

This article looks at the key considerations that are critical to the success of delivering low latency applications in the cloud. It also outlines how to build an interactive low latency application.
“Productivity is never an accident. It is always the result of a commitment to excellence, intelligent planning, and focused effort,” said Paul J. Meyer, motivational speaker.
This was meant in the context of humans. With the evolution of technology and machines taking over mundane repetitive tasks from humans, this statement applies to machines as well today. Acceleration in the pace of change has led users to believe it’s about time technology delivers instant response to requests, especially in the interactive world of entertainment (such as online video games like ‘World of Warcraft’ or ‘Fortress’, where hundreds of users participate simultaneously in voice conversations).
Edge computing has been around a long time; however, what it means to different industries and organisations has evolved over time differently. Cloud native computing has brought yet another meaning to the edge as a resource belonging to cloud service providers that can be leveraged on demand. Persistent efforts in the field of artificial intelligence (AI) over the last 50+ years have made it evolve from a scalable efficiency model to a scalable learning model by combining it with machine learning (ML).
The Internet of Things (IoT) has led to yet another increase in the demand for edge computing. The massive data that connected devices create by communicating with each other over the Internet needs to be processed efficiently in order to be used properly. This has led to demand for low latency applications in the cloud.
Business considerations of low latency applications
While designing an application, business considerations must be the topmost priority in ensuring successful deployment of the solution. Here are the key business considerations that are critical to the success of delivering low latency applications.
- Localised real-time data processing will be efficient and deliver faster data driven decisions with the use of AI and ML.
- Security at the edge, as well as data encryption at rest and in transit, along with site key management for private and public key encryption will enable always encrypted communication.
- Low operational costs with agility, as bandwidth and throughput concerns typically are addressed with solutions that cost significant resources financially or otherwise.
- Optimal affordable storage at the edge and also at the hub as connected devices generate large amounts of data on a daily basis. Data analysis must be optimised at every point.
Technical considerations of low latency applications
A lack of understanding or planning of technical considerations leads to the vast majority of project failures. Let’s look at some critical technical considerations that are important in the design and development of low latency applications.
- Infrastructure deployment and configuration management for the edge can be challenging. Hardware and software stack decisions must be made carefully ensuring the deployed architecture meets the expected performance considerations.
- Edge network visibility must be built beyond real-time traffic monitoring to include predictive and proactive analytics, leveraging AI and ML to create insights into edge performance.
- Connectivity at the edge for set application configurations should be designed for latency, bandwidth, throughput, and quality of service to ensure that typical outer edge communication issues with centralised and distributed systems are managed. Evolution of 5G has made this journey a little smoother.
A low latency application for an interactive experience
Now that we are through with the fundamentals, let’s look at how a low latency application is built in an example use case. The application we are going to build is an interactive experience where the human and machine interaction is expected to occur in real-time or, at least, the human interacting with the machine must not feel a lag in response. One could argue that we already have this in Alexa, Google Assistant, etc. Yes, we do for end consumers for specific search-based responses. Let’s look at a reference architecture for an interactive experience application that an organisation tailors for its own end users.
