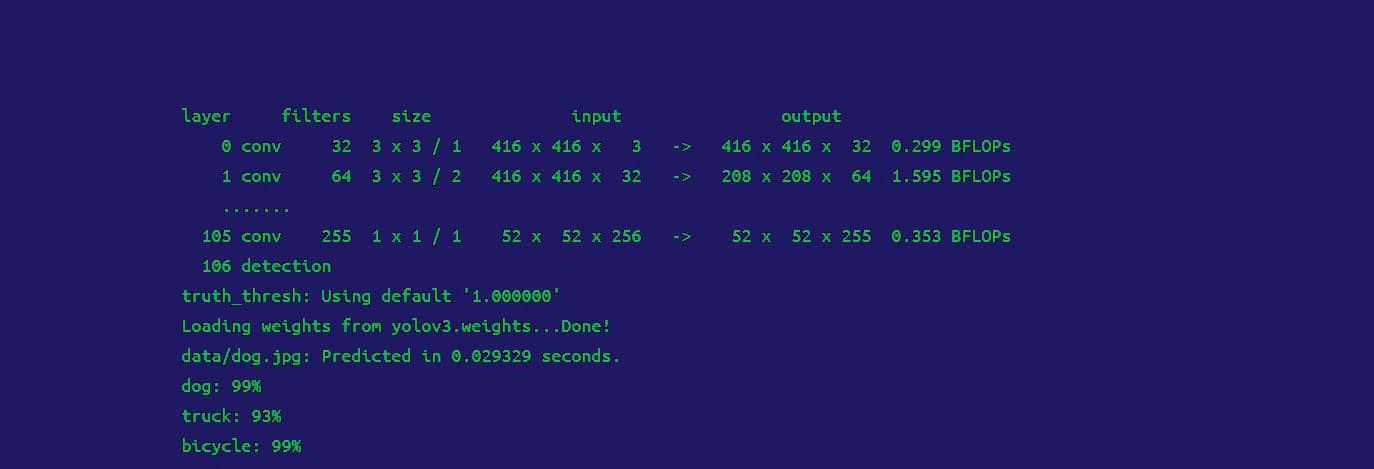
Next, the detection is done, specifying the image to be identified:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
The output is generated with the dynamic fetching of the objects, with a label that marks their actual identity (Figures 2 and 3).

For multiple images, the same approach can be implemented with effectual predictions. If there are multiple objects that have the same pattern in single or multiple images, this approach works effectively.
There is a huge scope for research and development in the domain of deep learning, including the development and deployment of drones for real-time object mapping and recognition.




















{kind=link}