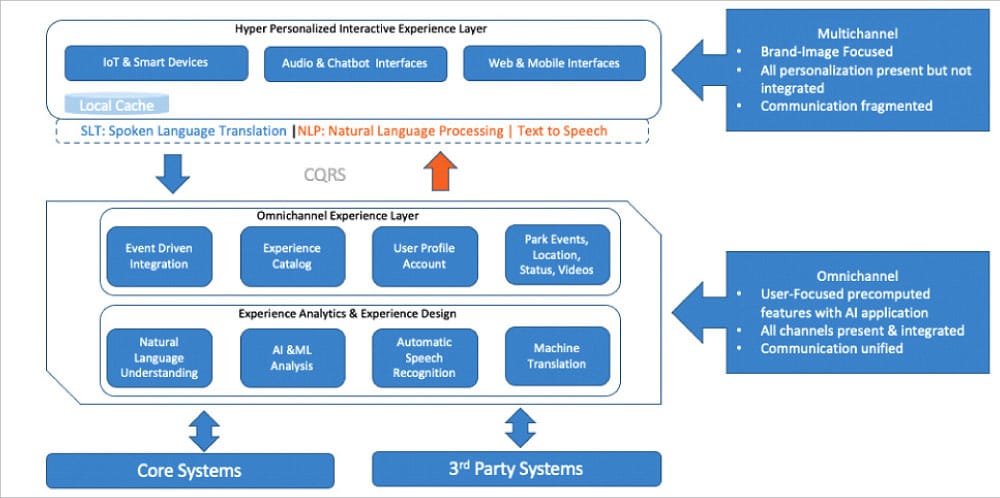
An interactive experience application requires near-real-time responses. This can be done by applying a multichannel framework at the experience layer to build the organisation’s brand image. End user personalisation in a fragmented communication allows for quick consumption and processing of data, limiting any latency aspects in the last step (commonly known as last mile delivery of content). Machine learning models are built with ONNX Runtime, that’s built on the Open Neural Network Exchange (ONNX) open standard which has a JavaScript library. Later, the data required is serialised with open source tools like MLeap or equivalents of it, which is deserialised back for MLeap runtime to power real-time API services in the omnichannel experience layer and beyond.
The middle services layer is designed with an omnichannel framework, where end user focused data is precomputed with the support of ML learnings using open source tools like Spark, Scikit-learn or TensorFlow.
The data is then exported to MLeapBundle, which can be deployed at the edge data centre. This approach reduces any network latency concerns typical data centre connectivity will have, allowing for enterprise grade processing power for real-time machine learning.
The final step in request processing is to interface with core and third party systems of the organisation for the data necessary in experience analytics. This data runs in a typical data centre or in cloud native services. The end-to-end low latency application can be developed using proven open source tools.
The technical architecture shown in Figure 2 is a reference implementation of a low latency application that could be developed for an interactive experience for various common use cases. Each of the open source tools selected has many alternatives as well. Depending on the capability and functional need of the solution, the appropriate tools may be swapped to build the right-sized implementation. Links to each of the tools used, with a brief on their purpose, are given in the References at the end of this article.
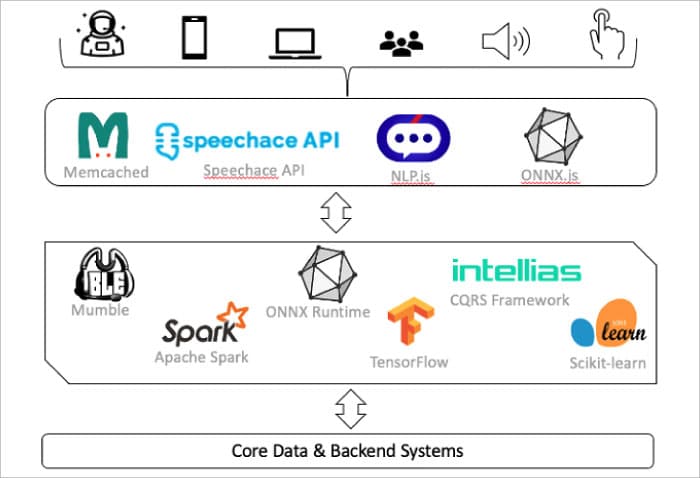
Most popular cloud service providers are embracing advancements in low latency solutions. They either offer a cloud native offering that’s wrapped around familiar open source tools (e.g., Apache Spark) or they build their own, providing developers the opportunity to select the right tools that are cost-effective, but meet the expectations of low latency and good performance.
Deploying a scalable low latency solution that meets the needs of an organisation can enable it to deliver better products and services to its customers. Though there is considerable effort involved in deploying scalable low latency solutions the right way, the investment and risks are worth it.



{kind=link}